S3 テーブル関数
s3 テーブル関数を使用すると、S3 互換ストレージとの間でファイルの読み取りと書き込みを行えます。構文の概要は次のとおりです。
- path — ファイルへのパスを含むバケット URL。読み取り専用モードでは、次のワイルドカードをサポートします:
*,?,{abc,def}、{N..M}。ここで、N、Mは数値、'abc'、'def'は文字列です。詳細については、path でのワイルドカードの使用 に関するドキュメントを参照してください。 - format — ファイルのフォーマット。
- structure — テーブルの構造。フォーマットは
'column1_name column1_type, column2_name column2_type, ...'です。 - compression — このパラメータは省略可能です。サポートされる値:
none,gzip/gz,brotli/br,xz/LZMA,zstd/zst。デフォルトでは、ファイル拡張子から圧縮方式を自動判別します。
準備
DESCRIBE ステートメントを使って ClickHouse から直接行えます。
DESCRIBE TABLEステートメントの出力を見ると、S3バケット内のこのデータを ClickHouse がどのように自動的に推論するかがわかります。また、gzip の圧縮フォーマットも自動的に認識して解凍することがわかります:
MergeTree テーブルを用意します。以下のステートメントは、デフォルトデータベースに trips という名前のテーブルを作成します。ここでは、先ほど推定したデータ型の一部を変更している点に注意してください。特に、Nullable() データ型修飾子は使用していません。これは、不要な追加データの保存や、余分なパフォーマンスオーバーヘッドを招く可能性があるためです。
pickup_dateフィールドでパーティション化を使用している点に注目してください。通常、パーティションキーはデータ管理のために使いますが、この後、このキーを使って S3 への書き込みを並列化します。
このタクシーデータセットの各エントリは、1 回のタクシー乗車に対応しています。この匿名化データは、S3 バケット https://datasets-documentation.s3.eu-west-3.amazonaws.com/ の nyc-taxi フォルダ以下に、圧縮された 2,000 万件のレコードとして格納されています。データは TSV フォーマットで、1 ファイルあたり約 100 万行です。
S3 からデータを読み取る
TabSeparatedWithNames フォーマットでは1行目にカラム名が含まれているため、カラムを列挙する必要がないことに注意してください。CSV や TSV などの他のフォーマットでは、このクエリに対して c1、c2、c3 などの自動生成されたカラムが返されます。
クエリではさらに、バケットパスとファイル名の情報をそれぞれ提供する _path や _file などの仮想カラムも利用できます。たとえば次のとおりです。
MergeTree テーブルにインポートしてください。
clickhouse-local の使用
clickhouse-local プログラムを使用すると、ClickHouseサーバーをデプロイおよび設定しなくても、ローカルファイルに対して高速な処理を実行できます。s3 テーブル関数を使用するあらゆるクエリは、このユーティリティで実行できます。例:
S3 からデータを挿入する
s3 関数とシンプルな INSERT ステートメントを組み合わせます。ターゲットテーブルが必要な構造を持っているため、カラムを列挙する必要はありません。ただし、その場合はカラムがテーブルの DDL ステートメントで指定された順序で並んでいる必要があります。カラムは SELECT 句内での位置に基づいて対応付けられます。1,000 万行すべての挿入には、ClickHouse インスタンスによっては数分かかる場合があります。以下では、応答を速くするために 100 万行を挿入します。必要に応じて、LIMIT 句またはカラムの選択を調整し、データの一部だけを取り込んでください:
ClickHouse Local を使用したリモート挿入
clickhouse-local を使って S3 のデータを挿入できる可能性があります。以下の例では、S3 バケットから読み取り、remote 関数を使って ClickHouse に挿入します。
これを安全なSSL接続で実行するには、
remoteSecure 関数を使用します。データのエクスポート
s3 テーブル関数を使用すると、S3 上のファイルに書き込めます。これには適切な権限が必要です。必要な認証情報はリクエスト内で渡しますが、その他のオプションについては 認証情報の管理 のページを参照してください。
以下の簡単な例では、テーブル関数をソースではなく宛先として使用します。ここでは、trips テーブルから 10,000 行をバケットにストリーミングし、lz4 圧縮と CSV の出力形式を指定しています。
s3 関数ではカラムを指定する必要もありません。これは SELECT から推論されます。
大きなファイルの分割
INSERT コマンドを複数回実行し、データの一部ずつを対象にすることもできます。ClickHouse では、PARTITION キーを使ってファイルを自動的に分割できます。
以下の例では、rand() 関数の値を 10 で割った余りを使って 10 個のファイルを作成しています。生成されたパーティション ID がファイル名の中で参照されている点に注目してください。これにより、trips_0.csv.lz4、trips_1.csv.lz4 などのように、数値の接尾辞が付いた 10 個のファイルが生成されます。
payment_type はカーディナリティが 5 の自然なパーティションキーです。
クラスターの活用
INSERT INTO SELECT クエリの実行時に分散テーブルに INSERT することで、リソース負荷をある程度軽減することはできますが、それでもデータの読み取り、パース、処理は単一ノードに集中したままです。この課題に対処し、読み取りを水平方向にスケールできるようにするために、s3Cluster 関数があります。
クエリを受け取るノードはイニシエーターと呼ばれ、クラスター内のすべてのノードへの接続を確立します。どのファイルを読み取る必要があるかを決定する glob パターンは、ファイルの集合に展開されます。イニシエーターはそれらのファイルをクラスター内のノードに分配し、それらのノードは worker として動作します。各 worker は読み取りを完了するたびに、次に処理するファイルを要求します。この仕組みにより、読み取りを水平方向にスケールできます。
s3Cluster 関数のフォーマットは単一ノード版と同じですが、worker ノードを示す対象クラスターの指定が必要です。
cluster_name— リモートおよびローカルのサーバーへのアドレス群と接続パラメーターのセットを構築するために使用される、クラスター名。source— 1 つのファイルまたは複数のファイルへの URL。読み取り専用モードでは、次のワイルドカードをサポートします:*,?,{'abc','def'}および{N..M}。ここで、N、M は数値、abc、def は文字列です。詳細は Wildcards In Path を参照してください。access_key_idandsecret_access_key— 指定したエンドポイントで使用する認証情報を指定するキーです。省略可能です。format— ファイルの フォーマット。structure— テーブルの構造。形式は ‘column1_name column1_type, column2_name column2_type, …’ です。
s3 関数と同様に、バケット がセキュアでない場合や、環境を通じてセキュリティを定義している場合 (たとえば IAM roles) には、認証情報は省略可能です。ただし、s3 function とは異なり、22.3.1 以降は structure をリクエスト内で指定する必要があります。つまり、スキーマは推論されません。
この関数は、ほとんどの場合 INSERT INTO SELECT の一部として使用されます。この場合、多くは分散テーブルへの insert になります。以下に、trips_all が分散テーブルである簡単な例を示します。このテーブルは events クラスターを使用していますが、読み取りと書き込みに使用されるノードの整合性は要件ではありません:
s3cluster 関数でパラメーター parallel_distributed_insert_select を設定してください。
S3 テーブルエンジン
s3 関数を使うと、S3 に保存されたデータに対してアドホッククエリを実行できますが、構文が冗長になりがちです。S3 テーブルエンジンを使えば、バケットの URL や認証情報を何度も繰り返し指定する必要がなくなります。この煩雑さを解消するために、ClickHouse では S3 テーブルエンジンを提供しています。
path— ファイルへのパスを含むバケット URL。読み取り専用モードでは、*、?、{abc,def}、{N..M}のワイルドカードをサポートします。ここで、N、M は数値、‘abc’、‘def’ は文字列です。詳細は、こちらを参照してください。format— ファイルのフォーマット。aws_access_key_id,aws_secret_access_key- AWS アカウントユーザーの長期認証情報です。これらを使用してリクエストを認証できます。このパラメーターは省略可能です。認証情報が指定されていない場合は、設定ファイルの値が使用されます。詳細は、認証情報の管理を参照してください。compression— 圧縮の種類。サポートされる値: none、gzip/gz、brotli/br、xz/LZMA、zstd/zst。このパラメーターは省略可能です。デフォルトでは、ファイル拡張子に基づいて圧縮方式を自動判別します。
データの読み込み
https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/ バケット内の先頭 10 個の TSV ファイルを使って、trips_raw という名前のテーブルを作成します。各ファイルには 100 万行ずつ含まれています。
{0..9} パターンを使用している点に注目してください。作成後は、このテーブルを他のテーブルと同様にクエリできます。
データの挿入
S3 テーブルエンジンは並列読み取りをサポートしています。書き込みがサポートされるのは、テーブル定義に glob パターンが含まれていない場合のみです。したがって、上記のテーブルでは書き込みはできません。
書き込みを試すために、書き込み可能な S3 バケットを指すテーブルを作成します。
- 設定
s3_create_new_file_on_insert=1を指定します。これにより、insert のたびに新しいファイルが作成されます。各ファイルの末尾には数値の接尾辞が追加され、insert 操作のたびに単調増加します。上記の例では、次の insert で trips_1.bin ファイルが作成されます。 - 設定
s3_truncate_on_insert=1を指定します。これによりファイルは切り詰められ、完了後は新たに挿入された行だけが含まれるようになります。
s3_truncate_on_insert が優先されます。
S3 テーブルエンジンに関する注意点をいくつか示します。
- 従来の
MergeTreeファミリーのテーブルとは異なり、S3テーブルを drop しても基盤となるデータは削除されません。 - このテーブルタイプで使用できる設定の一覧は こちら を参照してください。
- このエンジンを使用する際は、次の制約に注意してください。
- ALTER クエリはサポートされていません
- SAMPLE 操作はサポートされていません
- 索引の概念がないため、プライマリ索引やスキップ索引はありません。
認証情報の管理
s3 関数または S3 テーブル定義で認証情報を指定していました。これはたまに使う程度であれば許容できるかもしれませんが、本番環境では、より明示的でない認証の仕組みが求められます。これに対応するため、ClickHouse にはいくつかの方法があります。
-
config.xml または conf.d 配下の同等の設定ファイルに接続情報を指定します。以下は、debian パッケージを使用してインストールした場合を想定したサンプルファイルの内容です。
これらの認証情報は、上記のエンドポイントが要求された URL と完全なプレフィックス一致となるすべてのリクエストで使用されます。また、この例では、アクセスキーとシークレットキーの代わりに認可ヘッダーを指定できる点にも注目してください。サポートされている設定の完全な一覧はこちらにあります。
-
上の例では、設定パラメーター
use_environment_credentialsが利用可能であることも示しています。この設定パラメーターは、s3レベルでグローバルに設定することもできます。この設定を有効にすると、環境から S3 の認証情報を取得するようになり、IAM ロールを通じたアクセスが可能になります。具体的には、次の順序で取得が行われます。- 環境変数
AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY、AWS_SESSION_TOKENを参照 - $HOME/.aws を確認
- AWS Security Token Service 経由で取得した一時認証情報。つまり、
AssumeRoleAPI 経由 - ECS 環境変数
AWS_CONTAINER_CREDENTIALS_RELATIVE_URIまたはAWS_CONTAINER_CREDENTIALS_FULL_URI、およびAWS_ECS_CONTAINER_AUTHORIZATION_TOKENに認証情報があるか確認 - Amazon EC2 instance metadata 経由で認証情報を取得します。ただし、AWS_EC2_METADATA_DISABLED が true に設定されていない場合に限ります。
- これらと同じ設定は、同じプレフィックス一致ルールを使用して、特定のエンドポイントに対して設定することもできます。
- 環境変数
パフォーマンスの最適化
S3 ストレージのチューニング
Wide と Compact を採用しています。現在の実装では ClickHouse のデフォルトの挙動 (設定 min_bytes_for_wide_part および min_rows_for_wide_part で制御) を使用していますが、今後のリリースでは S3 では挙動が変わってくることが予想されます。たとえば、min_bytes_for_wide_part のデフォルト値を大きくすることで、より Compact フォーマットが選ばれやすくなり、その結果ファイル数を減らせます。S3 ストレージのみを使用する場合は、これらの設定の調整を検討するとよいでしょう。
S3 バックエンドの MergeTree
s3 関数と関連するテーブルエンジンを使うと、使い慣れた ClickHouse 構文で S3 上のデータをクエリできます。ただし、データ管理機能とパフォーマンスの面では制限があります。プライマリインデックスはサポートされておらず、no-cache も利用できず、ファイルへの insert はユーザーが管理する必要があります。
ClickHouse は、特にアクセス頻度の低いデータに対するクエリ性能がそれほど重要ではなく、ストレージとコンピュートを分離したい場合に、S3 が魅力的なストレージソリューションであると認識しています。そのため、MergeTree エンジンのストレージとして S3 を使用できるようになっています。これにより、S3 のスケーラビリティとコスト面での利点に加え、MergeTree エンジンの insert およびクエリ性能も活用できます。
ストレージ階層
ディスクの作成
config.xml を拡張するか、できれば conf.d 配下に新しいファイルを追加します。S3 ディスクの宣言例を以下に示します。
ストレージポリシーの作成
テーブルの作成
テーブルの変更
<path> パラメーターで設定された 1 つのディスクだけで構成されています。なお、ボリューム名とディスク名は変わりません。テーブルに新たに挿入されるデータは、move_factor * disk_size に達するまでデフォルトディスク上に配置され、そこに達するとデータは S3 に移動されます。
レプリケーションの扱い
ReplicatedMergeTree テーブルエンジンを使用することで実現できます。詳細については、S3 Object Storage を使用して 1 つの分片を 2 つの AWS リージョンにまたがってレプリケートする ガイドを参照してください。
読み取りと書き込み
- デフォルトでは、クエリ処理パイプラインの各段階で使用できるクエリ処理スレッドの最大数は、CPU コア数と同じです。段階によって並列化のしやすさが異なるため、この値は上限を示します。データはディスクからストリーミングされるため、複数のクエリ処理段階が同時に実行されることがあります。そのため、1 つのクエリで実際に使用されるスレッド数はこの値を超える場合があります。変更するには、設定 max_threads を使用します。
- S3 からの読み取りは、デフォルトで非同期です。この動作は設定
remote_filesystem_read_methodによって決まり、デフォルト値はthreadpoolです。リクエストを処理する際、ClickHouse はグラニュールをストライプ単位で読み取ります。各ストライプには多数のカラムが含まれる可能性があります。スレッドは、それぞれのグラニュールについてカラムを 1 つずつ読み取ります。これを同期的に行う代わりに、データを待つ前にすべてのカラムに対して先読みを行います。これにより、各カラムごとに同期的に待機する場合と比べて、パフォーマンスが大幅に向上します。ほとんどの場合、この設定を変更する必要はありません。詳しくは パフォーマンスの最適化 を参照してください。 - 書き込みは並列に実行され、ファイル書き込みスレッドは最大 100 本まで同時実行されます。デフォルト値が 1000 の
max_insert_delayed_streams_for_parallel_writeは、並列に書き込まれる S3 ブロブの数を制御します。書き込み対象の各ファイルにはバッファ (約 1MB) が必要なため、これは実質的に INSERT のメモリ消費量を制限します。server のメモリが少ない環境では、この値を下げるのが適切な場合があります。
S3オブジェクトストレージをClickHouseのディスクとして使用する
S3 バケットをディスクとして使用するように ClickHouse を設定する
- ストレージ構成を保存するため、ClickHouse の
config.dディレクトリに新しいファイルを作成します。
- ストレージ構成として以下を追加します。バケットパス、アクセスキー、シークレットキーは前の手順で使用したものに置き換えてください
<disks> タグ内の s3_disk および s3_cache は任意のラベルです。別の名前にすることもできますが、ディスクを参照するには、<policies> タグ内の <disk> タグでも同じラベルを使用する必要があります。
<S3_main> タグも任意で、ClickHouse でリソースを作成する際にストレージターゲットの識別子として使用されるポリシー名です。上記の設定は ClickHouse バージョン 22.8 以降向けです。古いバージョンを使用している場合は、データの保存 ドキュメントを参照してください。S3 の使用に関する詳細情報:
インテグレーションガイド: S3 バックエンドの MergeTree- ファイルの所有者を
clickhouseユーザーおよびグループに変更します
- 変更を反映するため、ClickHouseインスタンスを再起動します。
テスト
- ClickHouse client でログインします。以下のようになります
- 新しいS3ストレージポリシーを指定してテーブルを作成する
- テーブルが正しいストレージポリシーで作成されていることを確認します
- テーブルにテスト用の行を挿入する
- 行を表示する
- AWS コンソールでバケットに移動し、新しく作成したバケットとそのフォルダを選択します。 次のように表示されるはずです。
S3オブジェクトストレージを使用して、1つの分片を2つのAWSリージョンにまたがってレプリケートする
デプロイメントを計画する
ソフトウェアをインストール
ClickHouseサーバー ノード
ClickHouse をデプロイする
chnode1、chnode2 という名前です。
chnode1 は 1 つの AWS リージョンに、chnode2 は別のリージョンに配置します。
ClickHouse Keeper をデプロイする
keepernode1、keepernode2、keepernode3 という名前を付けています。keepernode1 は chnode1 と同じリージョンに、keepernode2 は chnode2 と同じリージョンにデプロイできます。keepernode3 はどちらのリージョンにもデプロイできますが、そのリージョン内の ClickHouse ノードとは異なるアベイラビリティゾーンに配置してください。
ClickHouse Keeper ノードでデプロイ手順を実行する際は、インストール手順を参照してください。
S3 バケットを作成
chnode1 と chnode2 を配置した各リージョンに、それぞれ 1 つずつ、計 2 つの S3 バケットを作成します。
バケットと IAM ロールの作成手順を順を追って確認したい場合は、Create S3 buckets and an IAM role を展開して、手順に従ってください。
S3 バケットと IAM ユーザーを作成する
S3 バケットと IAM ユーザーを作成する
この記事では、AWS IAM ユーザーの設定、S3 バケットの作成、および ClickHouse がそのバケットを S3 ディスクとして使用するための設定方法の基本について説明します。
必要なパーミッションの決定にあたっては、セキュリティチームと連携し、ここで示す内容を出発点として参考にしてください。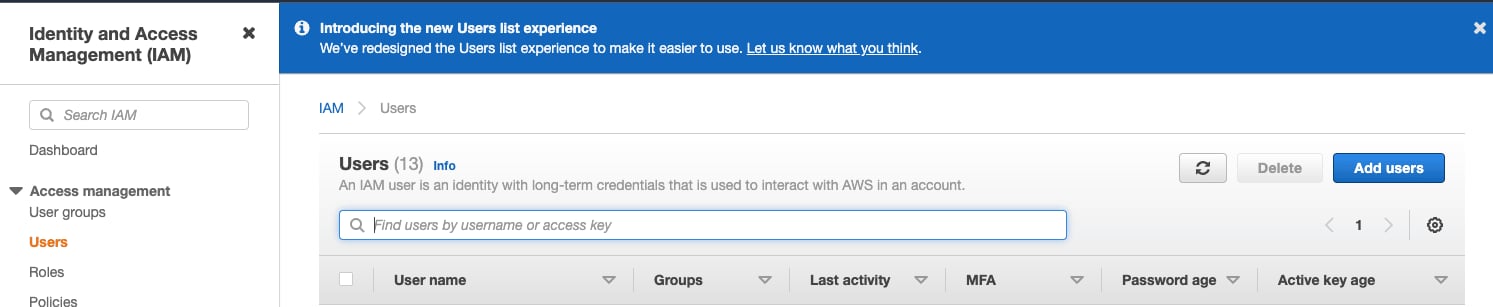



AWS IAM ユーザーの作成
以下の手順では、サービスアカウントユーザー (ログインユーザーではなく) を作成します。- AWS IAM Management Console にログインします。
-
Usersメニューで、Create userを選択します。
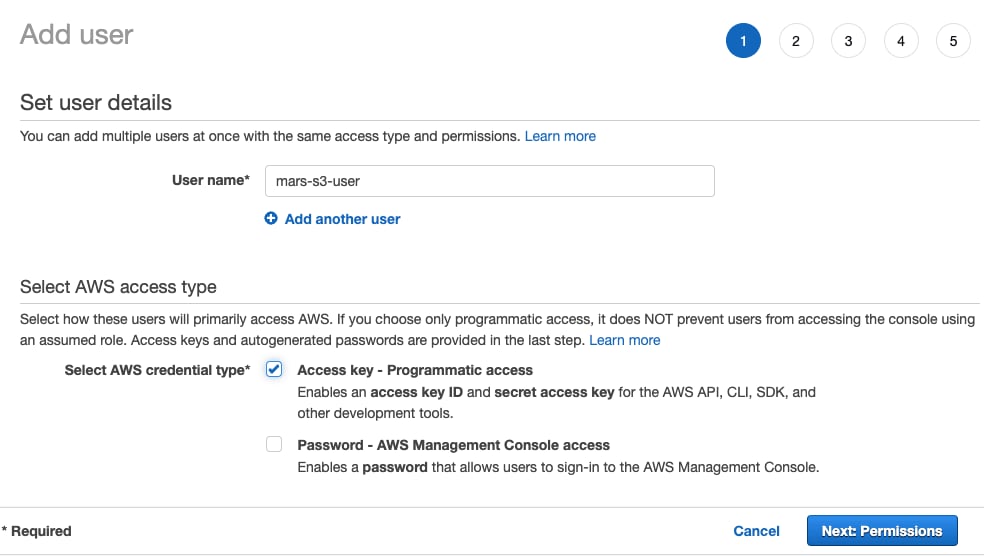
- ユーザー名を入力し、認証情報のタイプを
Access key - Programmatic accessに設定して、Next: Permissionsを選択します
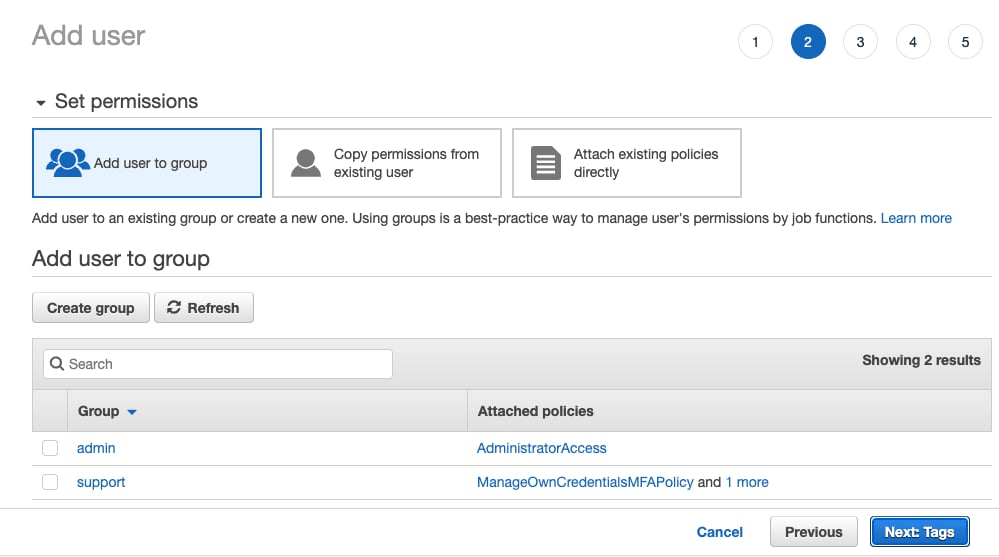
- ユーザーはどのグループにも追加せず、
Next: Tagsを選択します
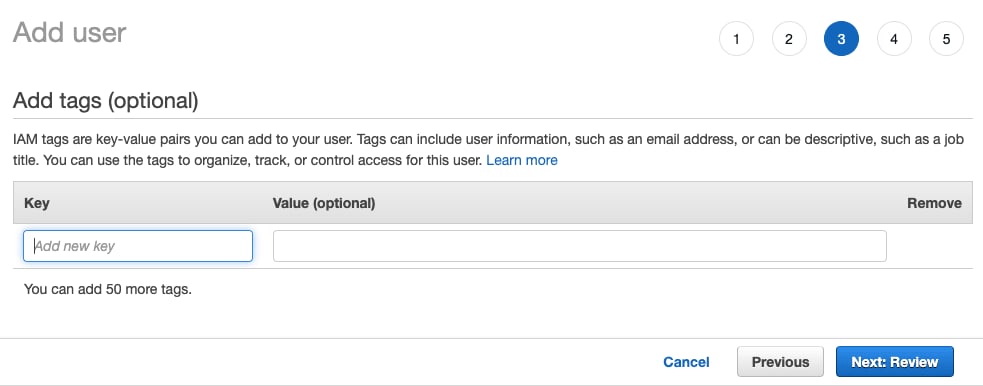
- タグを追加する必要がなければ、
Next: Reviewを選択します
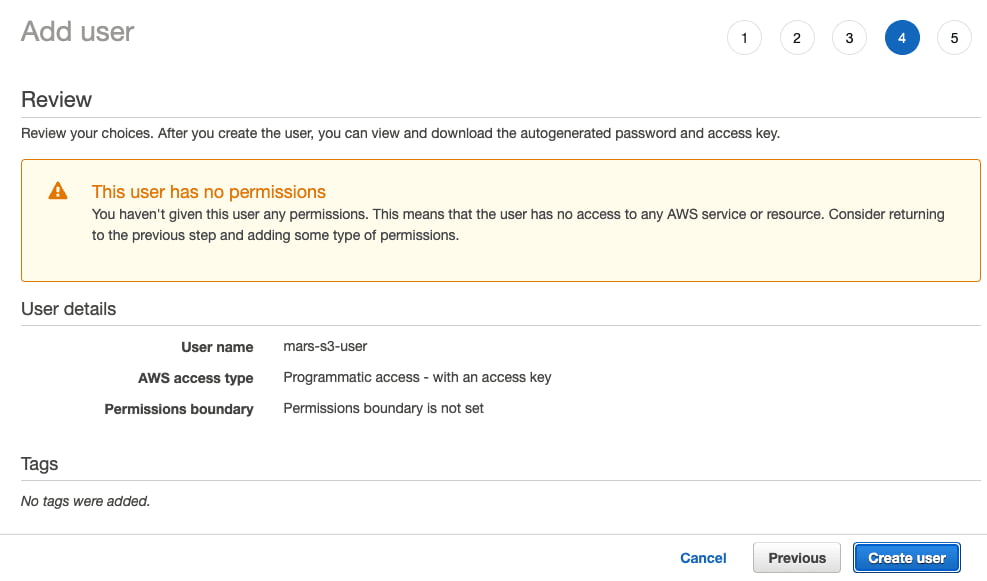
Create Userを選択します
ユーザーに権限がないことを示す警告メッセージは無視してかまいません。次のセクションで、そのユーザーにバケットへの権限を付与します
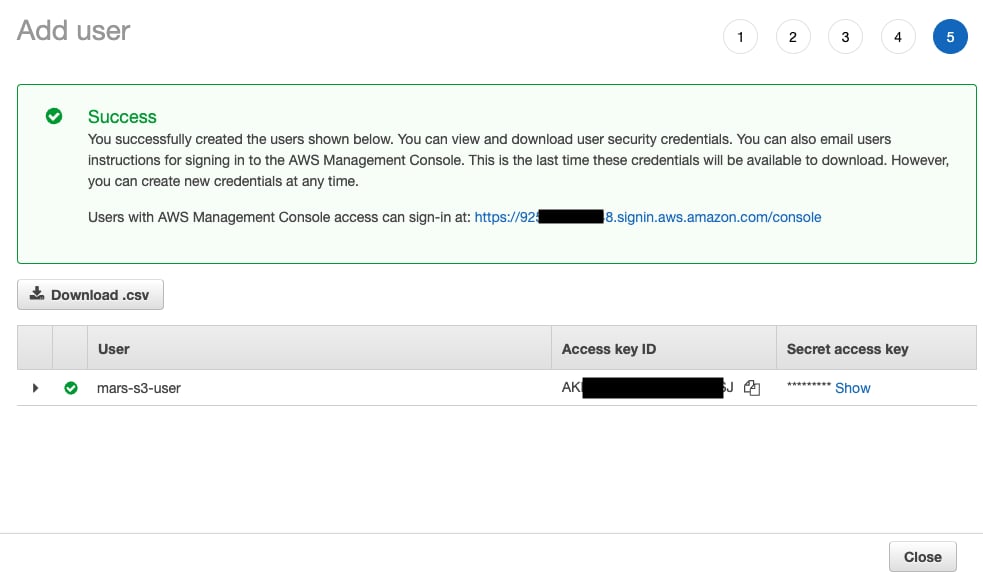
- ユーザーが作成されました。
showをクリックし、アクセスキーとシークレットキーをコピーします。
キーは必ず別の場所に保存してください。シークレットアクセスキーが表示されるのはこのときだけです。
- 「close」をクリックし、続いてユーザー一覧画面でそのユーザーを見つけます。
- ARN (Amazon Resource Name) をコピーし、バケットのアクセスポリシーを設定する際に使用できるよう保存します。
S3バケットの作成
- S3 バケットのセクションで、
Create bucketを選択します
- バケット名を入力し、他のオプションはそのままにします
バケット名は、組織内だけでなくAWS全体で一意である必要があります。そうでない場合は、エラーになります。
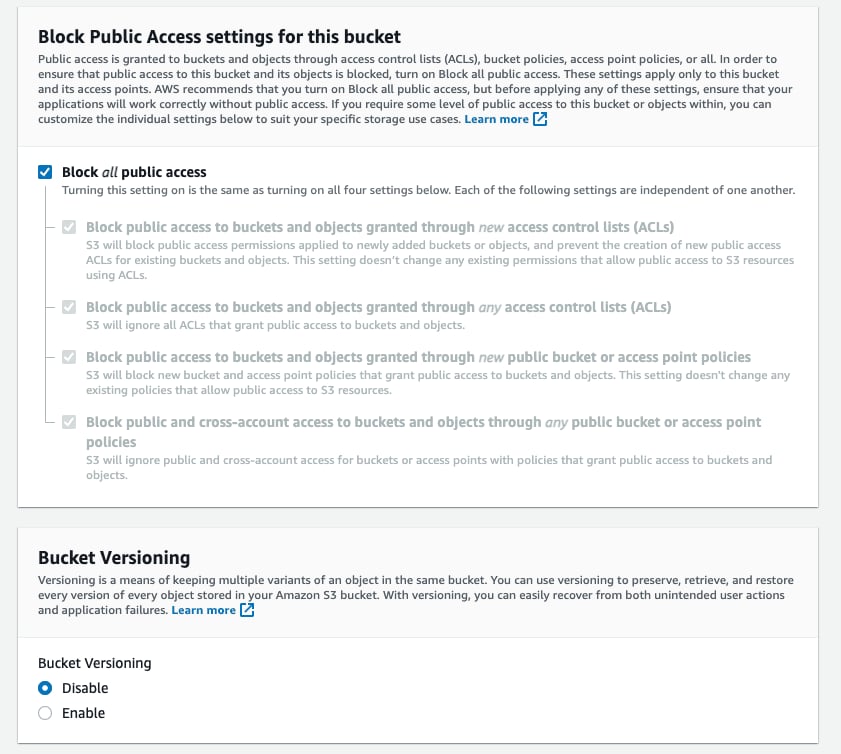
Block all Public Accessは有効のままにしておきます。パブリックアクセスは不要です。
- ページ下部にある
Create Bucketを選択します
- リンクを選択し、ARN をコピーして、バケットのアクセスポリシーを設定する際に使えるよう保存します。
- バケットが作成されたら、S3 バケット一覧で新しい S3 バケットを見つけて、そのリンクを選択します
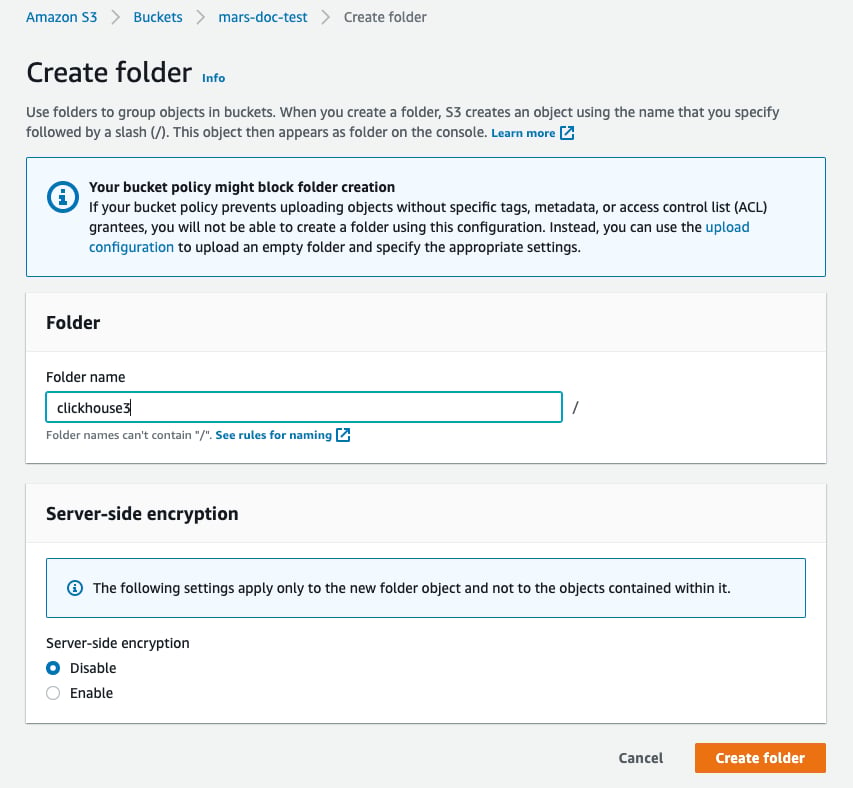
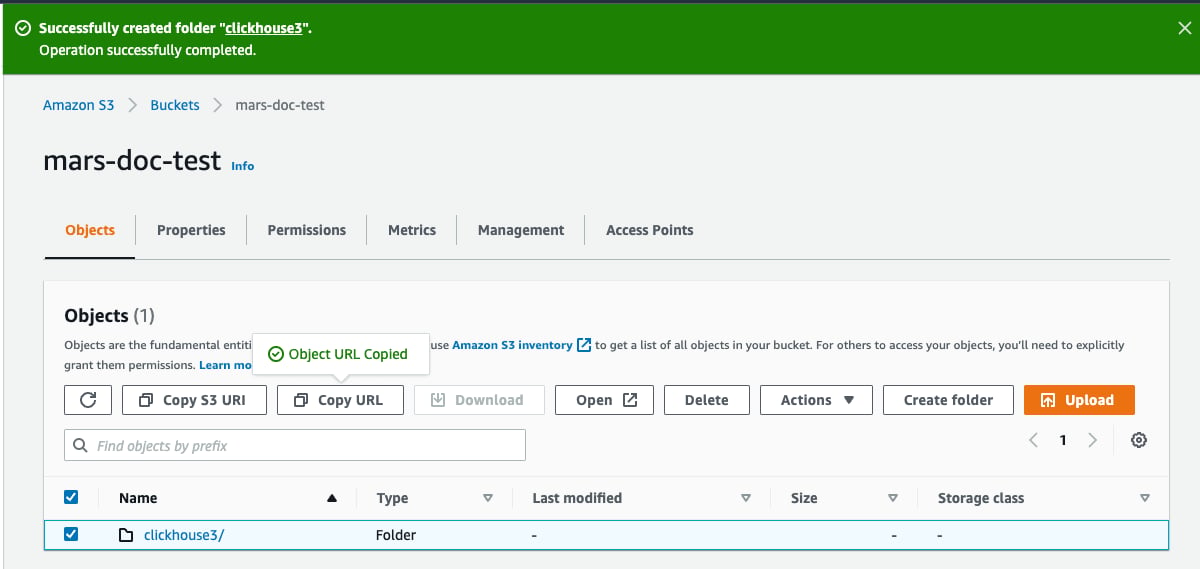
Create folderを選択します
- ClickHouse S3 ディスクの保存先となるフォルダ名を入力し、
Create folderを選択します
- フォルダがバケット一覧に表示されているはずです
- 新しいフォルダのチェックボックスを選択し、
Copy URLをクリックします。次のセクションの ClickHouse のストレージ構成で使用するため、コピーした URL を保存しておきます。
Permissionsタブを開き、Bucket PolicyセクションでEditボタンをクリックします
- バケットポリシーを追加します。例を以下に示します:
使用する権限については、セキュリティチームと連携して判断してください。以下はその出発点としてご検討ください。
ポリシーと設定の詳細については、AWS のドキュメントを参照してください。
https://docs.aws.amazon.com/AmazonS3/latest/userguide/access-policy-language-overview.html
- ポリシー設定を保存します。
/etc/clickhouse-server/config.d/ に配置されます。以下は一方のバケット用の設定ファイルのサンプルです。もう一方もほぼ同じですが、強調表示されている 3 行が異なります。
/etc/clickhouse-server/config.d/storage_config.xml
このガイドの多くの手順では、設定ファイルを
/etc/clickhouse-server/config.d/ に配置する必要があります。これは、Linux システムで設定の上書き用ファイルを配置するデフォルトの場所です。これらのファイルをこのディレクトリに置くと、ClickHouse はその内容を使ってデフォルト設定を上書きします。これらのファイルを上書き用ディレクトリに配置しておけば、アップグレード時に設定が失われるのを防げます。ClickHouse Keeper を設定する
/etc/clickhouse-keeper/keeper_config.xml です。3 台の Keeper サーバーはすべて同じ設定を使用し、異なるのは <server_id> だけです。
server_id は、その設定ファイルを使用するホストに割り当てる ID を示します。以下の例では、server_id は 3 です。さらにファイル内の下のほうにある <raft_configuration> セクションを見ると、server 3 のホスト名が keepernode3 であることがわかります。これにより、リーダーを選出する際やその他の処理で、どのサーバーに接続すべきかを ClickHouse Keeper プロセスが判断できます。
/etc/clickhouse-keeper/keeper_config.xml
<server_id> を設定するのを忘れないでください) :
ClickHouseサーバーを設定する
クラスターを定義する
<remote_servers> セクションで定義します。この例では、cluster_1S_2R という 1 つのクラスターを定義しており、これは 1 つの分片と 2 つのレプリカで構成されています。レプリカはホスト chnode1 と chnode2 にあります。
/etc/clickhouse-server/config.d/remote-servers.xml
shard、replica の設定を埋め込むためのマクロを定義しておくと便利です。 このサンプルでは、shard と replica の詳細を指定しなくても、レプリケーション対応のテーブルエンジンを使用できます。 テーブルを作成すると、system.tables をクエリすることで、shard マクロと replica マクロがどのように使われているかを確認できます。
/etc/clickhouse-server/config.d/macros.xml
上記のマクロは
chnode1 用です。chnode2 では、replica を replica_2 に設定してください。ゼロコピーレプリケーションを無効にする
allow_remote_fs_zero_copy_replication はデフォルトで true になっています。この災害復旧シナリオでは、この設定を false にする必要があります。なお、22.8 以降ではデフォルトで false です。
この設定を false にすべき理由は 2 つあります。1) この機能はまだ本番環境向けではありません。2) 災害復旧シナリオでは、データとメタデータの両方を複数のリージョンに保存する必要があります。allow_remote_fs_zero_copy_replication を false に設定してください。
/etc/clickhouse-server/config.d/remote-servers.xml
/etc/clickhouse-server/config.d/use_keeper.xml
ネットワークを設定する
/etc/clickhouse-server/config.d/ で設定します。以下は、ClickHouse と ClickHouse Keeper がすべての IPv4 インターフェイスで待ち受けるように設定するサンプルです。詳細については、ドキュメントまたは既定の設定ファイル /etc/clickhouse/config.xml を参照してください。
/etc/clickhouse-server/config.d/networking.xml
サーバーを起動する
ClickHouse Keeper を起動する
ClickHouse Keeper のステータスを確認する
netcat を使って ClickHouse Keeper にコマンドを送信します。たとえば、mntr は ClickHouse Keeper クラスターの状態を返します。各 Keeper ノードでこのコマンドを実行すると、1 つがリーダーで、残り 2 つがフォロワーであることがわかります。
ClickHouseサーバーを実行する
ClickHouseサーバー を検証する
-
クラスターが存在することを確認します。
-
ReplicatedMergeTreeテーブルエンジンを使用して、クラスター内にテーブルを作成します。 -
前に定義したマクロの使い方を理解する
マクロ
shardとreplicaは前の手順で定義されており、以下のハイライトされた行では、各 ClickHouse ノードでそれらの値がどのように置き換えられるかを確認できます。さらに、値uuidも使われています。uuidはシステムによって生成されるため、マクロでは定義されていません。
default_replica_path と default_replica_name を設定することで、上に示した ZooKeeper パス 'clickhouse/tables/{uuid}/{shard} をカスタマイズできます。ドキュメントはこちらです。テスト
-
New York City taxi dataset からデータを追加します。
-
データが S3 に保存されていることを確認します。
このクエリでは、ディスク上のデータサイズと、どのディスクを使用するかを決定するポリシーを確認できます。
ローカルディスク上のデータサイズを確認します。上記の結果では、保存されている数百万行のディスク使用量は 36.42 MiB です。これはローカルディスクではなく、S3 に保存されているはずです。上のクエリからは、ローカルディスク上でデータとメタデータが保存されている場所もわかります。ローカルのデータを確認します。各 S3 バケット内のデータを確認します (totals は表示されていませんが、INSERT 後は両方のバケットに約 36 MiB 保存されています) 。
S3Express
S3Express は単一の AZ にデータを保存します。つまり、AZ 障害が発生した場合、データは利用できなくなります。
S3 ディスク
Directoryタイプのバケットを作成します- 必要な権限をすべて S3 ユーザーに付与するため、適切なバケットポリシーを設定します (例: 無制限のアクセスを許可するだけであれば
"Action": "s3express:*") - ストレージポリシーを設定する際は、
regionパラメータを指定してください
S3ストレージ
Object URL パスの場合のみです。例: