Splunk と ClickHouse を接続する
ClickHouse の監査ログを Splunk に保存したい場合は、"Storing ClickHouse Cloud Audit logs into Splunk" ガイドを参照してください。
Splunk は、セキュリティとオブザーバビリティの分野で広く使われているテクノロジーです。また、強力な検索およびダッシュボード作成エンジンでもあります。さまざまなユースケースに対応する数百もの Splunk アプリが提供されています。
ClickHouse との連携では、Splunk DB Connect App を使用します。このアプリは、高性能な ClickHouse JDBC ドライバーとシンプルに統合でき、ClickHouse 内のテーブルに対して直接クエリを実行できます。
この連携が特に適しているのは、NetFlow、Avro または Protobuf のバイナリデータ、DNS、VPC フローログ、その他の OTel ログといった大規模なログソースに ClickHouse を使用し、それらを Splunk 上でチームと共有して検索やダッシュボード作成を行う場合です。この方法では、データは Splunk の索引レイヤーに取り込まれず、Metabase や Superset のような他の可視化連携と同様に、ClickHouse に対して直接クエリするだけで済みます。
目標
このガイドでは、ClickHouse JDBC ドライバーを使用して ClickHouse を Splunk に接続します。ローカル環境に Splunk Enterprise をインストールしますが、ここでは Splunk 側でデータをインデックスしません。その代わりに、DB Connect のクエリエンジン経由で検索機能を利用します。
このガイドに従うことで、次のように ClickHouse に接続されたダッシュボードを作成できるようになります。
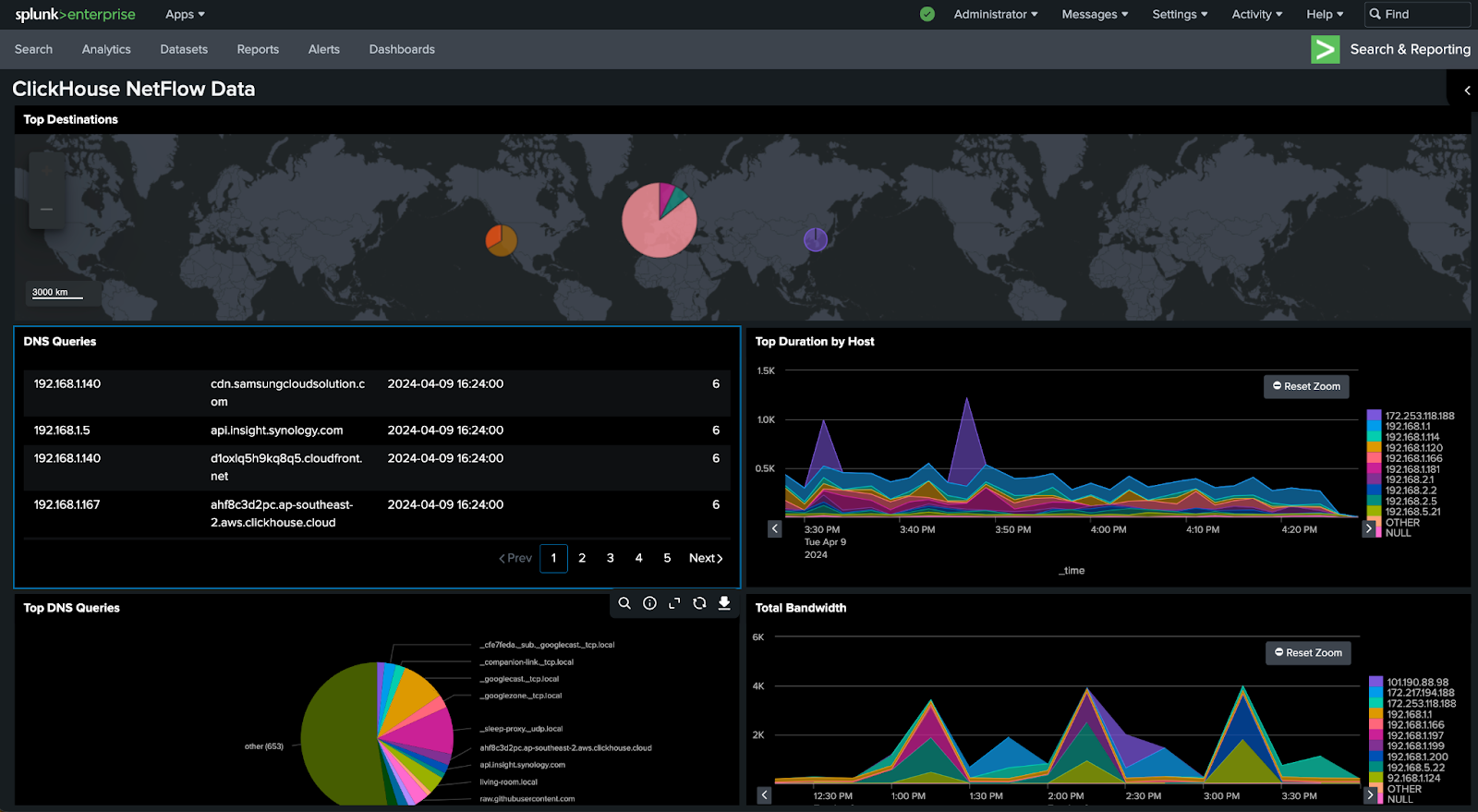
このガイドでは New York City Taxi データセット を使用します。ドキュメントには、他にも利用可能なデータセットが多数あります。
前提条件
作業を開始する前に、次のものが必要です:
- Search Head 機能を利用するための Splunk Enterprise
- OS またはコンテナ上に、Java Runtime Environment (JRE) の要件を満たす環境がインストールされていること
- Splunk DB Connect
- Splunk Enterprise が稼働している OS への管理者権限または SSH アクセス
- ClickHouse の接続情報(ClickHouse Cloud を使用している場合はこちらを参照)
Splunk Enterprise に DB Connect をインストールして設定する
まず、Splunk Enterprise インスタンスに Java ランタイム環境 (Java Runtime Environment) をインストールする必要があります。Docker を使用している場合は、microdnf install java-11-openjdk コマンドを使用できます。
java_home パスを控えておいてください: java -XshowSettings:properties -version。
Splunk Enterprise に DB Connect App がインストールされていることを確認してください。Splunk Web UI の Apps セクションで確認できます。
- Splunk Web にログインし、Apps > Find More Apps に移動します
- 検索ボックスを使用して DB Connect を探します
- Splunk DB Connect の横にある緑色の「Install」ボタンをクリックします
- 「Restart Splunk」をクリックします
DB Connect App のインストールに問題がある場合は、追加の手順について このリンク を参照してください。
DB Connect App がインストールされていることを確認したら、Configuration -> Settings で DB Connect App に java_home パスを追加し、「Save」をクリックしてから「Reset」を実行します。
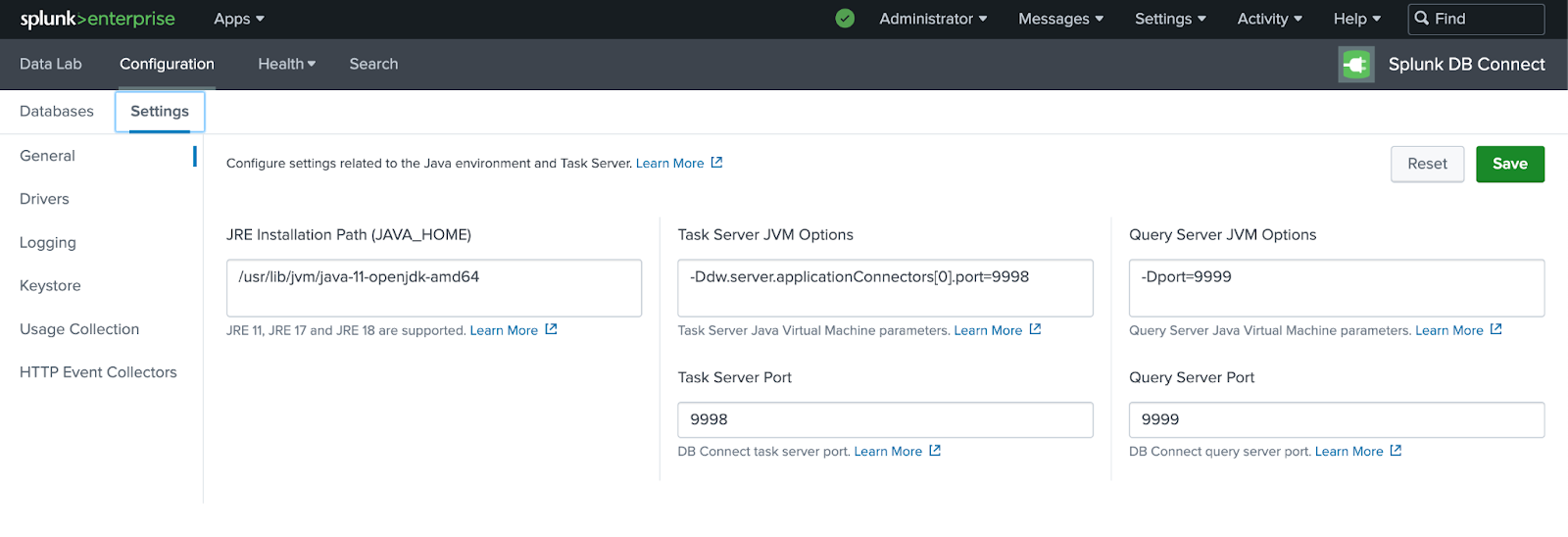
ClickHouse 用 JDBC を設定する
ClickHouse JDBC ドライバーの JAR ファイル をダウンロードし、次の場所にある DB Connect Drivers フォルダーにコピーします。
DB Connect アプリで必須の依存関係をすべて利用可能にするために、次のいずれかをダウンロードします:
次に、ClickHouse JDBC Driver のクラス情報を追加するために、$SPLUNK_HOME/etc/apps/splunk_app_db_connect/local/db_connection_types.conf の接続タイプ設定を編集する必要があります。db_connection_types.conf に次のスタンザを追加します:
$SPLUNK_HOME/bin/splunk restart を実行して Splunk を再起動します。
DB Connect App に戻り、Configuration > Settings > Drivers に移動します。ClickHouse の横に緑色のチェックマークが表示されていることを確認します。
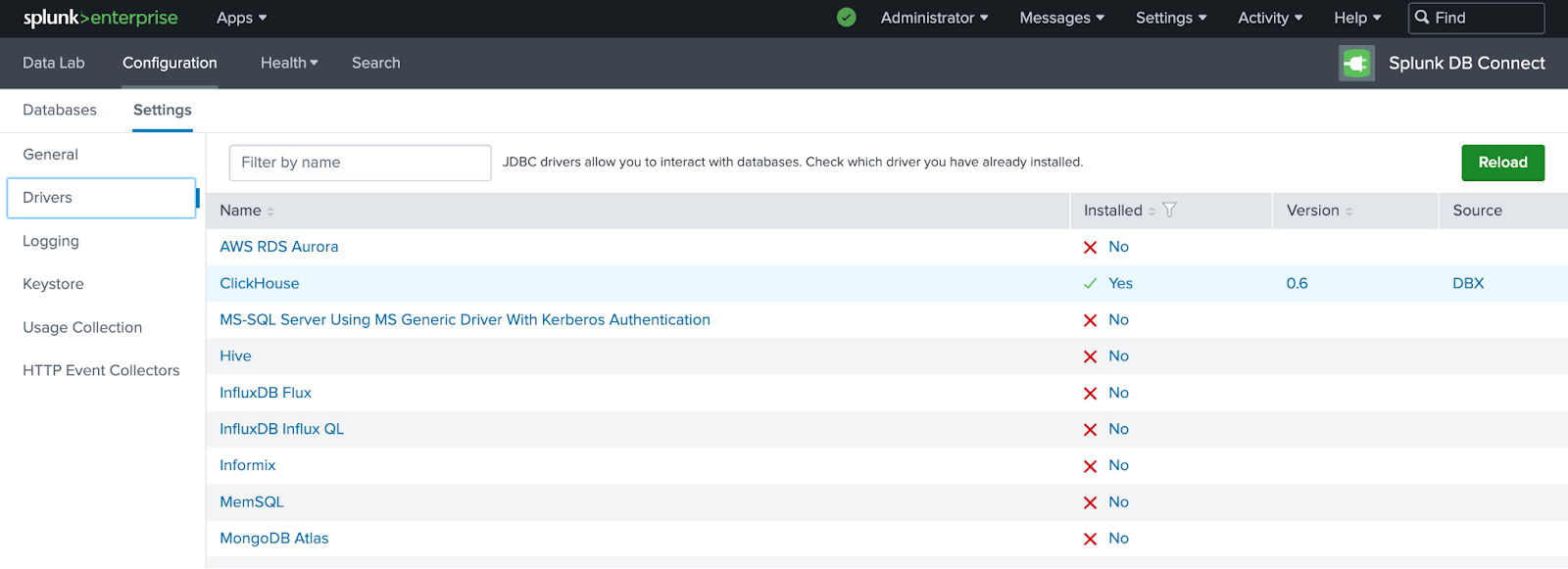
Splunk の検索を ClickHouse に接続する
DB Connect App Configuration -> Databases -> Identities に移動し、ClickHouse 用の Identity を作成します。
Configuration -> Databases -> Connections から ClickHouse への新しい Connection を作成し、"New Connection" を選択します。
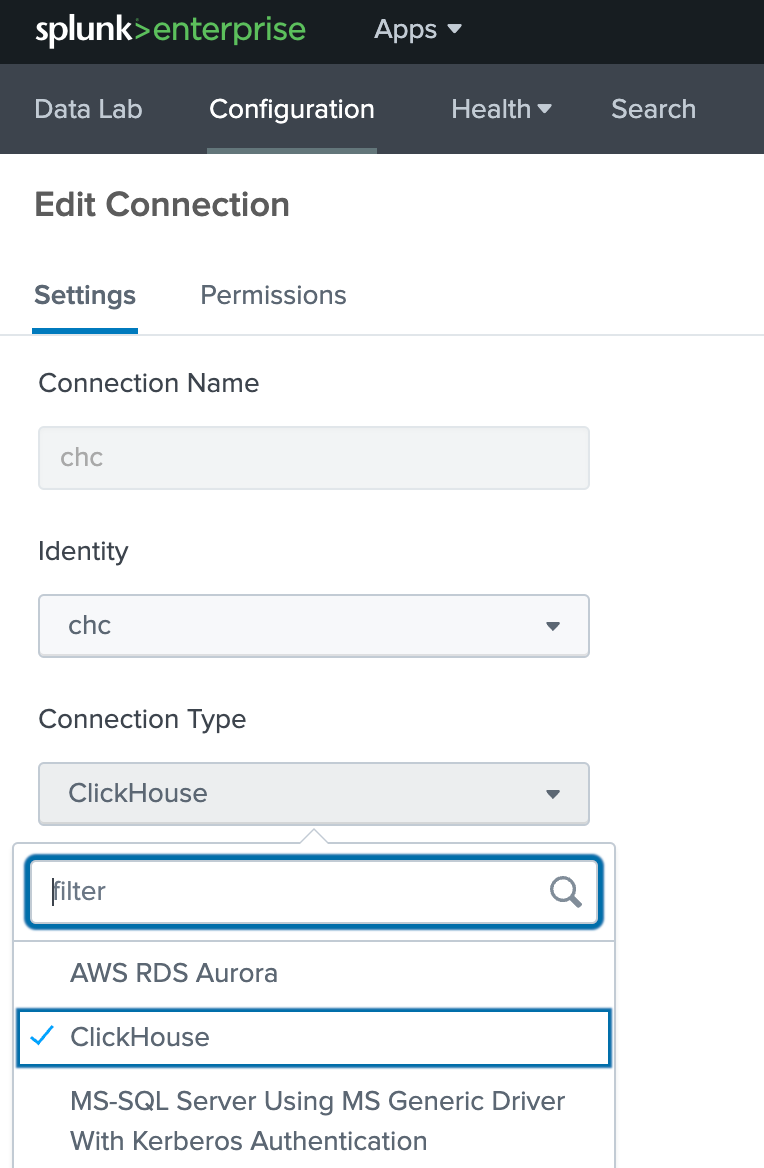
ClickHouse ホスト情報を入力し、"Enable SSL" にチェックが入っていることを確認します:
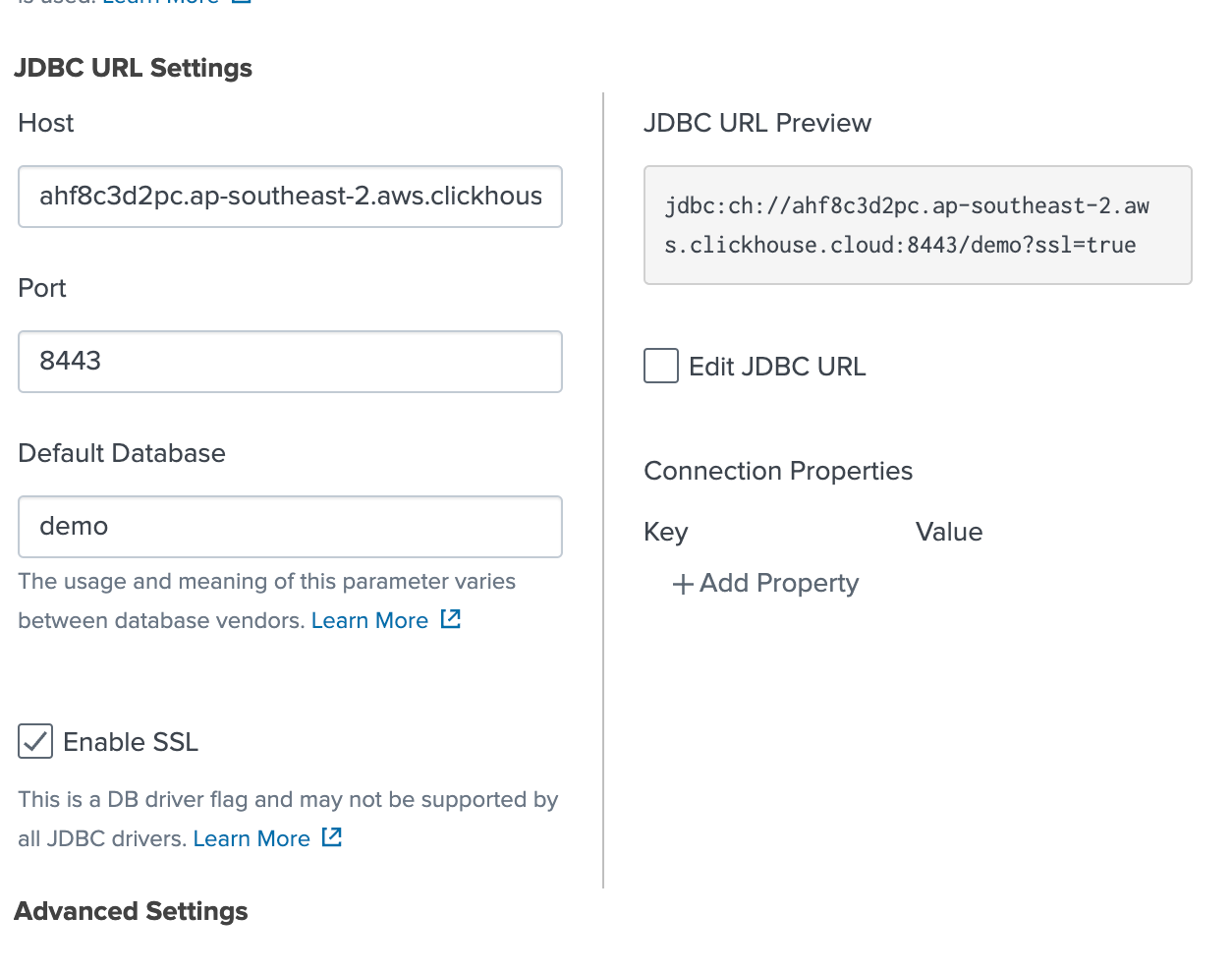
接続を保存すると、ClickHouse と Splunk の接続が完了します。
エラーが発生した場合は、Splunk インスタンスの IP アドレスを ClickHouse Cloud の IP Access List に追加していることを確認してください。詳細は ドキュメント を参照してください。
SQL クエリを実行する
これから SQL クエリを実行して、すべてが正しく動作していることを確認します。
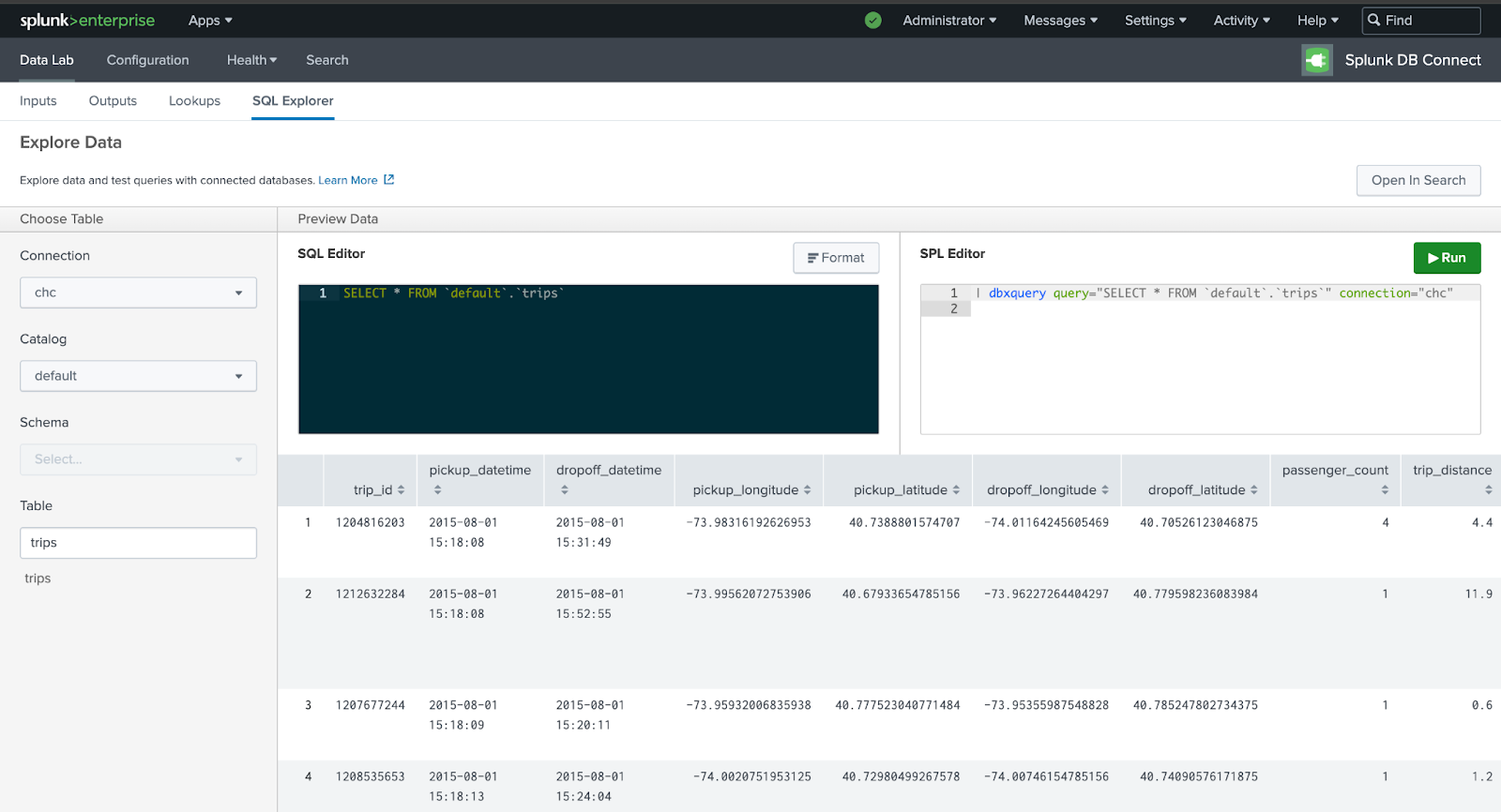
DB Connect App の DataLab セクションにある SQL Explorer で接続先を選択します。このデモでは trips テーブルを使用します:
trips テーブルに対して、テーブル内の全レコード件数を返す SQL クエリを実行します:
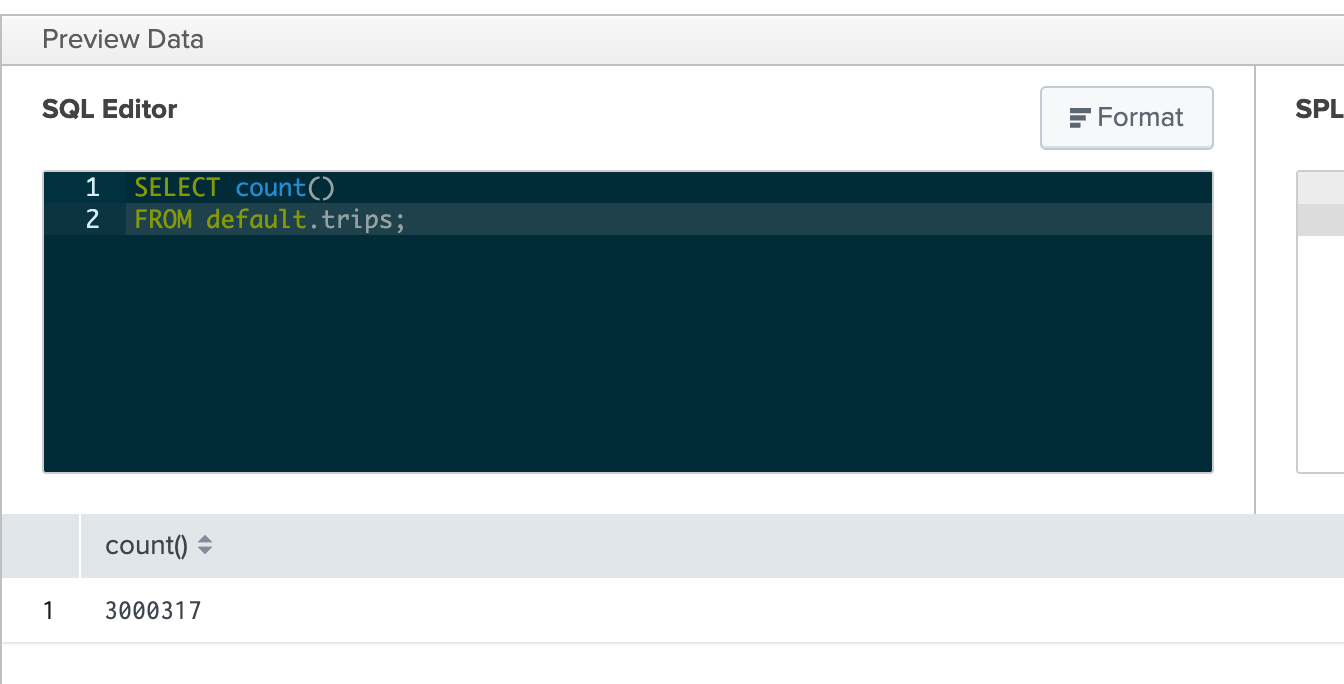
クエリが成功すると、結果が表示されます。
ダッシュボードを作成する
SQL と強力な Splunk Processing Language (SPL) を組み合わせて活用するダッシュボードを作成してみましょう。
続行する前に、まず Deactivate DPL Safeguards を無効化する必要があります。
次のクエリを実行して、ピックアップ回数が最も多い地区の上位 10 件を表示します。
[Visualization] タブを選択して、作成された棒グラフを表示します。
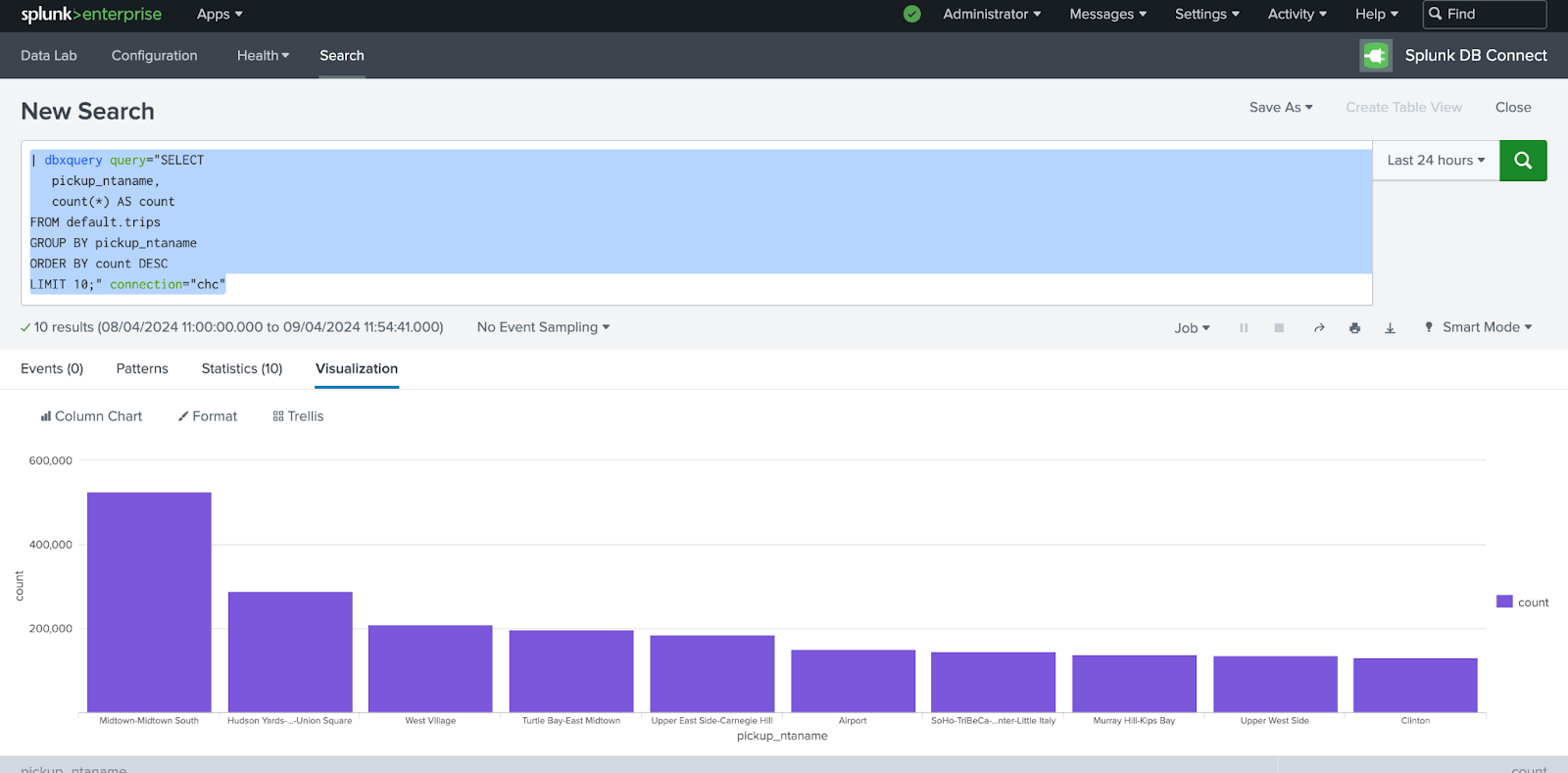
次に、「Save As」>「Save to a Dashboard」をクリックしてダッシュボードを作成します。
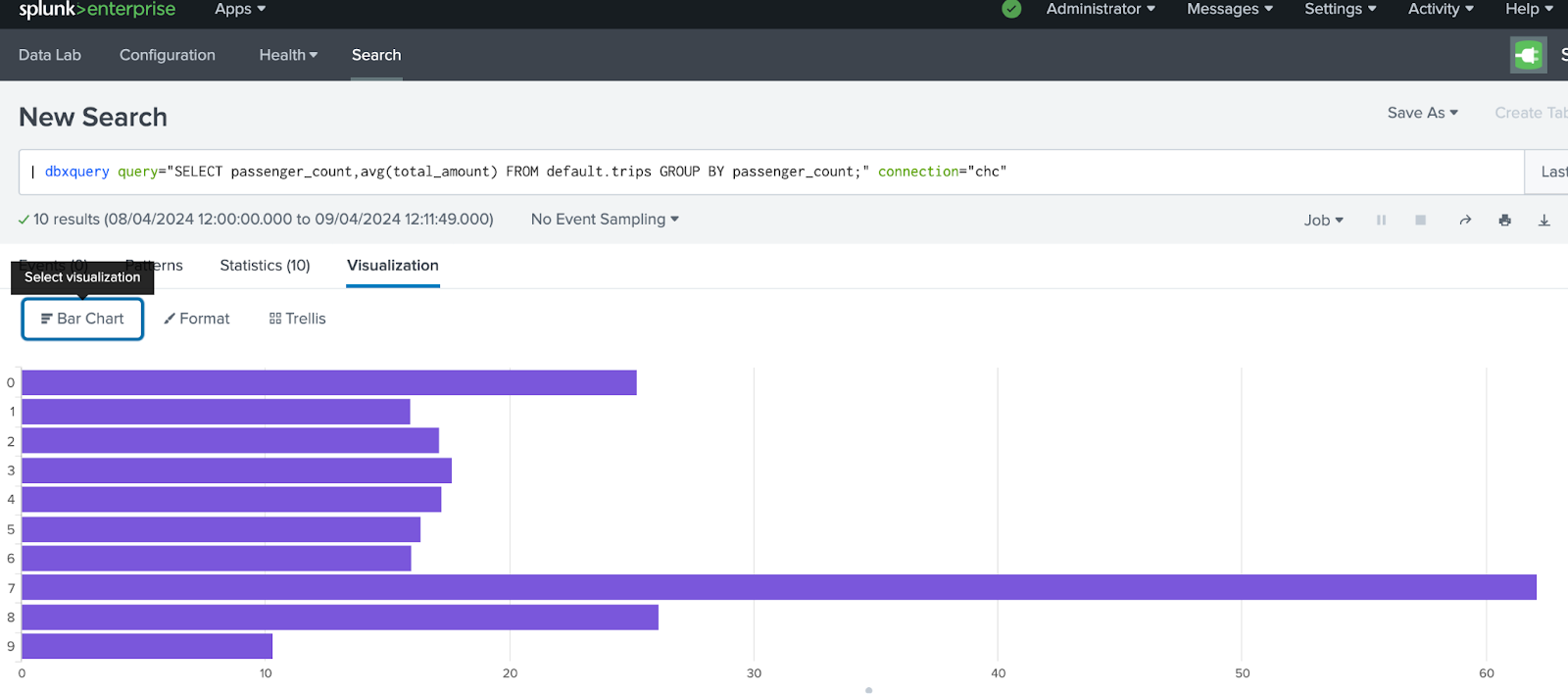
乗客数ごとの平均運賃を表示する別のクエリを追加しましょう。
今回は、棒グラフの可視化を作成し、先ほどのダッシュボードに保存します。
最後に、乗客数と乗車距離の相関関係を示すクエリをもう 1 つ追加してみましょう。
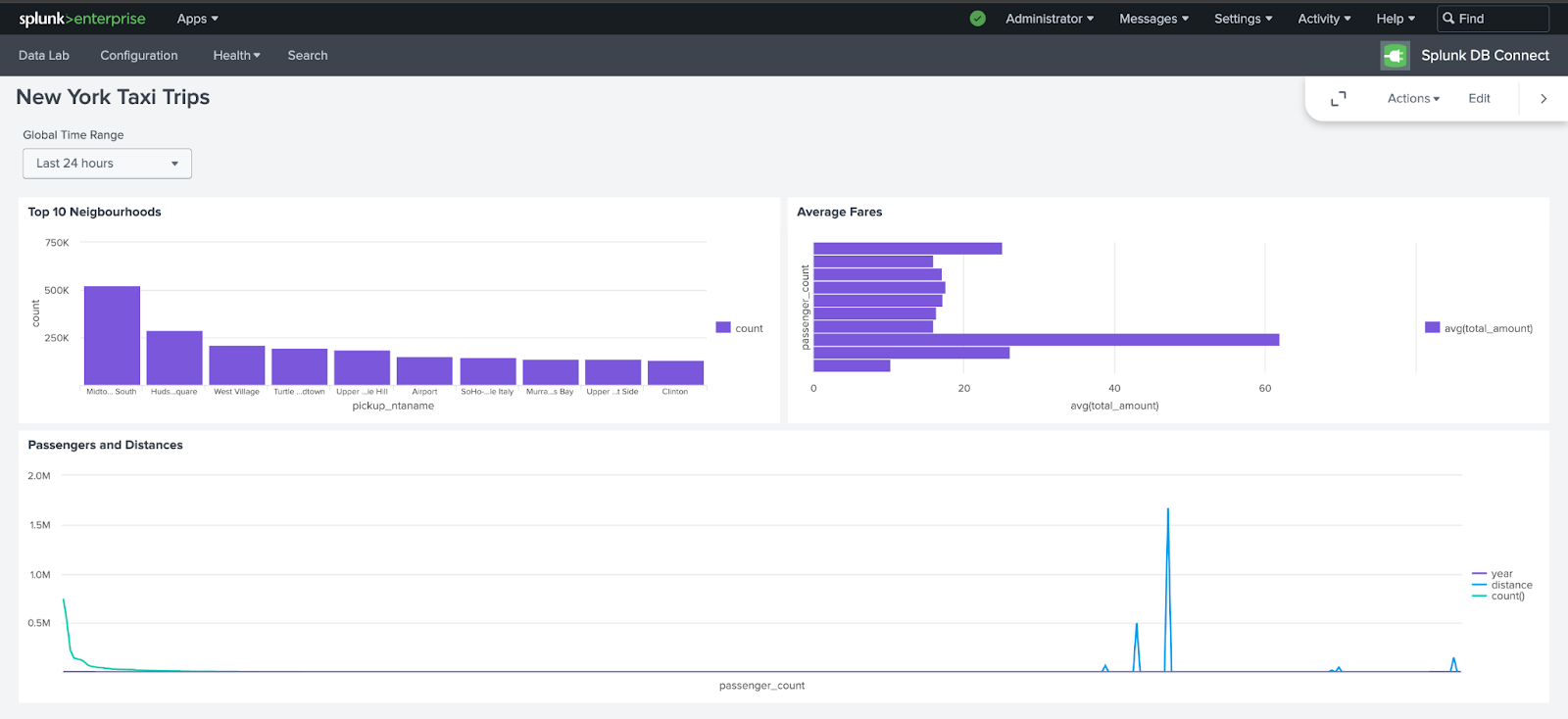
最終的なダッシュボードは以下のようになります。
時系列データ
Splunk には、ダッシュボードで時系列データの可視化や表示に利用できる数百もの組み込み関数があります。次の例では、Splunk で時系列データを扱うためのクエリを作成するために、SQL と SPL を組み合わせます。
詳細情報
Splunk DB Connect の詳細やダッシュボードの作成方法については、Splunk のドキュメントを参照してください。
