Redshift から ClickHouse へのデータ移行
関連コンテンツ
概要
Amazon Redshift は、Amazon Web Services の一部である人気のクラウドデータウェアハウジングソリューションです。このガイドでは、Redshift インスタンスから ClickHouse へのデータ移行のためのさまざまなアプローチを紹介します。以下の三つのオプションをカバーします:
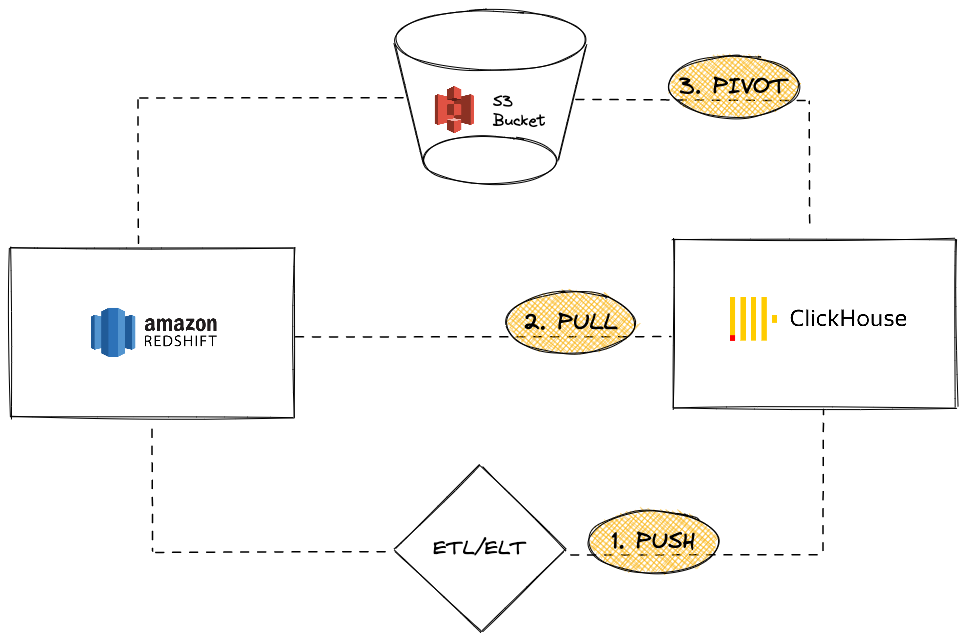
ClickHouse インスタンスの観点からは、次のいずれかを行うことができます:
-
PUSH サードパーティの ETL/ELT ツールまたはサービスを使用して ClickHouse にデータを送信する
-
PULL ClickHouse JDBC ブリッジを活用して Redshift からデータを取得する
-
PIVOT S3 オブジェクトストレージを使用して「アンロード後にロード」ロジックを使用する
このチュートリアルでは Redshift をデータソースとして使用しました。ただし、ここで説明する移行アプローチは Redshift に限定されるものではなく、互換性のあるデータソースに対して同様の手順を導き出すことができます。
Redshift から ClickHouse へのデータプッシュ
プッシュシナリオでは、サードパーティのツールまたはサービス(カスタムコードまたは ETL/ELT ソフトウェア)を活用して、データを ClickHouse インスタンスに送信することを目的としています。例えば、Airbyte のようなソフトウェアを使用して、Redshift インスタンス(ソース)と ClickHouse(デスティネーション)間でデータを移動することができます(Airbyte の統合ガイドを参照してください)。

利点
- ETL/ELT ソフトウェアのコネクタの既存カタログを活用できる。
- データを同期するための組み込み機能(追加/上書き/インクリメントロジック)。
- データ変換シナリオを可能にする(例えば、dbt の統合ガイドを参照)。
欠点
- ユーザーは ETL/ELT インフラを設定および維持する必要がある。
- アーキテクチャにサードパーティの要素を導入し、潜在的なスケーラビリティのボトルネックになる可能性がある。
Redshift から ClickHouse へのデータプル
プルシナリオでは、ClickHouse JDBC ブリッジを活用して、ClickHouse インスタンスから直接 Redshift クラスターに接続し、INSERT INTO ... SELECT クエリを実行します:

利点
- すべての JDBC 互換ツールに一般的
- ClickHouse 内から複数の外部データソースをクエリするための洗練されたソリューション
欠点
- スケーラビリティのボトルネックになる可能性のある ClickHouse JDBC ブリッジインスタンスを必要とする
Redshift は PostgreSQL に基づいていますが、ClickHouse PostgreSQL テーブル関数やテーブルエンジンを使用することはできません。なぜなら、ClickHouse は PostgreSQL バージョン 9 以上を要求し、Redshift API は古いバージョン(8.x)に基づいているからです。
チュートリアル
このオプションを使用するには、ClickHouse JDBC ブリッジを設定する必要があります。ClickHouse JDBC ブリッジは、JDBC 接続を処理し、ClickHouse インスタンスとデータソースの間のプロキシとして機能するスタンドアロンの Java アプリケーションです。このチュートリアルでは、サンプルデータベースを持つ事前に設定された Redshift インスタンスを使用しました。
- ClickHouse JDBC ブリッジを展開します。詳細については、外部データソース用の JDBC のユーザーガイドを参照してください。
ClickHouse Cloud を使用している場合は、別の環境で ClickHouse JDBC ブリッジを実行し、remoteSecure 関数を使用して ClickHouse Cloud に接続する必要があります。
- ClickHouse JDBC ブリッジの Redshift データソースを構成します。例えば、
/etc/clickhouse-jdbc-bridge/config/datasources/redshift.json
- ClickHouse JDBC ブリッジが展開されて実行されている場合、ClickHouse から Redshift インスタンスをクエリし始めることができます。
- 次に、
INSERT INTO ... SELECTステートメントを使用してデータをインポートします。
S3 を使用して Redshift から ClickHouse へのデータピボット
このシナリオでは、データを中間ピボット形式で S3 にエクスポートし、次のステップで S3 から ClickHouse にデータをロードします。
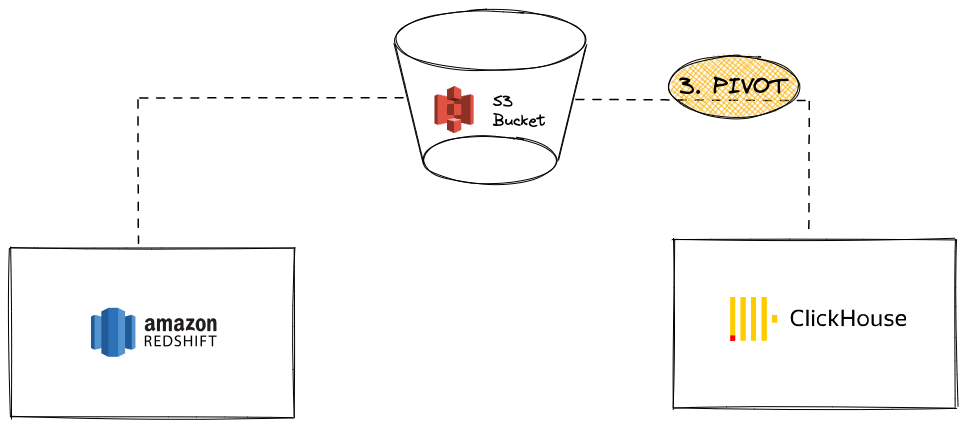
利点
- Redshift と ClickHouse の両方が強力な S3 統合機能を持っている。
- Redshift の
UNLOADコマンドや ClickHouse S3 テーブル関数 / テーブルエンジンの既存機能を利用。 - ClickHouse の S3 への並列読み取りと高スループット機能によりシームレスにスケールできます。
- Apache Parquet のような洗練された圧縮フォーマットを活用できる。
欠点
- プロセスに 2 ステップ(Redshift からアンロードして ClickHouse へロード)が必要です。
チュートリアル
-
Redshift の UNLOAD 機能を使用して、既存のプライベート S3 バケットにデータをエクスポートします:
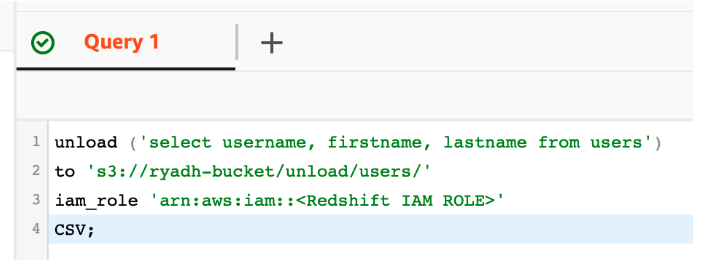
これにより、S3 に生データを含むパートファイルが生成されます。

-
ClickHouse にテーブルを作成します:
または、ClickHouse は
CREATE TABLE ... EMPTY AS SELECTを使用してテーブル構造を推測することができます:これは特にデータがデータ型に関する情報を含むフォーマット(例: Parquet)である場合に効果的です。
-
S3 ファイルを ClickHouse にロードします。
INSERT INTO ... SELECTステートメントを使用します:
この例では、CSV をピボットフォーマットとして使用しました。ただし、生産ワークロードでは、圧縮とストレージコストを削減しつつトランスファー時間を短縮できるため、大規模な移行には Apache Parquet を最良の選択肢としてお勧めします。(デフォルトでは、各行グループは SNAPPY を使用して圧縮されています。)ClickHouse は Parquet の列指向性を活用してデータの取り込みを加速します。
