S3 の insert および読み取りパフォーマンスの最適化
このセクションでは、s3 テーブル関数 を使用して S3 からデータを読み取りおよび insert する際のパフォーマンス最適化に焦点を当てます。
本ガイドで説明する手法は、GCS や Azure Blob storage など、独自の専用テーブル関数を持つ他のオブジェクトストレージ実装にも適用できます。
insert パフォーマンスを向上させるためにスレッド数やブロックサイズをチューニングする前に、まずは S3 への insert の仕組みを理解することをお勧めします。すでに insert の仕組みに慣れている場合や、すぐに役立つヒントだけを知りたい場合は、以下のサンプルデータセットに進んでください.
挿入メカニズム(単一ノード)
ハードウェアの規模に加えて、ClickHouse のデータ挿入メカニズム(単一ノード)のパフォーマンスとリソース使用量に影響を与える主な要因は 2 つあります。挿入ブロックサイズ と 挿入の並列度 です。
挿入ブロックサイズ
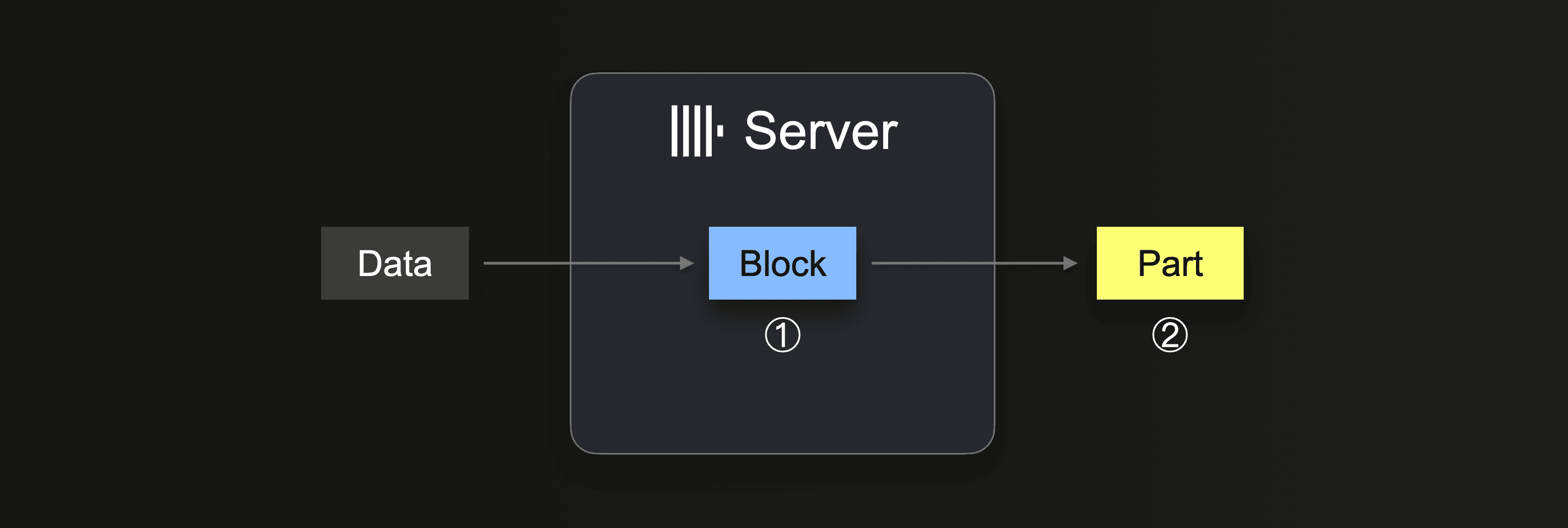
INSERT INTO SELECT を実行する際、ClickHouse はデータの一部を受け取り、受信したデータから ① メモリ内に(少なくとも 1 つの、パーティショニングキー ごとの)挿入ブロックを形成します。ブロック内のデータはソートされ、テーブルエンジン固有の最適化が適用されます。その後、データは圧縮され、② 新しいデータパーツの形式でデータベースストレージに書き込まれます。
挿入ブロックサイズは、ClickHouse サーバーの ディスクファイル I/O 使用量 とメモリ使用量の両方に影響します。より大きな挿入ブロックはより多くのメモリを使用しますが、より大きく、数の少ない初期データパーツを生成します。大量のデータをロードする際に ClickHouse が作成する必要のあるパーツが少ないほど、必要なディスクファイル I/O と自動バックグラウンドマージも少なくなります。
INSERT INTO SELECT クエリをインテグレーションテーブルエンジンまたはテーブル関数と組み合わせて使用する場合、データは ClickHouse サーバーによってプルされます。
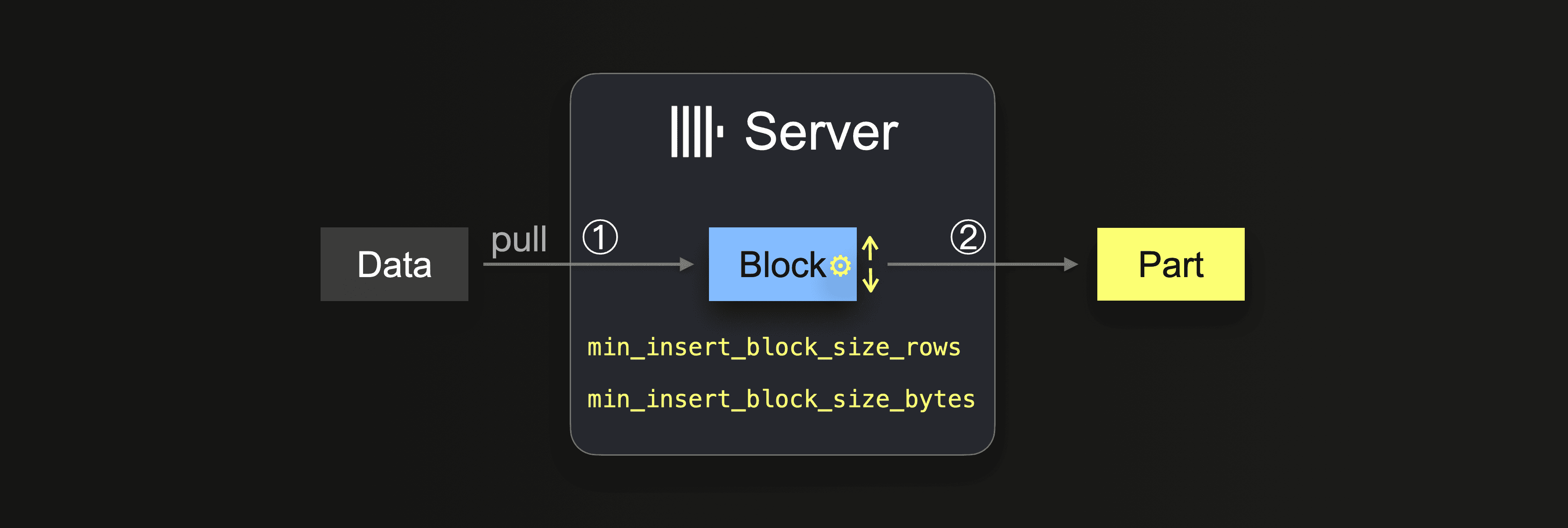
データが完全にロードされるまで、サーバーはループを実行します。
① では、サイズは挿入ブロックサイズに依存し、これは次の 2 つの設定で制御できます。
min_insert_block_size_rows(デフォルト:1048545行)min_insert_block_size_bytes(デフォルト:256 MiB)
挿入ブロックに指定した行数が集まるか、設定したデータ量に達すると(どちらか早い方)、その時点でブロックが新しいパーツとして書き込まれます。挿入ループはステップ ① に進みます。
min_insert_block_size_bytes の値は、圧縮前のメモリ内ブロックサイズを示すことに注意してください(圧縮後のオンディスクパーツサイズではありません)。また、ClickHouse はデータを行ごとのブロック単位でストリーミングし、処理するため、作成されるブロックおよびパーツに設定した行数やバイト数が正確に含まれることはまれです。したがって、これらの設定は最小しきい値を指定します。
マージに注意する
設定された挿入ブロックサイズが小さいほど、大量データロード時に作成される初期パートの数が増え、データのインジェストと同時にバックグラウンドのパートマージがより多く実行されます。これにより、リソース(CPU とメモリ)の競合が発生し、インジェスト完了後に健全な(3000)パート数に到達するまでに追加の時間が必要になる可能性があります。
パート数が推奨上限を超えると、ClickHouse のクエリパフォーマンスは悪化します。
ClickHouse は、圧縮サイズが約 150 GiB に到達するまで、継続的にパートをマージして、より大きなパートにまとめます。次の図は、ClickHouse サーバーがどのようにパートをマージするかを示しています。
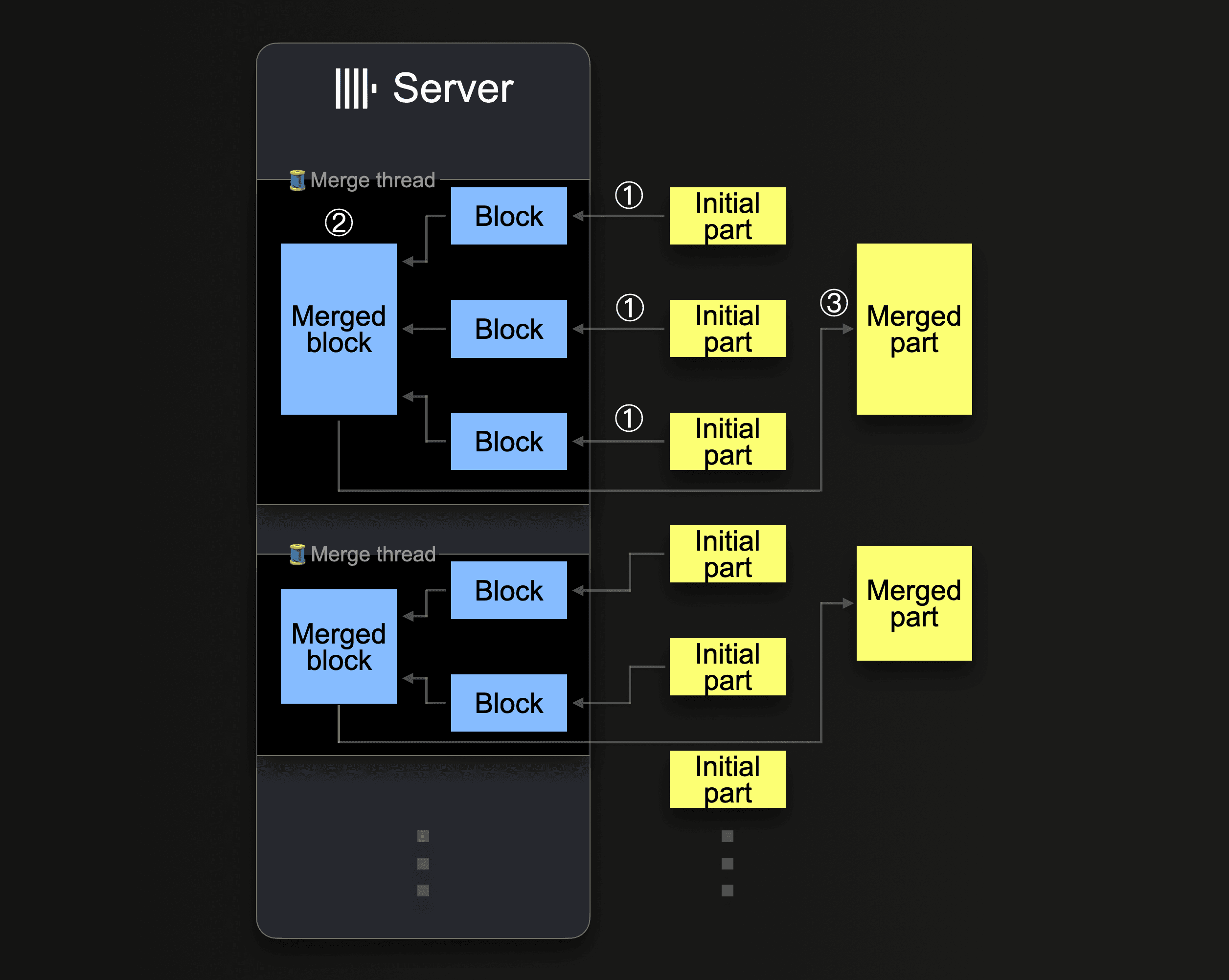
1 台の ClickHouse サーバーは、複数のバックグラウンドマージスレッドを使用して、同時にパートマージを実行します。各スレッドはループを実行します。
CPU コア数と RAM サイズを増やすと、バックグラウンドマージのスループットが向上します。
より大きなパートにマージされたパートは inactive としてマークされ、設定可能な 分単位の時間が経過すると最終的に削除されます。時間の経過とともに、これによってマージされたパートのツリーが構築されます(これが MergeTree テーブルという名前の由来です)。
挿入の並列性
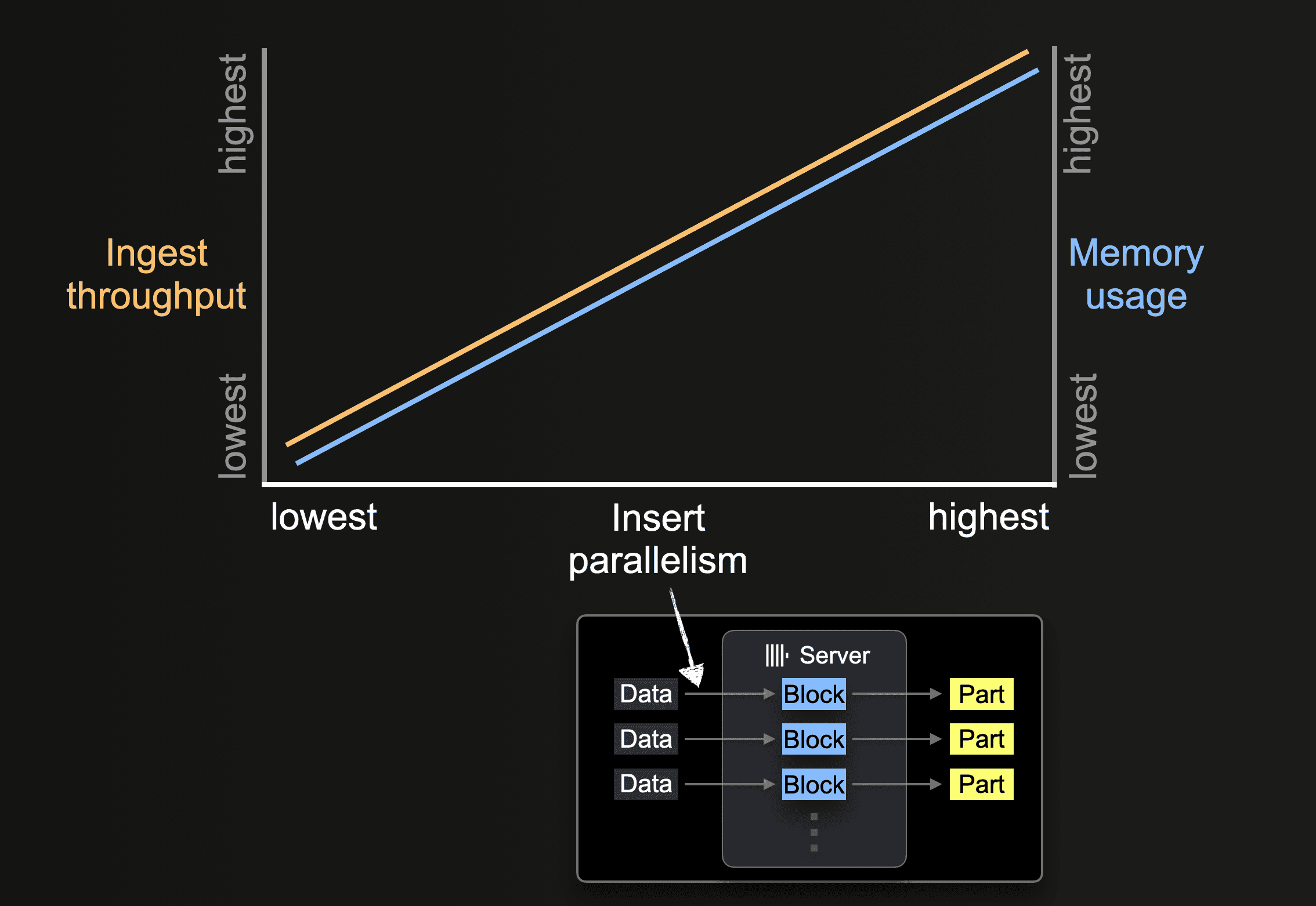
ClickHouse サーバーは、データを並列に処理して挿入できます。挿入の並列度は、ClickHouse サーバーの取り込みスループットとメモリ使用量に影響します。データを並列に読み込み・処理するにはより多くのメインメモリが必要ですが、データ処理が高速になるため取り込みスループットが向上します。
s3 のようなテーブル関数では、グロブパターンを使って読み込み対象ファイル名の集合を指定できます。グロブパターンが複数の既存ファイルにマッチする場合、ClickHouse はそれらのファイル間およびファイル内で読み取りを並列化し、サーバーごとに並列で実行される挿入スレッドを利用して、データをテーブルに並列挿入できます。
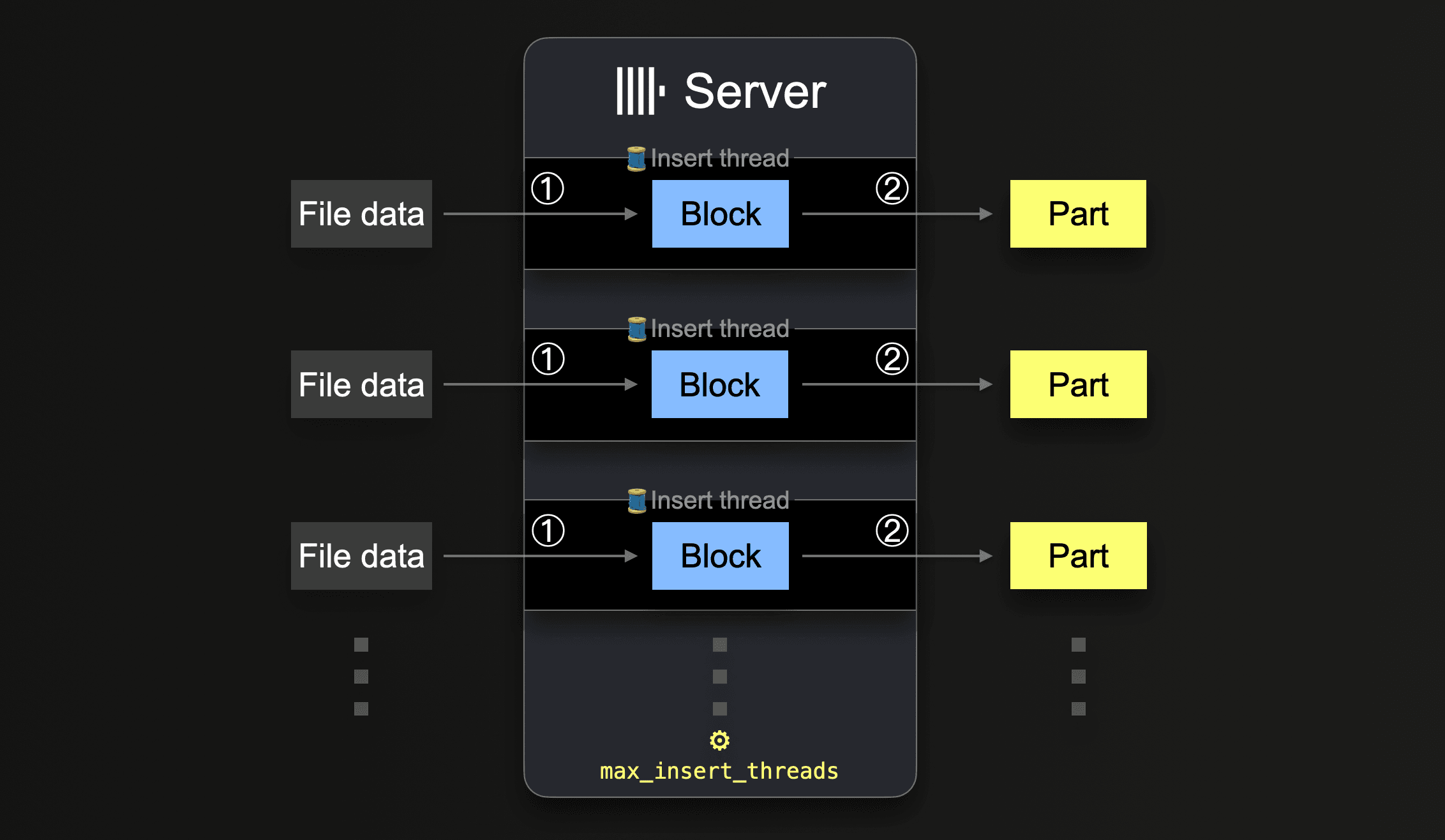
すべてのファイルのすべてのデータが処理されるまで、各挿入スレッドは次のループを実行します:
このような並列挿入スレッドの数は、max_insert_threads 設定で指定できます。デフォルト値は、オープンソース版 ClickHouse では 1、ClickHouse Cloud では 4 です。
大量のファイルがある場合、複数の挿入スレッドによる並列処理が有効に機能します。これにより、利用可能な CPU コアおよびネットワーク帯域幅(ファイルの並列ダウンロード)を十分に使い切ることができます。少数の大きなファイルだけをテーブルにロードするシナリオでは、ClickHouse は自動的に高いレベルのデータ処理並列性を実現し、各挿入スレッドごとに追加のリーダースレッドを生成して、大きなファイル内のより多くの別々の範囲を並列に読み取り(ダウンロード)することでネットワーク帯域幅の使用を最適化します。
s3 関数およびテーブルの場合、個々のファイルの並列ダウンロードは max_download_threads と max_download_buffer_size の値によって決まります。ファイルサイズが 2 * max_download_buffer_size より大きい場合にのみ、ファイルは並列でダウンロードされます。デフォルトでは、max_download_buffer_size は 10MiB に設定されています。場合によっては、各ファイルが単一スレッドによってダウンロードされるようにすることを目的として、このバッファサイズを 50 MB(max_download_buffer_size=52428800)まで安全に増やすことができます。これにより、各スレッドが行う S3 呼び出しに要する時間を短縮でき、その結果として S3 の待ち時間も短縮されます。さらに、並列読み取りには小さすぎるファイルについてスループットを向上させるために、ClickHouse はそのようなファイルを非同期に先読みすることでデータを自動的にプリフェッチします。
パフォーマンスの測定
S3 テーブル関数を使用するクエリのパフォーマンス最適化は、次の 2 つのケースで必要になります。1 つ目は、S3 上のデータをその場に置いたままクエリする場合、すなわちデータは元の形式のまま S3 に残し、ClickHouse の計算リソースのみを使用するアドホッククエリの場合、2 つ目は、S3 から ClickHouse の MergeTree テーブルエンジンにデータを挿入する場合です。特に明記がない限り、以下の推奨事項は両方のシナリオに適用されます。
ハードウェア規模の影響
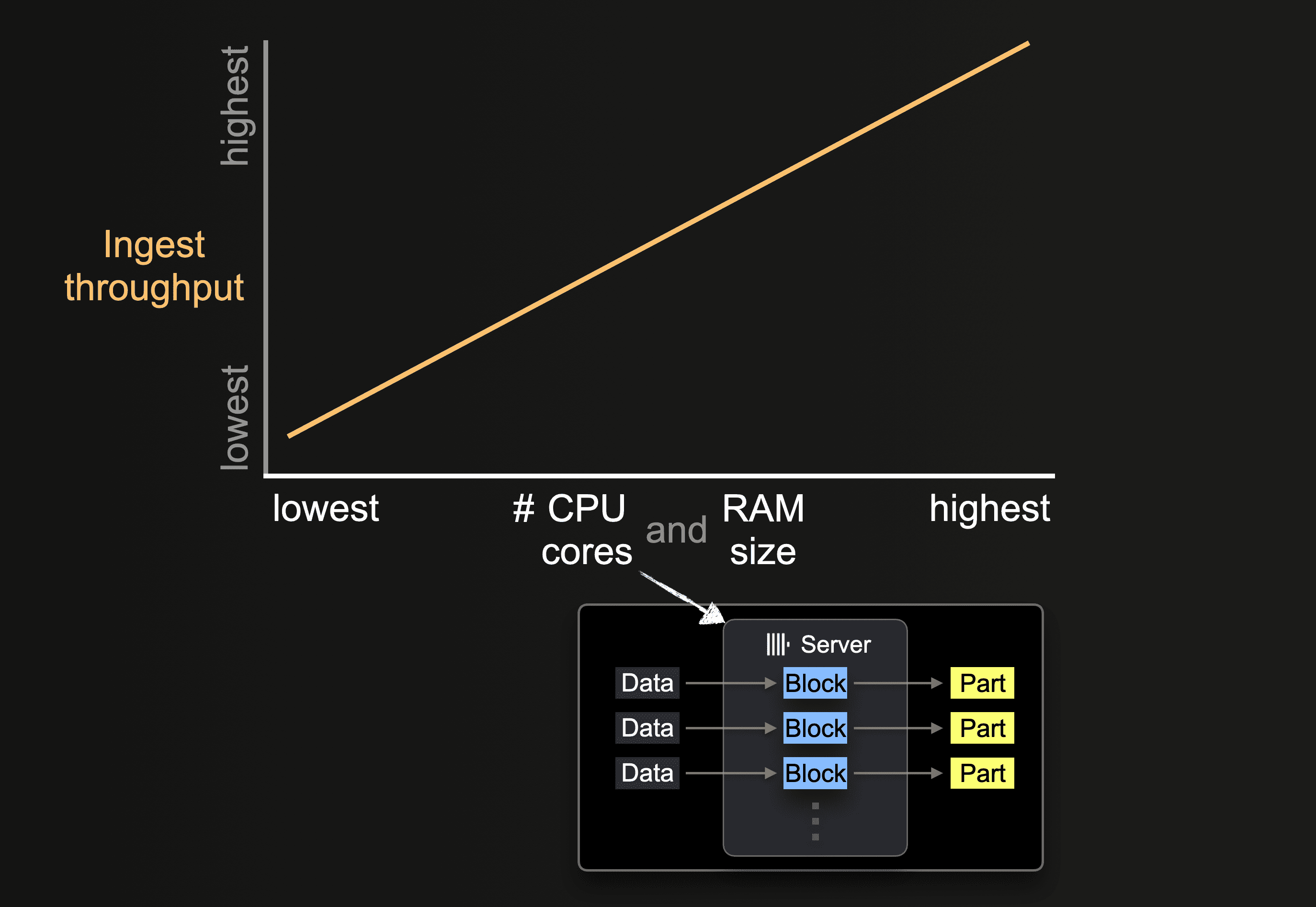
利用可能な CPU コア数と RAM 容量は、次の点に影響します。
- サポートされるパーツの初期サイズ
- 可能な挿入処理の並列度
- バックグラウンドでのパーツマージのスループット
したがって、取り込み全体のスループットにも影響します。
リージョンのローカリティ
バケットが ClickHouse インスタンスと同じリージョンに存在することを確認してください。この簡単な最適化により、特に ClickHouse インスタンスを AWS のインフラストラクチャ上にデプロイしている場合、スループットが大幅に向上する可能性があります。
フォーマット
ClickHouse は、s3 関数および S3 エンジンを使用して、S3 バケットに保存されたファイルを サポートされているフォーマット で読み取ることができます。元のファイルを直接読み取る場合、これらのフォーマットにはいくつかの明確な利点があります。
- Native、Parquet、CSVWithNames、TabSeparatedWithNames のようにカラム名がエンコードされているフォーマットでは、ユーザーが
s3関数にカラム名を指定する必要がないため、クエリが簡潔になります。カラム名からこの情報を推論できます。 - フォーマットごとに、読み書きスループットの観点で性能が異なります。Native と Parquet はすでにカラム指向であり、よりコンパクトであるため、読み取り性能の点で最適なフォーマットです。Native フォーマットはさらに、ClickHouse がメモリ内にデータを格納する方法と整合しているため、データが ClickHouse にストリーミングされる際の処理オーバーヘッドを削減できます。
- ブロックサイズは、大きなファイルの読み取りレイテンシにしばしば影響します。これは、たとえば先頭 N 行だけを返すなど、データをサンプリングする場合に顕著です。CSV や TSV のようなフォーマットでは、行の集合を返すためにファイルをパースする必要があります。Native や Parquet のようなフォーマットでは、この結果としてより高速なサンプリングが可能になります。
- 各圧縮フォーマットには一長一短があり、多くの場合、圧縮率と速度、および圧縮・解凍それぞれの性能のバランスを取ります。CSV や TSV のような元のファイルを圧縮する場合、lz4 は圧縮率を犠牲にする代わりに、最速の解凍性能を提供します。Gzip は一般的に、読み取り速度がわずかに低下する代わりに、より高い圧縮率を実現します。Xz はこれをさらに推し進め、通常は最も高い圧縮率を提供しますが、圧縮および解凍の性能は最も低くなります。エクスポートする場合、Gz と lz4 は概ね同程度の圧縮速度を提供します。これを接続速度と比較して検討してください。解凍や圧縮が高速になることによる利点は、S3 バケットへの接続が遅いと簡単に相殺されてしまいます。
- Native や Parquet のようなフォーマットでは、通常、圧縮のオーバーヘッドを正当化できません。これらのフォーマットは本質的にコンパクトであるため、データサイズ削減の効果は小さいことが多いです。圧縮および解凍に費やす時間は、ネットワーク転送時間を相殺することはほとんどありません。特に S3 はグローバルに利用可能であり、高いネットワーク帯域幅を持つため、なおさらです。
例となるデータセット
さらなる最適化の可能性を示すために、ここでは Stack Overflow データセットの投稿 を利用し、このデータに対するクエリおよび書き込みパフォーマンスの両方を最適化していきます。
このデータセットは 189 個の Parquet ファイルで構成されており、2008 年 7 月から 2024 年 3 月までの各月につき 1 ファイルずつ存在します。
上記の推奨事項 に従い、パフォーマンス向上のために Parquet を使用し、すべてのクエリをバケットと同じリージョンに配置された ClickHouse クラスター上で実行しています。このクラスターは 3 ノードで構成され、各ノードは 32GiB の RAM と 8 vCPU を備えています。
チューニングなしの状態で、このデータセットを MergeTree テーブルエンジンに挿入する際のパフォーマンスと、最も多く質問を投稿しているユーザーを算出するクエリを実行する際のパフォーマンスを示します。これら 2 つのクエリはいずれも、意図的にデータのフルスキャンを必要とします。
この例では、数行のみを返しています。大量のデータをクライアントに返す SELECT クエリのパフォーマンスを測定する場合は、クエリで null format を利用するか、結果を Null engine に送るようにしてください。これにより、クライアントが過剰なデータ量で圧迫されたり、ネットワークが飽和したりすることを防げます。
クエリを実行して読み取りを行う際、同じクエリを繰り返し実行した場合と比べて、最初のクエリが遅く見えることがよくあります。これは、S3 側のキャッシュと ClickHouse Schema Inference Cache の両方によるものです。後者はファイルに対して推論されたスキーマを保存するため、後続のアクセスではスキーマ推論ステップを省略でき、その結果クエリ時間を短縮できます。
読み取りにスレッドを使用する
S3 上での読み取りパフォーマンスは、ネットワーク帯域幅やローカル I/O によって制限されない限り、コア数に比例してスケールします。スレッド数を増やすと追加のメモリオーバーヘッドも発生するため、ユーザーはこれを理解しておく必要があります。読み取りスループットを向上させるために、次の項目を調整できます。
- 通常、
max_threadsのデフォルト値、すなわちコア数で十分です。クエリで使用されるメモリ量が多く、これを削減する必要がある場合、あるいは結果に対するLIMITが小さい場合には、この値をより小さく設定できます。メモリに十分な余裕がある環境では、S3 からの読み取りスループット向上の可能性を確認するために、この値を増やしてみることもできます。一般的に、これはコア数が少ないマシン、すなわち 10 未満の場合にのみ有益です。さらなる並列化によるメリットは、ネットワークや CPU の競合など、他のリソースがボトルネックとして働くにつれて通常は減少します。 - ClickHouse 22.3.1 より前のバージョンでは、
s3関数またはS3テーブルエンジンを使用した場合にのみ、複数ファイルにまたがる読み取りが並列化されていました。このため、ユーザーは最適な読み取り性能を達成するために、S3 上のファイルをチャンクに分割し、glob パターンを使って読み取る必要がありました。後続のバージョンでは、ファイル内でのダウンロードも並列化されるようになっています。 - スレッド数が少ないシナリオでは、
remote_filesystem_read_methodを "read" に設定して、S3 からのファイル読み取りを同期的に実行することでメリットを得られる場合があります。 s3関数およびテーブルにおいて、個々のファイルの並列ダウンロードは、max_download_threadsとmax_download_buffer_sizeの値によって決定されます。max_download_threadsは使用されるスレッド数を制御しますが、ファイルが並列にダウンロードされるのは、そのサイズが 2 *max_download_buffer_sizeより大きい場合のみです。デフォルトでは、max_download_buffer_sizeは 10MiB に設定されています。場合によっては、このバッファサイズを安全に 50 MB (max_download_buffer_size=52428800) まで増やし、小さなファイルが単一スレッドによってのみダウンロードされるようにすることができます。これにより、各スレッドが S3 呼び出しに費やす時間を減らし、S3 の待機時間も短縮できます。具体例については このブログ記事 を参照してください。
パフォーマンス改善のために変更を加える前に、適切に計測していることを確認してください。S3 API コールはレイテンシに敏感であり、クライアント側のタイミングに影響を与える可能性があるため、パフォーマンスメトリクスには system.query_log などのクエリログを使用してください。
先ほどのクエリを例に取ると、max_threads を 16 に倍増させることで(デフォルトの max_thread はノード上のコア数)、メモリ消費が増える代わりに読み取りクエリ性能を 2 倍に向上させることができます。max_threads をそれ以上増やしても、以下に示すように効果は逓減します。
INSERT におけるスレッド数とブロックサイズのチューニング
インジェスト性能を最大化するには、(1) INSERT のブロックサイズ、(2) INSERT の並列度を、(3) 利用可能な CPU コア数と RAM 容量に基づいて選択・設定する必要があります。まとめると次のとおりです。
- INSERT のブロックサイズ を大きく設定すればするほど、ClickHouse が作成しなければならないパーツの数が減り、必要となる ディスクファイル I/O とバックグラウンドマージ の回数も減少します。
- 並列 INSERT スレッド数 を多く設定すればするほど、データはより高速に処理されます。
これら 2 つの性能要因の間には、互いに相反するトレードオフ(さらにバックグラウンドでのパーツマージとのトレードオフ)があります。ClickHouse サーバーで利用可能なメインメモリ量には上限があります。ブロックを大きくするとメインメモリの使用量が増えるため、利用可能な並列 INSERT スレッド数が制限されます。逆に、並列 INSERT スレッド数を増やすと、メモリ内で同時に生成される INSERT ブロック数が増えるため、より多くのメインメモリを必要とします。その結果、設定できる INSERT ブロックサイズが制限されます。さらに、INSERT スレッドとバックグラウンドマージスレッドの間でリソース競合が発生する可能性があります。INSERT スレッド数を多く設定すると、(1) マージ対象となるパーツがより多く作成され、(2) バックグラウンドマージスレッドが利用できる CPU コアとメモリ領域が奪われます。
これらのパラメータの動作がパフォーマンスとリソースにどのような影響を与えるかについての詳細な説明は、このブログ記事 を参照してください。このブログ記事で説明されているように、チューニングには 2 つのパラメータ間の慎重なバランス調整が関わります。このような網羅的なテストを行うのは実務上困難な場合が多いため、要約として次の推奨事項があります。
この式を使うと、min_insert_block_size_rows を 0(行ベースのしきい値を無効にする)に設定しつつ、max_insert_threads を任意の値に設定し、min_insert_block_size_bytes を上記の式から計算された結果に設定できます。
先ほどの Stack Overflow の例にこの式を適用します。
max_insert_threads=4(ノードあたり 8 コア)peak_memory_usage_in_bytesは 32 GiB(ノードリソースの 100%)、すなわち34359738368バイトmin_insert_block_size_bytes=34359738368/(3*4) = 2863311530
示したように、これらの設定を調整することで、挿入パフォーマンスは 33% 以上向上しました。単一ノードでのパフォーマンスをさらに向上できるかどうかは、読者の検証に委ねます。
リソースおよびノードによるスケーリング
リソースおよびノードによるスケーリングは、読み取りクエリと挿入クエリの両方に適用されます。
垂直スケーリング
これまでのすべてのチューニングとクエリは、ClickHouse Cloud クラスター内の単一ノードのみを使用していました。実際には、多くの場合、複数の ClickHouse ノードを利用できるでしょう。まずは垂直スケーリングを行い、コア数に応じて S3 のスループットを線形に向上させることを推奨します。以前の挿入クエリと読み取りクエリを、リソースを 2 倍(64GiB、16 vCPU)にした、より大きな ClickHouse Cloud ノード上で適切な設定とともに再実行すると、どちらもおおよそ 2 倍の速度で実行されます。
個々のノードはネットワークや S3 の GET リクエストによってボトルネックとなる場合もあり、その結果、垂直方向の性能が線形にはスケールしなくなります。
水平スケーリング
最終的には、ハードウェアの入手性やコスト効率の観点から、水平スケーリングが必要になることがよくあります。ClickHouse Cloud では、本番クラスターは少なくとも 3 ノードで構成されています。そのため、挿入処理にすべてのノードを利用したい場合もあるでしょう。
S3 からの読み取りにクラスターを利用するには、Utilizing Clusters で説明されているように s3Cluster 関数を使用する必要があります。これにより、読み取りをノード間で分散できます。
挿入クエリを最初に受信したサーバーは、まずグロブパターンを解決してから、一致した各ファイルの処理を自分自身および他のサーバーに動的に割り当てます。
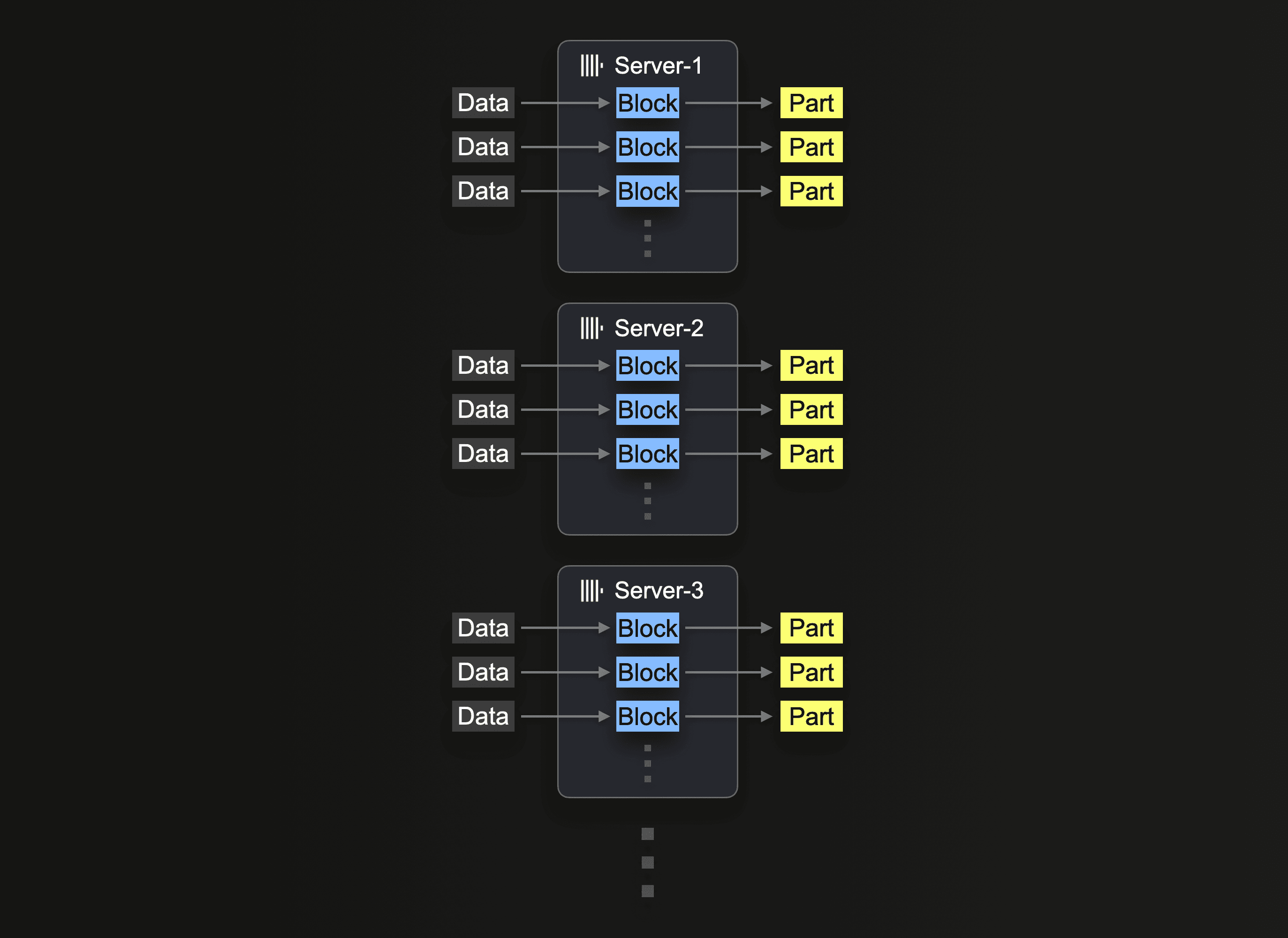
以前の読み取りクエリを再度実行し、s3Cluster を使用するようにクエリを調整して、ワークロードを 3 ノードに分散します。ClickHouse Cloud では、default クラスターを参照することで、これは自動的に実行されます。
Utilizing Clusters で述べたように、この処理はファイル単位で分散されます。この機能の恩恵を受けるには、ユーザーは十分な数のファイル、つまり少なくともノード数を上回るファイル数を用意する必要があります。
同様に、単一ノード向けに前述で調整した改善済みの設定を使用して、挿入クエリも分散実行できます。
読者は、ファイル読み取りのクエリ性能は向上した一方で、挿入性能は改善していないことに気付くでしょう。デフォルトでは、読み取りは s3Cluster を使用して分散されますが、挿入はイニシエーターノードに対して行われます。これは、各ノードで読み取りが実行されても、結果の行は分散のためにイニシエーターノードへルーティングされることを意味します。高スループットなシナリオでは、これがボトルネックとなる可能性があります。これに対処するには、s3cluster 関数に対してパラメーター parallel_distributed_insert_select を設定します。
これを parallel_distributed_insert_select=2 に設定すると、各ノード上の分散エンジンの基になるテーブルに対して、SELECT と INSERT が各分片で実行されるようになります。
予想どおり、これにより挿入性能は 3 倍低下します。
さらなるチューニング
重複排除の無効化
挿入操作は、タイムアウトなどのエラーにより失敗することがあります。挿入が失敗した場合、データが実際に挿入されたかどうかは分からないことがあります。クライアント側で安全に挿入を再試行できるようにするため、ClickHouse Cloud のような分散デプロイメントでは、デフォルトで ClickHouse がそのデータがすでに正常に挿入されているかどうかを確認しようとします。挿入されたデータが重複とマークされた場合、ClickHouse はそれを宛先テーブルに挿入しません。ただし、ユーザー側には、あたかもデータが通常どおり挿入されたかのように、操作成功ステータスが返されます。
この挙動は、クライアントからのデータロードやバッチ処理では挿入時のオーバーヘッドがかかるものの妥当ですが、オブジェクトストレージ上のデータに対して INSERT INTO SELECT を実行する場合には不要な場合があります。挿入時にこの機能を無効にすることで、以下に示すようにパフォーマンスを向上できます。
挿入時の最適化
ClickHouse では、optimize_on_insert 設定は挿入処理中にデータパーツをマージするかどうかを制御します。有効な場合(デフォルトで optimize_on_insert = 1)、小さなパーツは挿入時により大きなパーツにマージされ、読み取る必要があるパーツ数を減らすことでクエリ性能を向上させます。ただし、このマージ処理は挿入処理にオーバーヘッドを追加するため、高スループットの挿入を遅くする可能性があります。
この設定を無効化すると(optimize_on_insert = 0)、挿入時のマージがスキップされ、特に小さな挿入が頻繁に発生する場合にデータを書き込みやすくなります。マージ処理はバックグラウンドに延期されるため、挿入性能は向上しますが、その完了までの間は小さなパーツ数が一時的に増加し、バックグラウンドマージが完了するまでクエリが遅くなる可能性があります。この設定は、挿入性能を優先し、後でバックグラウンドマージ処理によって効率的に最適化できる場合に最適です。以下に示すように、この設定を無効化することで挿入スループットを向上できます。
その他の注意事項
- メモリが制約された環境では、S3 へのデータ挿入時に
max_insert_delayed_streams_for_parallel_writeの値を下げることを検討してください。
