付録
Postgres と ClickHouse: 同等概念と相違点
OLTP システムを利用していて ACID トランザクションに慣れているユーザーは、ClickHouse がパフォーマンスと引き換えに、それらを完全には提供しないという意図的なトレードオフを行っていることを理解しておく必要があります。ClickHouse のセマンティクスを十分に理解すれば、高い耐久性保証と高い書き込みスループットを実現できます。ここでは、Postgres から ClickHouse を利用し始める前に、皆さんに理解しておいていただきたい主要な概念をいくつか取り上げます。
シャードとレプリカ
ストレージやコンピュートがパフォーマンス上のボトルネックになった際、1 つの Postgres インスタンスを超えてスケールさせるために用いられる 2 つの戦略が、シャーディングとレプリケーションです。Postgres におけるシャーディングは、大きなデータベースを複数ノードにまたがる小さく扱いやすい単位に分割することを意味します。しかし、Postgres はネイティブにはシャーディングをサポートしていません。その代わり、Citus のような拡張を使うことでシャーディングを実現し、Postgres を水平方向にスケール可能な分散データベースにできます。このアプローチにより、Postgres は負荷を複数マシンに分散することで、より高いトランザクションレートとより大きなデータセットを処理できるようになります。シャードは行ベースまたはスキーマベースとすることができ、トランザクション処理や分析処理など、ワークロードの種類に応じた柔軟性を提供します。一方でシャーディングは、複数マシン間での調整や一貫性保証が必要になるため、データ管理およびクエリ実行の面で大きな複雑さをもたらす可能性があります。
シャードとは異なり、レプリカはプライマリノードのデータ全体または一部を保持する追加の Postgres インスタンスです。レプリカは、読み取り性能の向上や HA(高可用性)シナリオなど、さまざまな目的で使用されます。物理レプリケーションは Postgres のネイティブ機能であり、すべてのデータベース・テーブル・インデックスを含むデータベース全体、またはその大部分を別のサーバーにコピーするものです。これは、プライマリノードからレプリカへ WAL セグメントを TCP/IP 経由でストリーミングすることで実現されます。これに対し、論理レプリケーションは、INSERT、UPDATE、DELETE 操作に基づいて変更をストリーミングする、より高レベルな抽象化です。結果としては物理レプリケーションと同様になり得ますが、特定のテーブルや操作を対象にしたり、データ変換を行ったり、異なる Postgres バージョンをサポートしたりするうえで、より高い柔軟性を提供します。
対照的に、ClickHouse のシャードとレプリカは、データ分散と冗長性に関する 2 つの重要な概念です。 ClickHouse のレプリカは、Postgres のレプリカに類似したものと考えられますが、レプリケーションは最終的な一貫性モデルであり、プライマリという概念はありません。シャーディングは Postgres と異なり、ネイティブにサポートされています。
シャードはテーブルデータの一部分です。常に少なくとも 1 つのシャードが存在します。データを複数サーバーにシャーディングすることで、単一サーバーの容量を超える場合に負荷を分散でき、すべてのシャードを用いてクエリを並列実行できます。ユーザーは、テーブル用のシャードを異なるサーバー上に手動で作成し、そのシャードに直接データを挿入できます。あるいは、分散テーブルを使用し、どのシャードにデータをルーティングするかを決定するシャーディングキーを定義することもできます。シャーディングキーはランダムでも、ハッシュ関数の出力でも構いません。重要な点として、1 つのシャードは複数のレプリカで構成される場合があります。
レプリカはデータのコピーです。ClickHouse には常に少なくとも 1 つのデータコピーが存在するため、レプリカの最小数は 1 です。2 つ目のレプリカを追加すると、フォールトトレランスが得られると同時に、より多くのクエリを処理するための追加コンピュートリソースも得られます(Parallel Replicas を使用すると、1 つのクエリの処理も複数レプリカに分散し、レイテンシを低減できます)。レプリカは、ReplicatedMergeTree table engine によって実現され、ClickHouse は異なるサーバー間で複数のデータコピーを同期した状態に保ちます。レプリケーションは物理的であり、ノード間で転送されるのは圧縮済みパーツのみであって、クエリ自体ではありません。
まとめると、レプリカは冗長性と信頼性(および場合によっては分散処理)を提供するデータのコピーであり、シャードは分散処理と負荷分散を可能にするデータのサブセットです。
ClickHouse Cloud は、S3 上に保持された単一のデータコピーと複数のコンピュートレプリカを使用します。データは各レプリカノードから利用可能であり、それぞれのノードはローカル SSD キャッシュを持ちます。これは、ClickHouse Keeper を介したメタデータレプリケーションのみに依存しています。
結果整合性
ClickHouse は内部レプリケーションメカニズムの管理に ClickHouse Keeper(C++ で実装された ZooKeeper。ZooKeeper 自体も利用可能)を使用しており、主にメタデータの保存と結果整合性の確保に重点を置いています。Keeper は分散環境における各 INSERT に対して一意の連番を割り当てるために使用されます。これは、処理全体の順序性と一貫性を維持するうえで重要です。このフレームワークは、マージやミューテーションといったバックグラウンド処理も扱い、それらの処理が分散して実行される一方で、すべてのレプリカで同一の順序で確実に実行されるようにします。メタデータに加えて、Keeper は保存済みデータパーツのチェックサム追跡を含むレプリケーションの包括的なコントロールセンターとして機能し、レプリカ間の分散通知システムとしても動作します。
ClickHouse におけるレプリケーションプロセスは、(1) 任意のレプリカにデータが挿入されたときに開始されます。このデータは生の INSERT 形式のまま、(2) チェックサムとともにディスクへ書き込まれます。書き込み後、レプリカは (3) Keeper 内でこの新しいデータパーツを登録しようとし、一意のブロック番号を割り当てて新しいパーツの詳細をログに記録します。他のレプリカは、(4) レプリケーションログ内の新規エントリを検出すると、(5) 内部 HTTP プロトコルを通じて対応するデータパーツをダウンロードし、ZooKeeper に記録されているチェックサムと照合します。この方式により、処理速度のばらつきや潜在的な遅延があっても、すべてのレプリカが最終的に一貫した最新データを保持できるようになります。さらに、このシステムは複数の処理を同時に扱うことができるため、データ管理プロセスを最適化し、システムのスケーラビリティとハードウェアの違いに対する堅牢性を実現します。
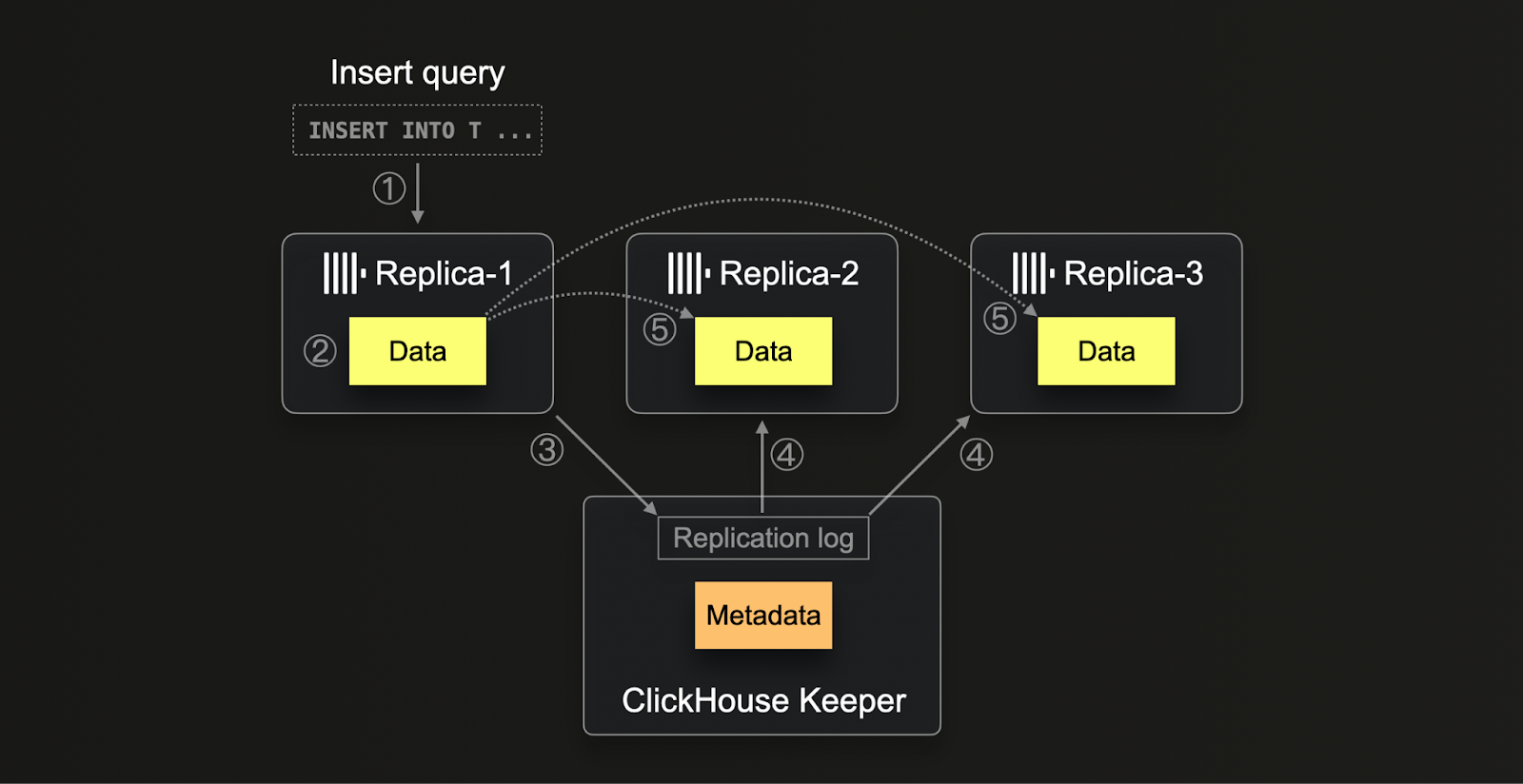
ClickHouse Cloud では、ストレージとコンピュートの分離アーキテクチャに適応した クラウド最適化レプリケーションメカニズム が使用されています。データを共有オブジェクトストレージに保存することで、ノード間でデータを物理的にレプリケートすることなく、すべてのコンピュートノードからデータを自動的に利用可能にします。その代わりに Keeper は、コンピュートノード間でメタデータ(オブジェクトストレージ上のどこにどのデータが存在するか)だけを共有するために使用されます。
PostgreSQL は ClickHouse とは異なるレプリケーション戦略を採用しており、主にストリーミングレプリケーションを利用します。これは、プライマリ・レプリカモデルに基づき、データがプライマリから 1 つ以上のレプリカノードへ継続的にストリーミングされる方式です。この種のレプリケーションは、ほぼリアルタイムの整合性を提供し、同期または非同期として構成できるため、管理者は可用性と整合性のバランスを制御できます。ClickHouse とは異なり、PostgreSQL はノード間でデータオブジェクトと変更内容をストリーミングするために、論理レプリケーションおよびデコードを伴う WAL(Write-Ahead Logging)に依存しています。PostgreSQL のこのアプローチはより単純ではありますが、高度に分散された環境においては、ClickHouse が Keeper を用いた複雑な分散処理の調整と結果整合性の確保によって達成しているレベルと同等のスケーラビリティやフォールトトレランスを提供できない場合があります。
ユーザーへの影響
ClickHouse では、Keeper によって管理される最終的な整合性モデルのレプリケーションにより、あるレプリカにデータを書き込んだ後、別のレプリカから、まだレプリケートされていない可能性のあるデータを読み取ってしまう「ダーティリード」が発生する可能性があります。このモデルは、分散システム全体でのパフォーマンスとスケーラビリティを重視しており、レプリカが独立して動作し、非同期にデータを同期することを許容します。その結果、レプリケーションの遅延や、変更がシステム全体に伝播するまでの時間によっては、新しく挿入されたデータがすべてのレプリカ上で即座に参照可能にならない場合があります。
対照的に、PostgreSQL のストリーミングレプリケーションモデルでは、プライマリがトランザクションをコミットする前に、少なくとも 1 つのレプリカがデータ受領を確認するまで待機する同期レプリケーションオプションを利用することで、一般的にダーティリードを防ぐことができます。これにより、一度トランザクションがコミットされると、そのデータが別のレプリカ上で利用可能であるという保証が得られます。プライマリ障害が発生した場合でも、レプリカはクエリがコミット済みデータを参照できるようにし、より厳密な整合性レベルを維持します。
推奨事項
ClickHouse を初めて利用するユーザーは、レプリケーションされた環境では、ここで説明するような差異が生じることを理解しておく必要があります。通常、分析対象が数十億件、場合によっては数兆件のデータポイントに及ぶ場合には、最終的な整合性で十分です。このような状況では、新しいデータが高頻度で継続的に挿入されるため、メトリクスはより安定しているか、あるいは推定でも十分であることが多いためです。
必要に応じて、読み取り時の整合性を高めるためのいくつかの選択肢があります。どちらの例も、複雑さやオーバーヘッドの増加を伴い、クエリ性能を低下させるとともに、ClickHouse のスケーリングをより困難にします。これらのアプローチは、どうしても必要な場合にのみ採用することを推奨します。
一貫したルーティング
最終的整合性に伴ういくつかの制約を克服するために、クライアントを常に同じレプリカにルーティングするようにできます。これは、複数のユーザーが ClickHouse に対してクエリを実行しており、リクエスト間で結果の決定性が求められる場合に有用です。新しいデータの挿入によって結果は変わり得ますが、常に同じレプリカに対してクエリを実行することで、一貫したビューを確保できます。
これは、システムのアーキテクチャや、ClickHouse OSS か ClickHouse Cloud のどちらを使用しているかに応じて、いくつかのアプローチで実現できます。
ClickHouse Cloud
ClickHouse Cloud は、S3 上に保持された単一コピーのデータを複数のコンピュートレプリカから利用する構成を取ります。各レプリカノードにはローカル SSD キャッシュがあり、そのノードからデータにアクセスできます。一貫した結果を得るためには、常に同じノードに対して一貫してルーティングされるようにする必要があります。
ClickHouse Cloud サービスの各ノードとの通信は、プロキシを介して行われます。HTTP および Native プロトコルの接続は、接続が確立されている間は同じノードにルーティングされます。多くのクライアントからの HTTP/1.1 接続の場合、これは Keep-Alive ウィンドウに依存します。これは多くのクライアント(例: Node.js)側で設定可能です。また、サーバー側の設定も必要であり、クライアント側より長く設定されます。ClickHouse Cloud では 10 秒に設定されています。
接続プールを使用している場合や接続が切断される場合など、接続をまたいで一貫したルーティングを行うには、同じ接続を使用するようにする(Native プロトコルの方が容易)か、sticky endpoint の公開をリクエストすることができます。これにより、クラスタ内の各ノードに対して一連のエンドポイントが提供され、クライアントはクエリが常に同じノードにルーティングされることを保証できます。
sticky endpoint へのアクセスについてはサポートにお問い合わせください。
ClickHouse OSS
OSS でこの挙動を実現できるかどうかは、シャードおよびレプリカのトポロジーと、クエリに Distributed table を使用しているかどうかに依存します。
シャードが 1 つだけでレプリカがある場合(ClickHouse は垂直スケールするため一般的な構成です)、ユーザーはクライアントレイヤーでノードを選択し、レプリカに直接クエリを送ることで、常に同じレプリカが選ばれるようにします。
複数のシャードおよびレプリカを持つトポロジーは Distributed table なしでも構成可能ですが、このような高度なデプロイメントでは通常、独自のルーティング基盤を持っています。そのため、1 つを超えるシャードを持つデプロイメントでは Distributed table を使用しているものと想定します(Distributed table は単一シャードのデプロイメントでも使用できますが、通常は不要です)。
この場合、ユーザーは session_id や user_id などのプロパティに基づいて、一貫したノードルーティングが行われるようにする必要があります。設定値 prefer_localhost_replica=0、load_balancing=in_order をクエリレベルで設定します。これにより、シャードのローカルレプリカが優先され、それ以外の場合は設定で列挙された順にレプリカが優先されます。同じエラー数であればこの順序で使用され、エラーが多い場合にはフェイルオーバーとしてランダム選択が行われます。決定的なシャード選択の代替として、load_balancing=nearest_hostname を使用することもできます。
Distributed table を作成する際、ユーザーはクラスタを指定します。このクラスタ定義は config.xml で指定され、シャード(およびそのレプリカ)が列挙されます。これにより、各ノードからどの順序で使用されるかをユーザーが制御できます。これを利用して、ユーザーは選択を決定的にすることができます。
シーケンシャル一貫性
特殊なケースでは、ユーザーがシーケンシャル一貫性を必要とする場合があります。
データベースにおけるシーケンシャル一貫性とは、データベース上の操作が何らかの順序で逐次実行されているように見え、その順序がデータベースとやり取りするすべてのプロセス間で一貫している状態を指します。つまり、すべての操作が、その呼び出しと完了の間のどこかで瞬時に効果を及ぼしたように見え、すべての操作が、どのプロセスから見ても単一で合意された順序で観測されることを意味します。
ユーザーの視点からは、これは通常、ClickHouse にデータを書き込み、その後にデータを読み取る際に、直近で挿入された行が必ず返されることを保証する必要性として現れます。 これは、以下のいずれかの方法で(優先度順に)実現できます。
- 同じノードに対して読み書きする - ネイティブプロトコルを使用している場合、または セッションを使って HTTP 経由で書き込み/読み取りを行う場合、同じレプリカに接続されている必要があります。このシナリオでは、書き込んでいるノードから直接読み取ることになるため、読み取り結果は常に一貫性が保たれます。
- レプリカを手動で同期する - 一方のレプリカに書き込み、別のレプリカから読み取る場合は、読み取りの前に
SYSTEM SYNC REPLICA LIGHTWEIGHTを実行できます。 - シーケンシャル一貫性を有効にする - クエリ設定
select_sequential_consistency = 1を有効にします。OSS では、追加で設定insert_quorum = 'auto'も指定する必要があります。
これらの設定を有効にする方法の詳細はこちらを参照してください。
シーケンシャル一貫性を使用すると、ClickHouse Keeper により大きな負荷がかかります。その結果、挿入および読み取りが遅くなる可能性があります。ClickHouse Cloud でメインのテーブルエンジンとして使用されている SharedMergeTree では、シーケンシャル一貫性によるオーバーヘッドが小さく、よりスケールしやすくなります。OSS でこのアプローチを利用する場合は、慎重に行い、Keeper の負荷を測定する必要があります。
トランザクション(ACID)サポート
PostgreSQL から移行するユーザーは、トランザクションデータベースとしての信頼性を高める ACID(Atomicity, Consistency, Isolation, Durability)特性の強力なサポートに慣れているかもしれません。PostgreSQL における Atomicity(原子性)は、各トランザクションが 1 つの単位として扱われ、完全に成功するか、あるいは完全にロールバックされ、部分的な更新が発生しないことを保証します。Consistency(一貫性)は、すべてのデータベーストランザクションが有効な状態に至るよう保証する制約、トリガー、およびルールを適用することで維持されます。Isolation(分離性)レベルとしては、Read Committed から Serializable までが PostgreSQL でサポートされており、同時実行トランザクションによる変更が他のトランザクションからどのように見えるかをきめ細かく制御できます。最後に、Durability(永続性)は write-ahead logging(WAL)によって実現され、トランザクションがコミットされた後は、システム障害が発生してもその状態が保持されることを保証します。
これらの特性は、信頼できる唯一の情報源(source of truth)として機能する OLTP データベースに一般的なものです。
このような仕組みは強力ではありますが、本質的な制約を伴い、ペタバイト級のスケールを扱うことを困難にします。ClickHouse は、高い書き込みスループットを維持しながら、大規模な高速分析クエリを提供するために、これらの特性の一部をトレードオフしています。
ClickHouse は、限定された構成 の下で ACID 特性を提供します。最も単純な例は、1 つのパーティションを持つ、レプリケーションなしの MergeTree テーブルエンジンのインスタンスを使用する場合です。これらのケース以外で ACID 特性が提供されることを想定すべきではなく、それらが必須要件ではないことを確認してください。
圧縮
ClickHouse のカラム指向ストレージでは、Postgres と比較して圧縮効率が大幅に優れることがよくあります。以下は、両方のデータベースで Stack Overflow の全テーブルを格納した場合のストレージ要件を比較した例です。
圧縮の最適化と測定の詳細については、こちらを参照してください。
データ型のマッピング
次の表は、Postgres のデータ型に対応する ClickHouse のデータ型を示します。
| Postgres Data Type | ClickHouse Type |
|---|---|
DATE | Date |
TIMESTAMP | DateTime |
REAL | Float32 |
DOUBLE | Float64 |
DECIMAL, NUMERIC | Decimal |
SMALLINT | Int16 |
INTEGER | Int32 |
BIGINT | Int64 |
SERIAL | UInt32 |
BIGSERIAL | UInt64 |
TEXT, CHAR, BPCHAR | String |
INTEGER | Nullable(Int32) |
ARRAY | Array |
FLOAT4 | Float32 |
BOOLEAN | Bool |
VARCHAR | String |
BIT | String |
BIT VARYING | String |
BYTEA | String |
NUMERIC | Decimal |
GEOGRAPHY | Point, Ring, Polygon, MultiPolygon |
GEOMETRY | Point, Ring, Polygon, MultiPolygon |
INET | IPv4, IPv6 |
MACADDR | String |
CIDR | String |
HSTORE | Map(K, V), Map(K,Variant) |
UUID | UUID |
ARRAY<T> | ARRAY(T) |
JSON | String, Variant, Nested, Tuple |
JSONB | String |
