データモデリング手法
これは、PostgreSQL から ClickHouse への移行に関するガイドの パート 3 です。実用的な例を用いて、PostgreSQL から移行する場合に ClickHouse でどのようにデータをモデリングすればよいかを解説します。
Postgres から移行するユーザーには、ClickHouse におけるデータモデリングのガイドを読むことをお勧めします。このガイドでは、同じ Stack Overflow データセットを使用し、ClickHouse の機能を活用した複数のアプローチを紹介します。
ClickHouse における主キー(オーダリングキー)
OLTP データベースから移行してくるユーザーは、ClickHouse における同等の概念を探すことがよくあります。ClickHouse が PRIMARY KEY 構文をサポートしていることに気づくと、元の OLTP データベースと同じキーを使ってテーブルスキーマを定義したくなるかもしれませんが、これは推奨されません。
ClickHouse の主キーは何が違うのか
OLTP の主キーを ClickHouse で使用することが適切でない理由を理解するには、まず ClickHouse のインデックスの基本を理解する必要があります。ここでは比較対象として Postgres を使用しますが、一般的な概念は他の OLTP データベースにも当てはまります。
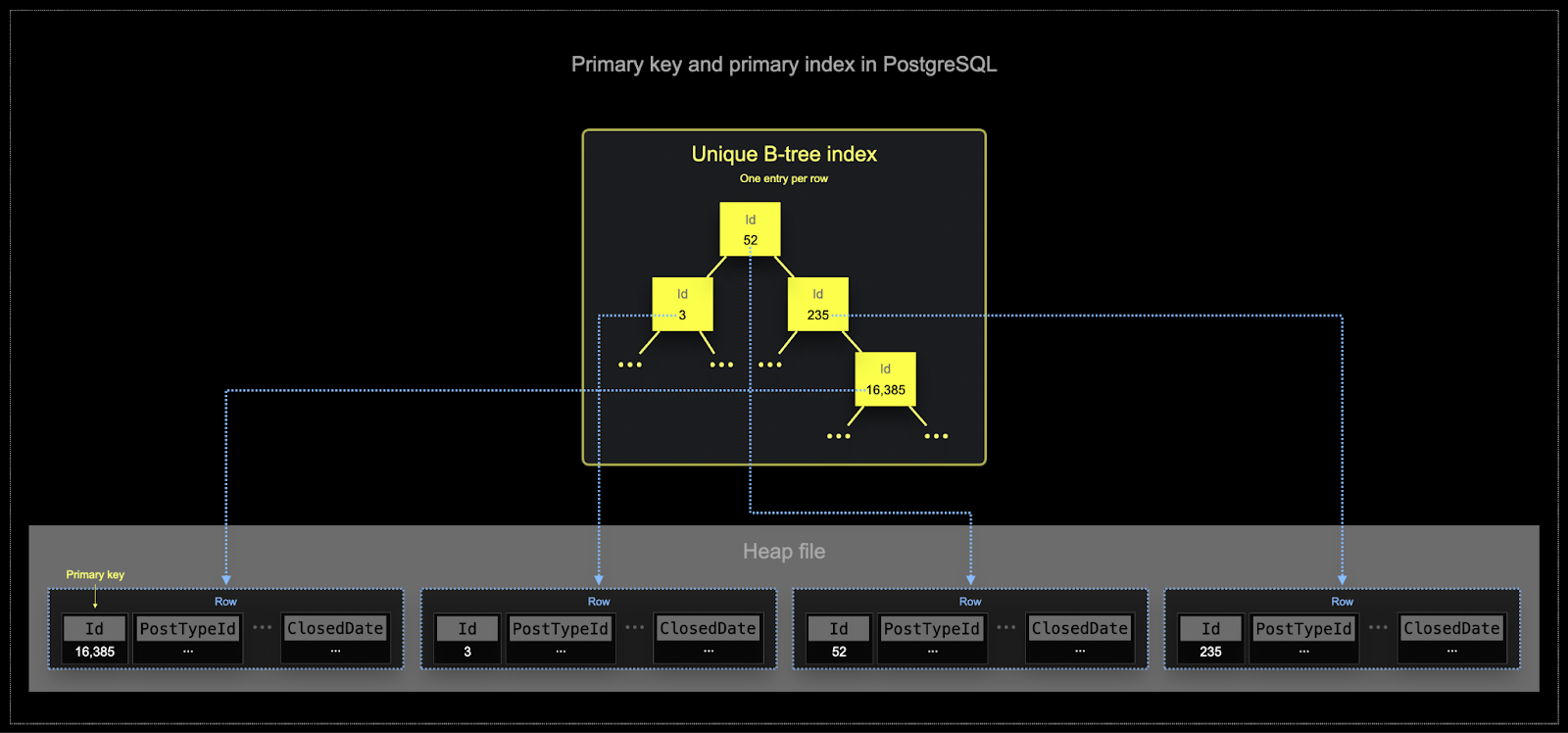
- Postgres の主キーは、定義上、行ごとに一意です。B-tree 構造を使用することで、このキーによる単一行の効率的な検索が可能になります。ClickHouse でも単一行の値検索に最適化することはできますが、分析ワークロードでは通常、多数の行に対して少数の列を読み取る必要があります。フィルタは、集計が実行される行のサブセットを特定する必要がある場合がほとんどです。
- メモリとディスクの効率性は、ClickHouse がよく利用されるスケールにおいて極めて重要です。データは「パーツ」と呼ばれるチャンク単位で ClickHouse のテーブルに書き込まれ、バックグラウンドでパーツをマージするためのルールが適用されます。ClickHouse では、各パーツはそれぞれ独自のプライマリインデックスを持ちます。パーツがマージされると、マージされたパーツのプライマリインデックスもマージされます。Postgres とは異なり、これらのインデックスは行ごとに構築されるわけではありません。代わりに、1 つのパーツのプライマリインデックスは、行のグループごとに 1 つのインデックスエントリを持ちます。この手法はスパースインデックスと呼ばれます。
- スパースインデックスが可能なのは、ClickHouse が各パーツの行を、指定されたキーでソートされた状態でディスクに保存するためです。単一行を直接特定する(B-Tree ベースのインデックスのような)代わりに、スパースプライマリインデックスは、インデックスエントリに対する二分探索を通じて、クエリにマッチする可能性のある行グループを高速に特定します。特定されたマッチ候補の行グループは、その後並列に ClickHouse エンジンへストリーミングされ、一致する行が探索されます。このインデックス設計により、プライマリインデックスは小さく(主メモリに完全に収まる)、それでいてクエリ実行時間を大幅に短縮できます。特に、データ分析ユースケースで典型的なレンジクエリに対して有効です。
詳細については、この詳細ガイドを参照してください。
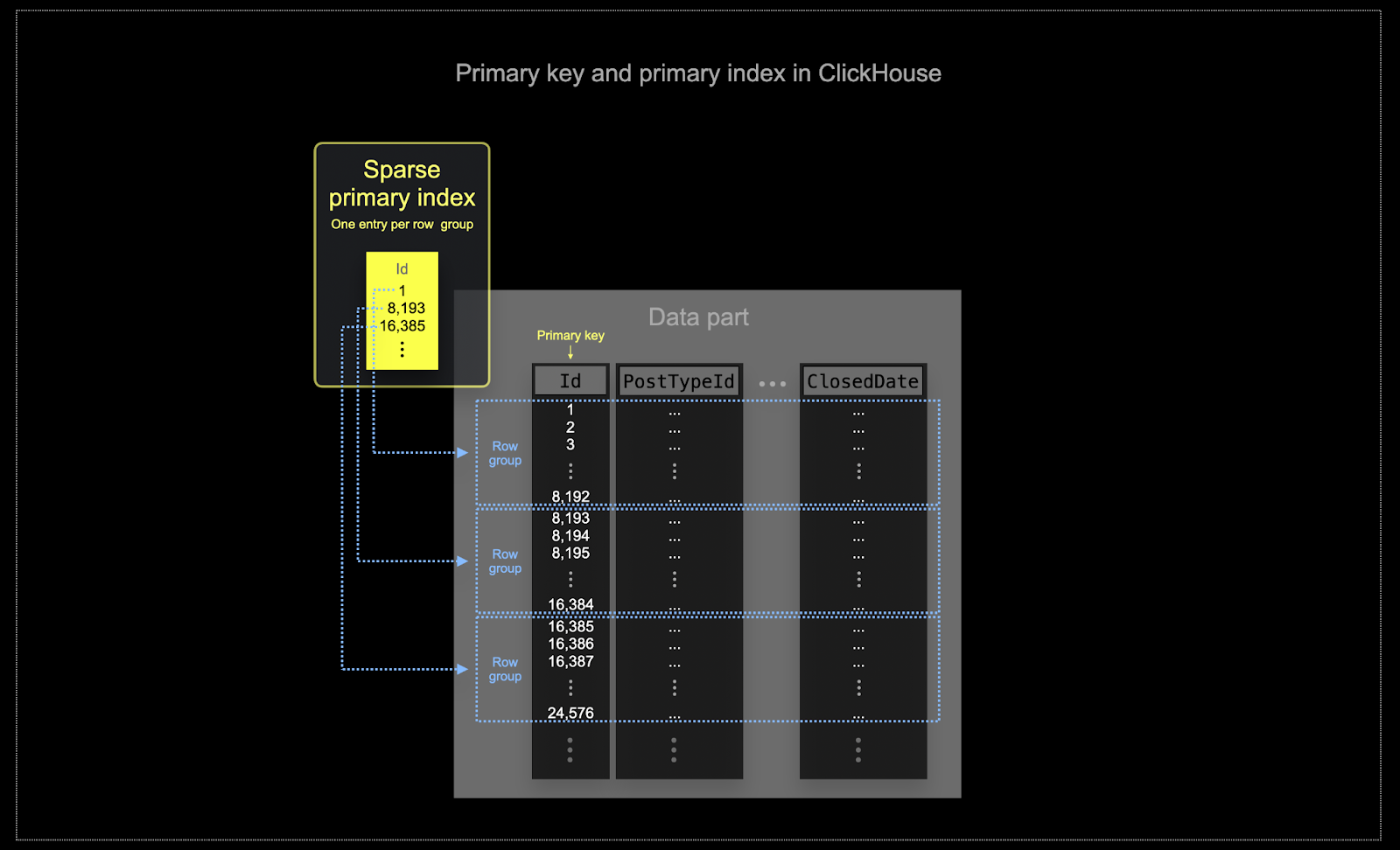
ClickHouse で選択されたキーは、インデックスだけでなく、データがディスクに書き込まれる順序も決定します。このため、圧縮率に大きな影響を与え、それがクエリパフォーマンスにも影響します。ほとんどの列の値が連続した順序で書き込まれるようなオーダリングキーを選ぶと、選択した圧縮アルゴリズム(およびコーデック)がデータをより効果的に圧縮できるようになります。
テーブル内のすべての列は、指定されたオーダリングキーの値に基づいてソートされます。これは、その列がキー自体に含まれているかどうかに関係ありません。たとえば、
CreationDateをキーとして使用した場合、他のすべての列の値の並び順は、CreationDate列の値の並び順に対応します。複数のオーダリングキーを指定することもできます。この場合、SELECTクエリのORDER BY句と同じセマンティクスでソートされます。
オーダリングキーの選択
オーダリングキーを選択する際の考慮事項と手順については、posts テーブルを例にとった解説をこちらで参照できます。
CDC を用いたリアルタイムレプリケーションを利用する場合は、追加の制約を考慮する必要があります。CDC でオーダリングキーをカスタマイズする手法については、このドキュメントを参照してください。
パーティション
Postgres ユーザーであれば、テーブルをより小さく扱いやすい単位であるパーティションに分割することで、大規模データベースのパフォーマンスと管理性を向上させるテーブルパーティショニングの概念にはなじみがあるはずです。このパーティショニングは、指定した列(例: 日付)の範囲や、定義済みリスト、あるいはキーに対するハッシュを用いることで実現できます。これにより、管理者は日付範囲や地理的な位置などの特定の条件に基づいてデータを整理できます。パーティショニングは、パーティションプルーニングや効率的なインデックス作成による高速なデータアクセスを可能にすることで、クエリ性能の向上に寄与します。また、テーブル全体ではなく個々のパーティション単位で操作できるため、バックアップやデータ削除といったメンテナンス作業の効率化にもつながります。さらに、負荷を複数のパーティションに分散させることで、PostgreSQL データベースのスケーラビリティを大幅に向上させることができます。
ClickHouse では、パーティショニングはテーブルを最初に定義する際に PARTITION BY 句で指定します。この句には任意の列に対する SQL 式を含めることができ、その評価結果に基づいて各行が送られるパーティションが決定されます。
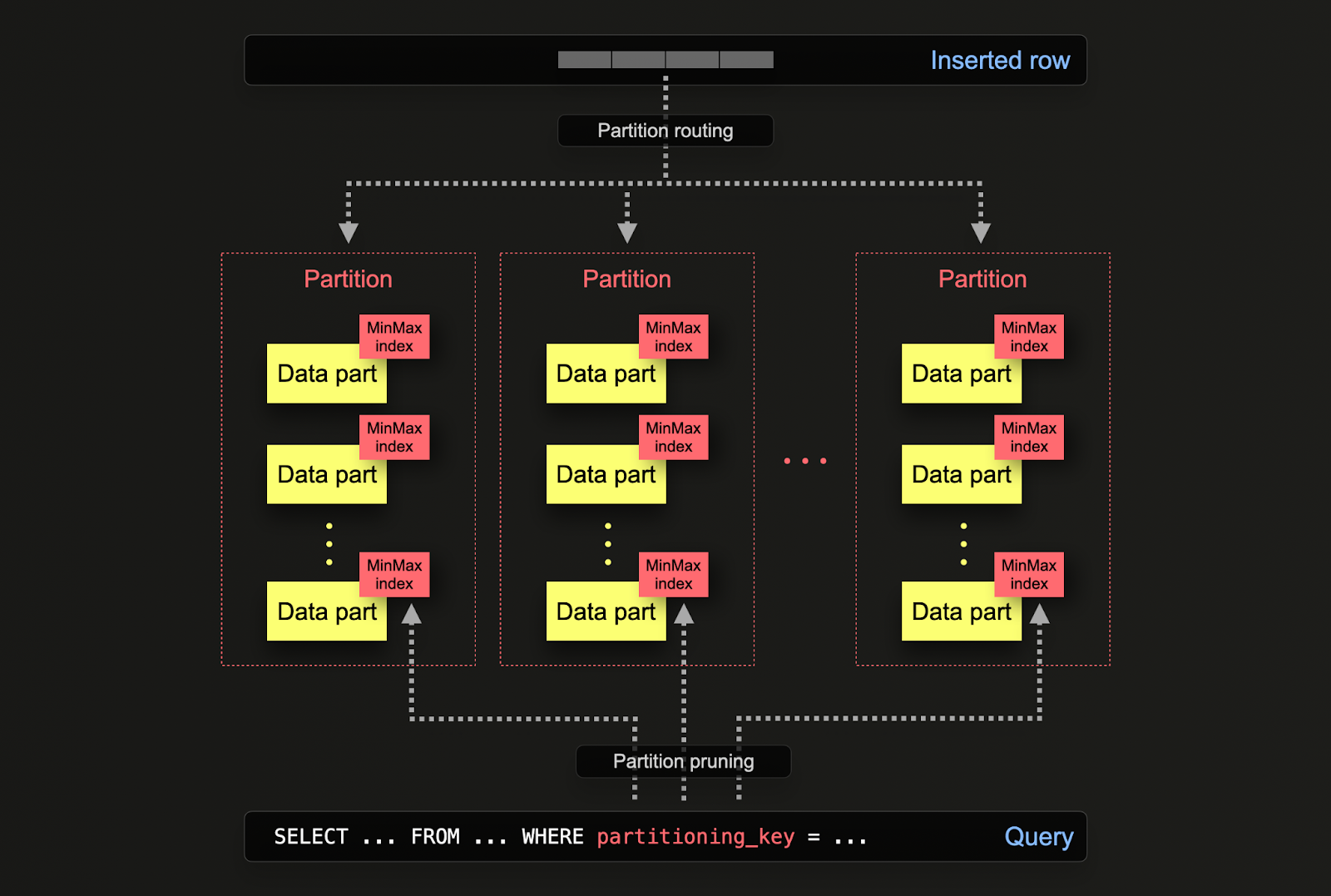
データパーツはディスク上で各パーティションに論理的に関連付けられており、パーティション単位で個別にクエリできます。以下の例では、posts テーブルを toYear(CreationDate) という式を使って年ごとにパーティション分割しています。行が ClickHouse に挿入されると、この式が各行に対して評価され、対応するパーティションが存在すればそこにルーティングされます(その年の最初の行である場合は、新しいパーティションが作成されます)。
パーティショニングの詳細については "Table partitions" を参照してください。
パーティションの用途
ClickHouse におけるパーティショニングは、Postgres における用途と類似していますが、いくつか微妙な違いがあります。より具体的には次のとおりです。
- データ管理 - ClickHouse では、パーティショニングはクエリ最適化の手法ではなく、原則としてデータ管理の機能であると考えるべきです。キーに基づいてデータを論理的に分割することで、それぞれのパーティションを独立して操作できます(例: 削除)。これにより、ストレージ階層間でパーティション、ひいてはデータのサブセットを、時間ベースの条件に従って効率的に移動したり、データの有効期限を設定してクラスタから効率的に削除したりできます。例えば、以下の例では 2008 年の投稿を削除しています。
- クエリ最適化 - パーティションはクエリ性能の向上に役立つ場合がありますが、その効果はアクセスパターンに大きく依存します。クエリが少数のパーティション(理想的には 1 つ)だけを対象とする場合、性能を向上させられる可能性があります。これは、パーティションキーがプライマリキーに含まれておらず、そのキーでフィルタしている場合にのみ、一般的に有用です。ただし、多数のパーティションにまたがって処理する必要があるクエリでは、パーティションを使用しない場合よりも性能が低下する可能性があります(パーティショニングの結果としてパーツ数が増える場合があるため)。対象が単一パーティションであることによる利点は、パーティションキーがすでにプライマリキーの先頭付近に含まれている場合は、ほとんど、あるいはまったく得られなくなります。パーティショニングは、各パーティション内の値が一意であれば、GROUP BY クエリの最適化にも利用できます。しかし一般論としては、まずプライマリキーが最適化されていることを確認し、クエリ最適化の手法としてのパーティショニングは、アクセスパターンが特定の予測可能な日付範囲だけを対象とするような例外的なケース(例: 日単位でパーティショニングしており、ほとんどのクエリが直近 1 日を対象とする場合)にのみ検討すべきです。
パーティションに関する推奨事項
パーティショニングはデータ管理の手法として検討すべきです。特に時系列データを扱う場合に、クラスタから期限切れデータを削除する必要があるときに最適です。例えば、最も古いパーティションを単純に削除できます。
重要: パーティションキーの式によって高カーディナリティな集合が生成されないようにしてください。すなわち、100 を超えるパーティションを作成することは避けるべきです。例えば、クライアント識別子や名前のような高カーディナリティなカラムでデータをパーティションしないでください。代わりに、クライアント識別子または名前を ORDER BY 式の先頭のカラムにしてください。
内部的には、ClickHouse は挿入されたデータに対してパーツを作成します。より多くのデータが挿入されるにつれて、パーツの数は増加します。パーツ数が過度に増え、クエリ性能を低下させないようにするため(読み込むファイルが増えるため)、パーツはバックグラウンドの非同期処理でマージされます。パーツ数が事前設定された上限を超えた場合、ClickHouse は挿入時に例外をスローし、「too many parts」エラーが発生します。これは通常の運用では発生せず、ClickHouse の設定が不適切であるか、誤った使い方をしている場合(例: 非常に小さい挿入を多数行う場合)にのみ発生します。
パーツは各パーティションごとに独立して作成されるため、パーティション数を増やすとパーツ数も増加します。すなわち、パーツ数はパーティション数に比例して増えます。そのため、高カーディナリティなパーティションキーはこのエラーの原因となり得るため、避けるべきです。
マテリアライズドビューとプロジェクションの比較
Postgres では、単一のテーブルに対して複数のインデックスを作成でき、さまざまなアクセスパターンに最適化できます。この柔軟性により、管理者や開発者は特定のクエリや運用要件に合わせてデータベースのパフォーマンスを調整できます。ClickHouse におけるプロジェクションの概念はこれと完全に同じではありませんが、テーブルに対して複数の ORDER BY 句を指定できます。
ClickHouse の データモデリングのドキュメント では、ClickHouse においてマテリアライズドビューを使って集計を事前計算したり、行を変換したり、異なるアクセスパターン向けにクエリを最適化したりする方法を解説しています。
このうち後者の用途については、マテリアライズドビューが、挿入を受け取る元のテーブルとは異なる ORDER BY キーを持つターゲットテーブルに行を送信する サンプル を示しました。
例として、次のクエリを考えてみます。
UserId がソートキーではないため、このクエリでは 9,000 万行すべてをスキャンする必要があります(とはいえ高速ではあります)。
以前は、PostId をルックアップするマテリアライズドビューを使ってこの問題を解決していました。同じ問題は
projection を使っても解決できます。以下のコマンドは、
ORDER BY user_id の projection を追加します。
まずプロジェクションを作成し、その後にマテリアライズする必要がある点に注意してください。後者のコマンドにより、データはディスク上に 2 通りの異なるソート順で二重に保存されます。プロジェクションは、以下に示すようにテーブル作成時に定義することもでき、その場合はデータの挿入に応じて自動的に維持されます。
ALTER でプロジェクションが作成された場合、MATERIALIZE PROJECTION コマンドを実行すると、作成処理は非同期で行われます。次のクエリを使用してこの操作の進行状況を確認し、is_done=1 になるまで待機できます。
上記のクエリを再実行すると、追加のストレージ容量と引き換えにパフォーマンスが大きく向上していることがわかります。
EXPLAIN コマンドにより、このクエリの実行にプロジェクションが使用されたことも確認できます。
プロジェクションを使用する場合
プロジェクションは、データ挿入時に自動的にメンテナンスされるため、新規ユーザーにとって魅力的な機能です。さらに、クエリは単一のテーブルに送信するだけで済み、プロジェクションが可能な限り活用されて応答時間が短縮されます。
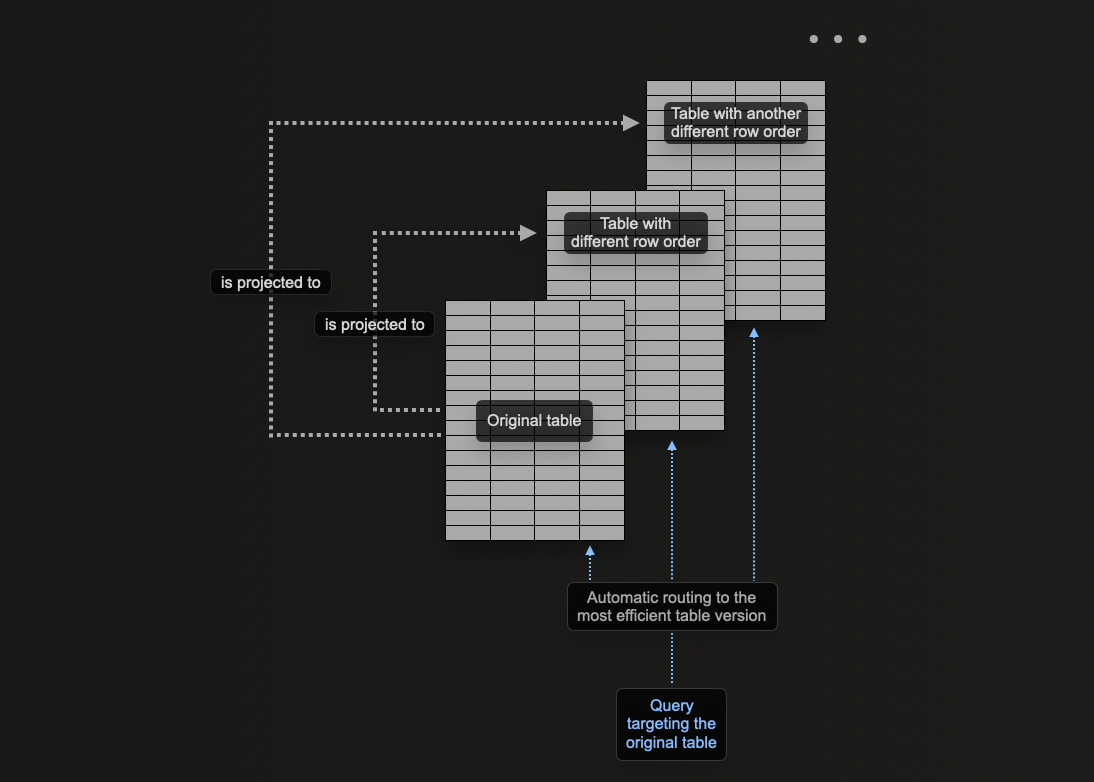
これは、マテリアライズドビューとは対照的です。マテリアライズドビューでは、フィルタに応じて適切に最適化されたターゲットテーブルを選択するか、クエリを書き直す必要があります。これにより、ユーザーアプリケーションへの負担が増大し、クライアント側の複雑性が高まります。
これらの利点にもかかわらず、プロジェクションには固有の制限があるため、それらを認識したうえで、慎重に導入する必要があります。
以下の場合にプロジェクションの使用を推奨します:
- データの完全な並べ替えが必要な場合。プロジェクション内の式は理論上
GROUP BYを使用できますが、集計の維持にはマテリアライズドビューの方が効果的です。また、クエリオプティマイザは、単純な並べ替え(例:SELECT * ORDER BY x)を使用するプロジェクションを活用する可能性が高くなります。この式でカラムのサブセットを選択することで、ストレージフットプリントを削減できます。 - ストレージフットプリントの増加とデータを2回書き込むオーバーヘッドを許容できる場合。挿入速度への影響をテストし、ストレージオーバーヘッドを評価してください。
バージョン25.5以降、ClickHouseはプロジェクション内で仮想カラム_part_offsetをサポートしています。これにより、よりスペース効率の高い方法でプロジェクションを保存できるようになります。
詳細については"Projections"を参照してください。
非正規化
Postgres はリレーショナルデータベースであるため、そのデータモデルは高いレベルで正規化されており、何百ものテーブルが関与することもよくあります。ClickHouse では、JOIN のパフォーマンスを最適化するために、場合によっては非正規化が有効になることがあります。
ClickHouse で Stack Overflow のデータセットを非正規化することの利点を示したガイドを参照してください。
以上で、Postgres から ClickHouse へ移行する場合の基本ガイドは終了です。ClickHouse の高度な機能についてさらに学ぶために、ClickHouse におけるデータモデリングのガイドを読むことをお勧めします。
