
PostgreSQLとClickHouseの比較
Postgres vs ClickHouse: 等価および異なる概念
OLTPシステムから来たユーザーは、ACIDトランザクションに慣れているかもしれませんが、ClickHouseはパフォーマンスの対価としてこれを完全には提供していないことに留意すべきです。ClickHouseのセマンティクスは、十分に理解されていれば高い耐久性の保証と高い書き込みスループットを提供できます。PostgresからClickHouseで作業を始める前に、ユーザーが把握しておくべきいくつかの重要な概念を以下に示します。
シャードとレプリカの違い
シャーディングとレプリケーションは、ストレージまたは計算がパフォーマンスのボトルネックとなるときに、1つのPostgresインスタンスを超えてスケールするために使用される2つの戦略です。Postgresにおけるシャーディングは、大規模なデータベースを複数のノードに分割して、小さく、より管理しやすい部分にすることを含みます。しかし、Postgresはネイティブにシャーディングをサポートしていません。代わりに、Postgresが水平にスケーリングできる分散データベースとなるための拡張機能(例:Citus)を使用することでシャーディングが実現できます。このアプローチにより、Postgresは負荷をいくつかのマシンに分散させることによって、より高いトランザクション率と大規模なデータセットを処理できます。シャードは、トランザクション型または分析型のワークロードのような柔軟性を提供するために、行またはスキーマベースで分割することができます。シャーディングは、複数のマシン間での調整や整合性の保証が必要であるため、データ管理やクエリ実行の点で重大な複雑さをもたらす可能性があります。
シャードとは異なり、レプリカはプライマリノードからのデータのすべてまたは一部を含む追加のPostgresインスタンスです。レプリカは、強化された読み取り性能やHA(高可用性)シナリオなど、さまざまな理由で使用されます。物理レプリケーションは、Postgresのネイティブ機能であり、全体のデータベースまたは重要な部分を他のサーバーにコピーすることを含みます。これには、プライマリノードからレプリカへのWALセグメントのストリーミングが含まれます。一方、論理レプリケーションは、INSERT、UPDATE、およびDELETE操作に基づいて変更をストリーミングするより高い抽象レベルです。物理レプリケーションと同じ結果が適用される可能性がありますが、特定のテーブルや操作をターゲットにしたり、データの変換を行ったり、異なるPostgresバージョンをサポートするための柔軟性が高まります。
対照的に、ClickHouseのシャードとレプリカはデータ分散と冗長性に関連する2つの重要な概念です。ClickHouseのレプリカはPostgresのレプリカに類似していると考えることができますが、レプリケーションは最終的に一貫性を保ち、プライマリの概念はありません。シャーディングはPostgresとは異なり、ネイティブでサポートされています。
シャードは、テーブルデータの一部です。常に少なくとも1つのシャードがあります。複数のサーバーにデータをシャーディングすることで、すべてのシャードを使用してクエリを並行して実行する場合、単一のサーバーの容量を超えた際に負荷を分散できます。ユーザーは、異なるサーバー上のテーブルに手動でシャードを作成し、データを直接挿入することもできます。あるいは、データがどのシャードにルーティングされるかを定義するシャーディングキーを使用して分散テーブルを利用することができます。シャーディングキーは、ランダムであったり、ハッシュ関数の出力のいずれかです。重要な点は、シャードは複数のレプリカから構成されることがあることです。
レプリカはデータのコピーです。ClickHouseには常にデータの少なくとも1つのコピーがあり、したがって最小のレプリカ数は1です。データの2つ目のレプリカを追加することで、障害耐性が提供され、より多くのクエリを処理するための追加の計算能力が得られます(Parallel Replicas を使用することで、単一クエリの計算を分散し、レイテンシを低下させることもできます)。レプリケーションはReplicatedMergeTreeテーブルエンジンを使用して実現され、ClickHouseは異なるサーバー間でデータの複数のコピーを同期させます。レプリケーションは物理的です:ノード間で転送されるのは圧縮されたパーツのみで、クエリは転送されません。
要約すると、レプリカは冗長性と信頼性(および潜在的に分散処理)を提供するデータのコピーであり、シャードは分散処理と負荷分散を可能にするデータのサブセットです。
ClickHouse Cloudは、S3にバックアップされたデータの単一コピーを使用し、複数の計算レプリカを持ちます。データは各レプリカノードに利用可能で、各ノードにはローカルSSDキャッシュがあります。これは、ClickHouse Keeperを介してメタデータのレプリケーションのみに依存しています。
最終的一貫性
ClickHouseは、内部レプリケーション機構を管理するためにClickHouse Keeper(C++のZooKeeper実装、ZooKeeperも使用可能)を使用しており、主にメタデータストレージと最終的一貫性の確保に焦点を当てています。Keeperは、分散環境内の各挿入に対して一意の連続番号を割り当てるために使用されます。これは、操作全体の順序と整合性を保つために重要です。このフレームワークは、マージやミューテーションなどのバックグラウンド操作も処理し、これらの作業が分散されることを保証しながら、それらがすべてのレプリカで同じ順序で実行されるようにします。メタデータに加えて、Keeperはレプリケーションのための包括的な制御センターとして機能し、ストレージされたデータパーツのチェックサムを追跡し、レプリカ間での分散通知システムとしても機能します。
ClickHouseにおけるレプリケーションプロセスは、(1) データが任意のレプリカに挿入されると始まります。このデータは、(2) そのチェックサムと一緒にディスクに書き込まれます。書き込まれた後、レプリカは(3) Keeperにこの新しいデータパートを一意のブロック番号を割り当てて登録し、新しいパートの詳細をログに記録しようとします。他のレプリカは、(4) レプリケーションログに新しいエントリを検出すると、(5) 内部HTTPプロトコルを介して対応するデータパートをダウンロードし、ZooKeeperにリストされたチェックサムと照合します。この方法により、すべてのレプリカは、処理速度の違いや潜在的な遅延にもかかわらず、最終的に一貫した最新のデータを保持します。さらに、システムは複数の操作を同時に処理できるため、データ管理プロセスを最適化し、システムのスケーラビリティやハードウェアの不一致に対しての強靭性を実現します。
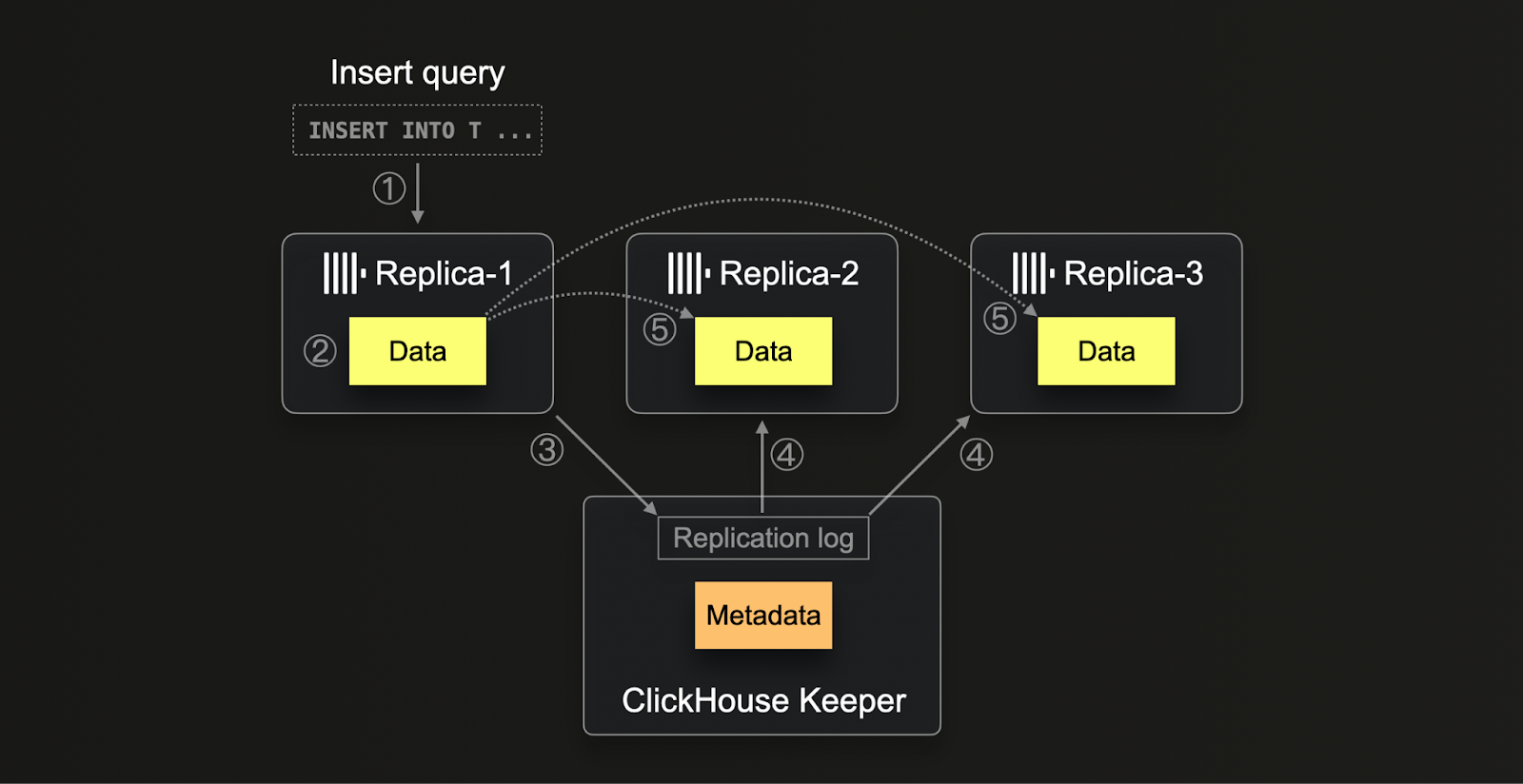
ClickHouse Cloudは、ストレージと計算のアーキテクチャの分離に適応したクラウド最適化されたレプリケーションメカニズムを使用します。データを共有オブジェクトストレージに保存することで、データはノード間で物理的にレプリケートすることなく、すべての計算ノードに自動的に利用可能になります。代わりに、Keeperは計算ノード間でメタデータ(どのデータがどのオブジェクトストレージに存在するか)を共有するだけです。
PostgreSQLは、ClickHouseとは異なるレプリケーション戦略を採用しており、主にストリーミングレプリケーションを使用しています。このモデルは、プライマリレプリカモデルに基づいており、データはプライマリから1つまたは複数のレプリカノードに継続的にストリーミングされます。このタイプのレプリケーションは、ほぼリアルタイムの一貫性を保証し、同期または非同期であり、管理者に可用性と整合性のバランスを制御することを可能にします。ClickHouseとは異なり、PostgreSQLは、WAL(Write-Ahead Logging)を使用し、論理レプリケーションとデコーディングを通じてデータオブジェクトや変更をノード間でストリーミングします。このアプローチはPostgreSQLではより単純ですが、ClickHouseが分散操作の調整と最終的一貫性のためにKeeperを複雑に使用することで達成するかもしれない同じレベルのスケーラビリティと障害耐性を提供できない場合があります。
ユーザーへの影響
ClickHouseでは、ユーザーが1つのレプリカにデータを書き込み、他のレプリカから潜在的に未レプリケートのデータを読み取る可能性がある「ダーティリード」が発生する可能性があります。これはKeeperによって管理される最終的一貫性のあるレプリケーションモデルから生じます。このモデルは、分散システム全体でのパフォーマンスとスケーラビリティを重視し、レプリカが独立して動作し、非同期で同期することを可能にします。その結果、新しく挿入されたデータは、レプリケーションの遅延や変更がシステムを通じて伝播するのにかかる時間に応じて、すぐにはすべてのレプリカに表示されない場合があります。
一方、PostgreSQLのストリーミングレプリケーションモデルは、通常、プライマリが少なくとも1つのレプリカのデータ受領を確認するまで待機する同期レプリケーションオプションを使用することにより、ダーティリードを防ぐことができます。これにより、トランザクションがコミットされた後、データが他のレプリカに存在することが保証されます。プライマリの障害が発生した場合、レプリカはクエリにコミットデータを確実に表示し、より厳格な整合性を維持します。
推奨事項
ClickHouseに新たに訪れるユーザーは、これらの違いについて理解しておく必要があります。これはレプリケートされた環境で顕著に現れます。通常、最終的な整合性は、数十億、あるいは数兆のデータポイントにわたる分析に十分です ― この場合、メトリックはより安定しているか、推定が十分であり、新しいデータが高いレートで継続的に挿入されています。
必要に応じて、読み取りの一貫性を高めるいくつかのオプションがあります。両方の例は、複雑さやオーバーヘッドが増加し、クエリのパフォーマンスを低下させ、ClickHouseのスケーリングをより困難にします。このアプローチは絶対に必要な場合にのみ推奨します。
一貫したルーティング
最終的な整合性のいくつかの制限を克服するために、ユーザーはクライアントが同じレプリカにルーティングされることを保証できます。これは、複数のユーザーがClickHouseをクエリしていて、リクエスト間で結果が決定的である必要がある場合に便利です。結果は新しいデータが挿入されるにつれて異なるかもしれませんが、同じレプリカをクエリすることで一貫したビューを確保することができます。
これは、アーキテクチャやClickHouse OSSまたはClickHouse Cloudを使用しているかどうかに応じて、いくつかのアプローチを通じて実現できます。
ClickHouse Cloud
ClickHouse Cloudは、S3にバックアップされたデータの単一コピーを使用し、複数の計算レプリカを持ちます。データは、ローカルSSDキャッシュを持つ各レプリカノードに利用可能です。したがって、一貫した結果を保証するためには、ユーザーは同じノードに一貫したルーティングを保証する必要があります。
ClickHouse Cloudサービスのノードへの通信はプロキシを介して行われます。HTTPおよびネイティブプロトコルの接続は、保持されている期間中同じノードにルーティングされます。ほとんどのクライアントからのHTTP 1.1接続の場合、これはKeep-Aliveウィンドウに依存します。この設定は、Node Jsなどのほとんどのクライアントで構成できます。これには、クライアントよりも高く設定され、ClickHouse Cloudでは10秒に設定されているサーバー側の構成も必要です。
接続の一貫したルーティングを確保するためには、接続プールを使用しているか、接続が期限切れになった場合に、ユーザーは同じ接続を使用することを保証するか(ネイティブでは容易)、ステッキーエンドポイントの公開をリクエストすることができます。これにより、クラスター内の各ノードに対して一連のエンドポイントを提供し、クライアントが決定的にクエリがルーティングされることを保証できます。
ステッキーエンドポイントへのアクセスについてはサポートにお問い合わせください。
ClickHouse OSS
この動作をOSSで実現するためは、シャードとレプリカのトポロジーと、クエリに分散テーブルを使用しているかどうかに依存します。
シャードとレプリカが1つしかない場合(ClickHouseが垂直スケールするため一般的です)、ユーザーはクライアントレイヤーでノードを選択し、レプリカに直接クエリを実行し、決定論的に選択されていることを保証します。
分散テーブルを使用しない場合でも、複数のシャードとレプリカを持つトポロジーは可能ですが、これらの高度なデプロイメントは通常独自のルーティングインフラストラクチャを持っています。そのため、1つのシャード以上のデプロイメントは、分散テーブルを使用していると仮定します(分散テーブルは単一シャードのデプロイメントでも使用できますが、通常は不要です)。
この場合、ユーザーは、session_idやuser_idなどのプロパティに基づいて一貫したノードルーティングが実施されることを確認すべきです。設定prefer_localhost_replica=0、load_balancing=in_orderは、クエリ内に設定する必要があります。これにより、シャードのローカルレプリカが優先され、設定に従ってレプリカが優先されます ― エラーの数が同じであればランダム選択によるフェイルオーバーが発生します。load_balancing=nearest_hostnameも、決定論的なシャード選択の代替案として利用可能です。
分散テーブルを作成するとき、ユーザーはクラスターを指定します。このクラスター定義はconfig.xmlに指定され、シャード(およびそのレプリカ)がリストされるため、ユーザーは各ノードから使用される順序を制御できます。これを使用することで、ユーザーは選択が決定論的になるようにできます。
順次整合性
例外的な場合に、ユーザーは順次整合性が必要となることがあります。
データベースにおける順次整合性とは、データベース上の操作が何らかの順次の順序で実行されるように見え、この順序がデータベースに関与するすべてのプロセスで一貫していることを意味します。これは、すべての操作がその呼び出しと完了の間に瞬時に効果を持つように見え、すべての操作がいかなるプロセスから観察されるものとして合意された単一の順序が存在することを意味します。
ユーザーの観点からは、通常は、ClickHouseにデータを書き込み、データを読み取る際に最新の挿入行が返されることを保証する必要があります。 これは、以下の方法で実現できます(好みの順)の:
- 同じノードに読み書き - ネイティブプロトコルを使用している場合、またはHTTPを介して書き込み/読み込みを行うセッションを使用している場合は、同じレプリカに接続する必要があります。このシナリオでは、書き込みを行っているノードから直接読み取るため、読み取りは常に一貫します。
- レプリカを手動で同期 - 一つのレプリカに書き込み、別のレプリカから読み取る場合、読み取る前に
SYSTEM SYNC REPLICA LIGHTWEIGHTを使用できます。 - 順次整合性の有効化 - クエリ設定
select_sequential_consistency = 1を介して有効化します。OSSでは、設定insert_quorum = 'auto'も指定する必要があります。
詳細な設定の有効化についてはこちらをご覧ください。
順次整合性の使用は、ClickHouse Keeperに対してより大きな負荷をかけます。結果として、挿入と読み取りが遅くなる可能性があります。ClickHouse Cloudで主なテーブルエンジンとして使用されるSharedMergeTreeは、順次整合性の影響を軽減し、より良くスケールします[/cloud/reference/shared-merge-tree#consistency]。OSSユーザーは、このアプローチを慎重に利用し、Keeperの負荷を測定してください。
トランザクショナル(ACID)サポート
PostgreSQLから移行してきたユーザーは、ACID(原子性、一貫性、独立性、耐久性)特性の堅牢なサポートに慣れている可能性があり、これによりトランザクションデータベースとして信頼性のある選択肢となります。PostgreSQLにおける原子性は、各トランザクションが単一のユニットとして扱われ、完全に成功するか全体が巻き戻されるかのいずれかとなります。部分更新を防ぎます。一貫性は、すべてのデータベーストランザクションが有効な状態に至ることを保証する制約、トリガー、ルールによって維持されます。独立性レベル(読み取りコミットから直列化可能まで)がPostgreSQLでサポートされ、同時トランザクションによって行われた変更の可視性を微調整することができます。最後に、耐久性は、トランザクションがコミットされた後、システム障害が発生してもその状態が保持されることを保証するために、書き込み前ログ(WAL)によって達成されます。
これらの特性は、真実のソースとして機能するOLTPデータベースに共通です。
強力ですが、これには固有の制限があり、PBスケールを難しくします。ClickHouseは、高書き込みスループットを維持しつつ、スケールで迅速な分析クエリを提供するために、これらの特性を妥協しています。
ClickHouseは、限られた構成でACID特性を提供します ― 最も簡単な例は、1つのパーティションを持つ非レプリケートのMergeTreeテーブルエンジンを使用する場合です。このような場合外でこれらの特性を期待しないでください。
ClickPipes(PeerDBを使用)によるPostgresデータのレプリケーションまたは移行
PeerDBは、ClickHouse Cloudでネイティブに利用可能です - 新しいClickPipeコネクタを介したBlazing-fast PostgresからClickHouseへのCDCの提供 - 現在パブリックベータ中です。
PeerDBを使用すると、PostgresからClickHouseへのデータのレプリケーションをシームレスに行えます。このツールを次の目的で使用できます。
- CDCを利用した継続的なレプリケーションにより、PostgresとClickHouseが共存可能 ― PostgresはOLTP用、ClickHouseはOLAP用。
- PostgresからClickHouseへの移行。