ClickHouse Connect を使用した Python との連携
Introduction
ClickHouse Connect は、幅広い Python アプリケーションとの相互運用性を提供する中核となるデータベースドライバーです。
- メインインターフェースは、パッケージ
clickhouse_connect.driverに含まれるClientオブジェクトです。このコアパッケージには、ClickHouse サーバーとの通信に使用される各種ヘルパークラスおよびユーティリティ関数に加え、INSERT および SELECT クエリを高度に制御するための「コンテキスト」実装も含まれています。 - パッケージ
clickhouse_connect.datatypesは、すべての非実験的な ClickHouse データ型向けのベース実装とサブクラスを提供します。その主な機能は、ClickHouse データを ClickHouse の「Native」バイナリ列指向フォーマットにシリアル化および逆シリアル化することであり、これにより ClickHouse とクライアントアプリケーション間の最も効率的なデータ転送を実現します。 - パッケージ
clickhouse_connect.cdriver内の Cython/C クラスは、最も一般的なシリアル化および逆シリアル化処理の一部を最適化し、純粋な Python 実装と比べて大幅に高いパフォーマンスを実現します。 - パッケージ
clickhouse_connect.cc_sqlalchemyには、datatypesおよびdbiパッケージを基盤として構築された SQLAlchemy ダイアレクトがあります。この実装は、JOIN(INNER、LEFT OUTER、FULL OUTER、CROSS) 、WHERE句、ORDER BY、LIMIT/OFFSET、DISTINCT操作、WHERE条件付きの軽量なDELETE文、テーブルリフレクション、基本的な DDL 操作 (CREATE TABLE、CREATE/DROP DATABASE) を含む SQLAlchemy Core の機能をサポートします。高度な ORM 機能や高度な DDL 機能はサポートしていませんが、ClickHouse の OLAP 指向データベースに対する多くの分析ワークロードに適した堅牢なクエリ機能を提供します。 - コアドライバーおよび ClickHouse Connect SQLAlchemy 実装は、ClickHouse を Apache Superset に接続するための推奨方法です。
ClickHouse Connectデータベース接続、またはclickhousedbSQLAlchemy ダイアレクトの接続文字列を使用してください。
本ドキュメントは、clickhouse-connect リリース 0.9.2 時点の内容です。
公式の ClickHouse Connect Python ドライバーは、ClickHouse サーバーとの通信に HTTP プロトコルを使用します。これにより HTTP ロードバランサーの利用が可能となり、ファイアウォールやプロキシが存在するエンタープライズ環境でも適切に動作しますが、ネイティブな TCP ベースプロトコルと比べて圧縮効率とパフォーマンスがわずかに低く、クエリキャンセルのような一部の高度な機能はサポートされません。ユースケースによっては、ネイティブな TCP ベースプロトコルを使用する Community Python drivers の利用を検討してください。
動作要件と互換性
| Python | プラットフォーム¹ | ClickHouse | SQLAlchemy² | Apache Superset | Pandas | Polars | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2.x, <3.9 | ❌ | Linux (x86) | ✅ | <25.x³ | 🟡 | <1.4.40 | ❌ | <1.4 | ❌ | ≥1.5 | ✅ | 1.x | ✅ |
| 3.9.x | ✅ | Linux (Aarch64) | ✅ | 25.x³ | 🟡 | ≥1.4.40 | ✅ | 1.4.x | ✅ | 2.x | ✅ | ||
| 3.10.x | ✅ | macOS (x86) | ✅ | 25.3.x (LTS) | ✅ | ≥2.x | ✅ | 1.5.x | ✅ | ||||
| 3.11.x | ✅ | macOS (ARM) | ✅ | 25.6.x (Stable) | ✅ | 2.0.x | ✅ | ||||||
| 3.12.x | ✅ | Windows | ✅ | 25.7.x (Stable) | ✅ | 2.1.x | ✅ | ||||||
| 3.13.x | ✅ | 25.8.x (LTS) | ✅ | 3.0.x | ✅ | ||||||||
| 25.9.x (Stable) | ✅ |
¹ClickHouse Connect は上記に列挙したプラットフォームに対して明示的にテストされています。さらに、優れた cibuildwheel プロジェクトでサポートされているすべてのアーキテクチャ向けに、テストされていないバイナリ wheel(C による最適化あり)もビルドされています。最後に、ClickHouse Connect は純粋な Python 実装としても動作するため、ソースからのインストールは比較的新しい Python 実装であればどれでも動作すると考えられます。
²SQLAlchemy のサポートは Core 機能(クエリ、基本的な DDL)に限定されています。ORM 機能はサポートされていません。詳細については SQLAlchemy 連携サポート ドキュメントを参照してください。
³ClickHouse Connect は、公式にサポートされている範囲外のバージョンでも概ね問題なく動作します。
インストール
pip を使って PyPI から ClickHouse Connect をインストールします:
pip install clickhouse-connect
ClickHouse Connect はソースからインストールすることもできます:
git cloneを使って GitHub リポジトリ をクローンします- (オプション)C/Cython の最適化をビルドして有効にするために
pip install cythonを実行します cdコマンドでプロジェクトのルートディレクトリに移動し、pip install .を実行します
サポートポリシー
問題を報告する前に、必ず ClickHouse Connect を最新バージョンに更新してください。問題は GitHub のプロジェクトに起票してください。ClickHouse Connect の将来のリリースは、リリース時点で積極的にサポートされている ClickHouse バージョンとの互換性を保つことを想定しています。ClickHouse サーバーの積極的サポート対象バージョンはこちらで確認できます。どのバージョンの ClickHouse サーバーを使用すべきか判断に迷う場合は、こちらのディスカッションを参照してください。CI のテストマトリクスでは、最新の 2 つの LTS リリースと最新の 3 つの安定版リリースに対してテストを実行しています。ただし、HTTP プロトコルの性質と、ClickHouse のリリース間で破壊的変更が最小限に抑えられていることから、ClickHouse Connect は公式にサポートされる範囲外のサーバーバージョンでも概ね良好に動作しますが、一部の高度なデータ型との互換性は変動する可能性があります。
基本的な使い方
接続情報を確認する
HTTP(S) で ClickHouse に接続するには、次の情報が必要です。
| Parameter(s) | Description |
|---|---|
HOST and PORT | 通常、TLS を使用する場合のポートは 8443、TLS を使用しない場合のポートは 8123 です。 |
DATABASE NAME | 既定で default という名前のデータベースが用意されています。接続したいデータベースの名前を使用してください。 |
USERNAME and PASSWORD | 既定のユーザー名は default です。用途に応じて適切なユーザー名を使用してください。 |
ClickHouse Cloud サービスに関する詳細情報は、ClickHouse Cloud コンソールで確認できます。 サービスを選択し、Connect をクリックします。
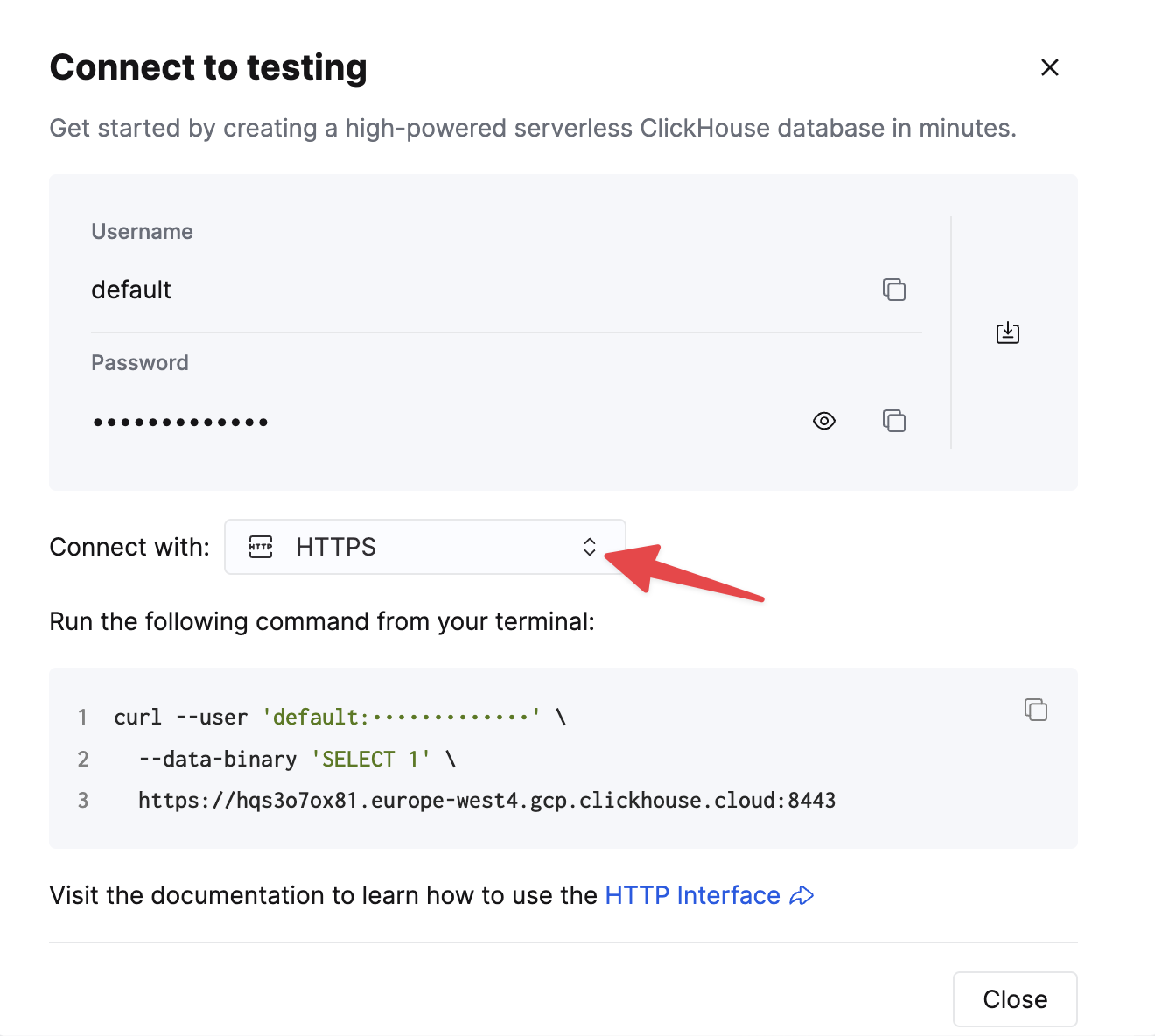
HTTPS を選択します。接続情報は、サンプルの curl コマンド内に表示されます。
セルフマネージドの ClickHouse を使用している場合、接続情報は ClickHouse 管理者によって設定されます。
接続を確立する
ClickHouse への接続方法として、次の 2 つの例を示します。
- localhost 上で動作している ClickHouse サーバーに接続する場合
- ClickHouse Cloud サービスに接続する場合
ClickHouse Connect クライアント インスタンスを使用して localhost 上の ClickHouse サーバーに接続する:
ClickHouse Connect クライアントインスタンスを使用して ClickHouse Cloud サービスに接続します:
先ほど収集した接続情報を使用してください。ClickHouse Cloud サービスでは TLS が必須となるため、ポート 8443 を使用してください。
データベースを操作する
ClickHouse の SQL コマンドを実行するには、クライアントの command メソッドを使用します。
バッチデータを挿入するには、行と値の二次元配列をクライアントの insert メソッドに渡して使用します。
ClickHouse SQL を使用してデータを取得するには、クライアントの query メソッドを使用してください。
