1
接続情報を確認する
HTTP(S) で ClickHouse に接続するには、次の情報が必要です。
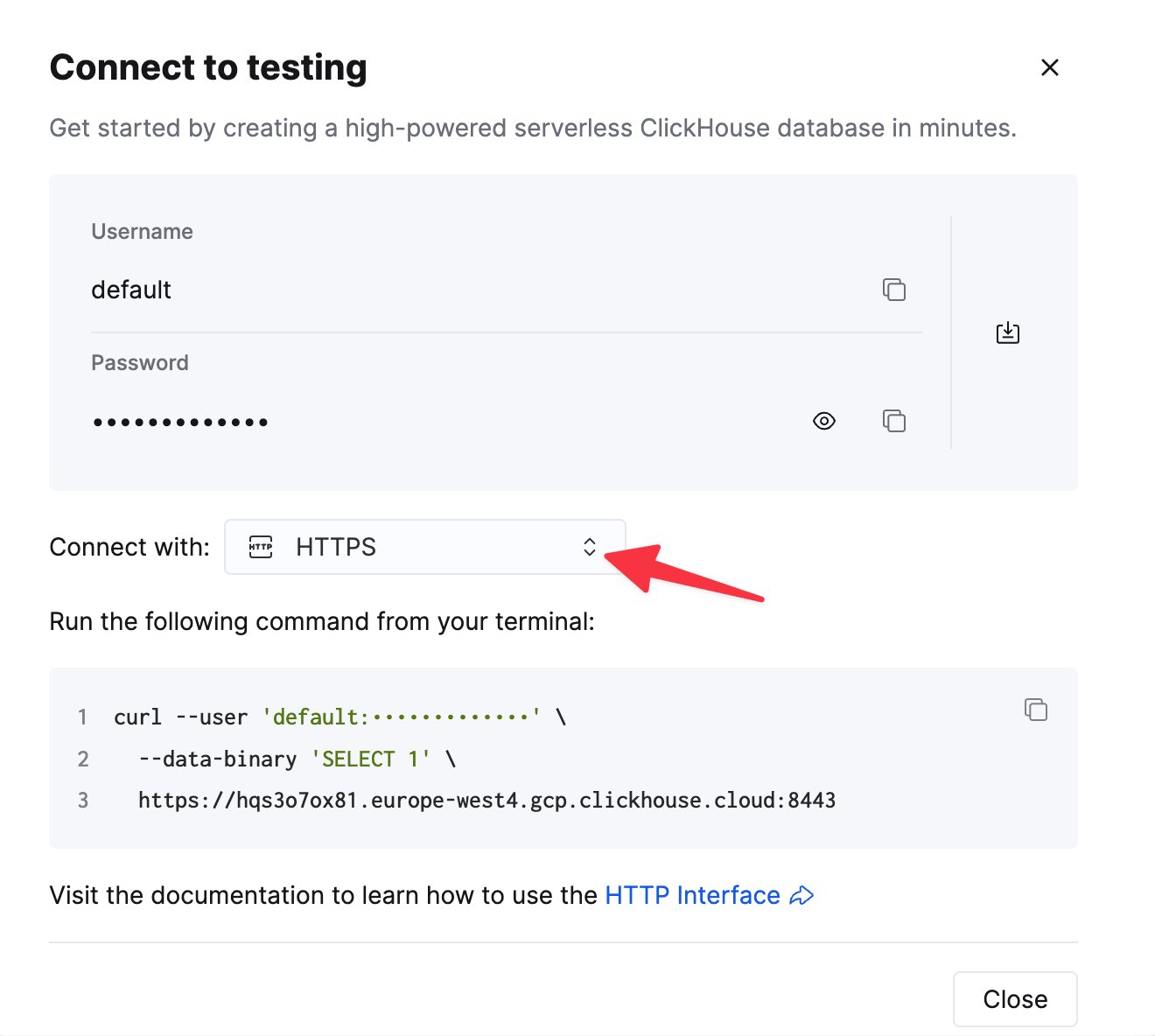
ClickHouse Cloud サービスの詳細は、ClickHouse Cloud コンソールで確認できます。
サービスを選択し、Connect をクリックします。
curl コマンドの例として表示されます。2
Apache NiFi をダウンロードして実行する
新規セットアップの場合は、https://nifi.apache.org/download.html からバイナリをダウンロードし、
./bin/nifi.sh start を実行して起動します3
ClickHouse JDBCドライバーをダウンロードする
- GitHub のClickHouse JDBCドライバーのリリースページにアクセスし、最新の JDBC リリースを確認します
- 該当するリリースで “Show all xx assets” をクリックし、“shaded” または “all” を含む JAR ファイルを探します (例:
clickhouse-jdbc-0.5.0-all.jar) - その JAR ファイルを Apache NiFi からアクセスできるフォルダーに配置し、絶対パスを控えておきます
4
`DBCPConnectionPool` Controller Service を追加し、そのプロパティを設定する
- Apache NiFi で Controller Service を設定するには、“gear” ボタンをクリックして NiFi Flow Configuration ページを開きます
-
Controller Services タブを選択し、右上の
+ボタンをクリックして新しい Controller Service を追加します -
DBCPConnectionPoolを検索し、“Add” ボタンをクリックします -
新しく追加した
DBCPConnectionPoolは、デフォルトでは Invalid 状態です。設定を開始するには、“gear” ボタンをクリックします - “Properties” セクションで、以下の値を入力します
- Settings セクションで、識別しやすいように Controller Service の名前を “ClickHouse JDBC” に変更します
-
“lightning” ボタンをクリックし、続けて “Enable” ボタンをクリックして
DBCPConnectionPoolController Service を有効にします
- Controller Services タブを確認し、Controller Service が有効になっていることを確認します
5
ExecuteSQL プロセッサを使用してテーブルから読み取る
-
適切な上流側および下流側のプロセッサとともに、
ExecuteSQLプロセッサを追加します -
ExecuteSQLプロセッサの “Properties” セクションで、次の値を入力します -
ExecuteSQLプロセッサを開始します -
クエリが正常に処理されたことを確認するには、出力キュー内の
FlowFileのいずれか 1 つを確認します -
出力
FlowFileの結果を表示するには、表示を “formatted” に切り替えます
6
`MergeRecord` と `PutDatabaseRecord` プロセッサを使用してテーブルに書き込む
-
1 回の insert で複数の行を書き込むには、まず複数のレコードを 1 つのレコードにマージする必要があります。これは
MergeRecordプロセッサを使用して行えます -
MergeRecordプロセッサの “Properties” セクションで、以下の値を入力します -
複数のレコードが 1 つにマージされていることを確認するには、
MergeRecordプロセッサの input と output を確認します。output は複数の input レコードからなる配列である点に注意してください Input Output -
PutDatabaseRecordプロセッサの “Properties” セクションで、以下の値を入力します -
各 insert に複数の行が含まれていることを確認するには、テーブルの行数が
MergeRecordで定義した “Minimum Number of Records” の値以上ずつ増えていることを確認します。 - これで、Apache NiFi を使用して ClickHouse にデータを正常にロードできました!