Kafka と ClickHouse で Vector を利用する
Kafka と ClickHouse で Vector を使用する
Vector はベンダー非依存のデータパイプラインであり、Kafka からデータを読み取り、ClickHouse にイベントを送信できます。
ClickHouse と組み合わせた Vector の入門ガイドでは、ログのユースケースとファイルからのイベント読み取りに焦点を当てています。ここでは、Kafka トピックに格納されたイベントを含む GitHub サンプルデータセットを利用します。
Vector は、プッシュまたはプルモデルでデータを取得するために sources を利用します。一方で sinks はイベントの送信先を提供します。したがって、Kafka source と ClickHouse sink を使用します。なお、Kafka は sink としてサポートされていますが、ClickHouse source は利用できません。その結果、Vector は ClickHouse から Kafka へデータを転送したいユーザーには適していません。
Vector はデータの変換にも対応していますが、これは本ガイドの範囲外です。この機能が必要な場合は、Vector のドキュメントを参照してください。
現在の ClickHouse sink の実装では HTTP インターフェースを利用している点に注意してください。ClickHouse sink は現時点では JSON スキーマの利用をサポートしていません。データはプレーンな JSON 形式、もしくは文字列として Kafka に送信される必要があります。
ライセンス
Vector は MPL-2.0 License の下で配布されています。
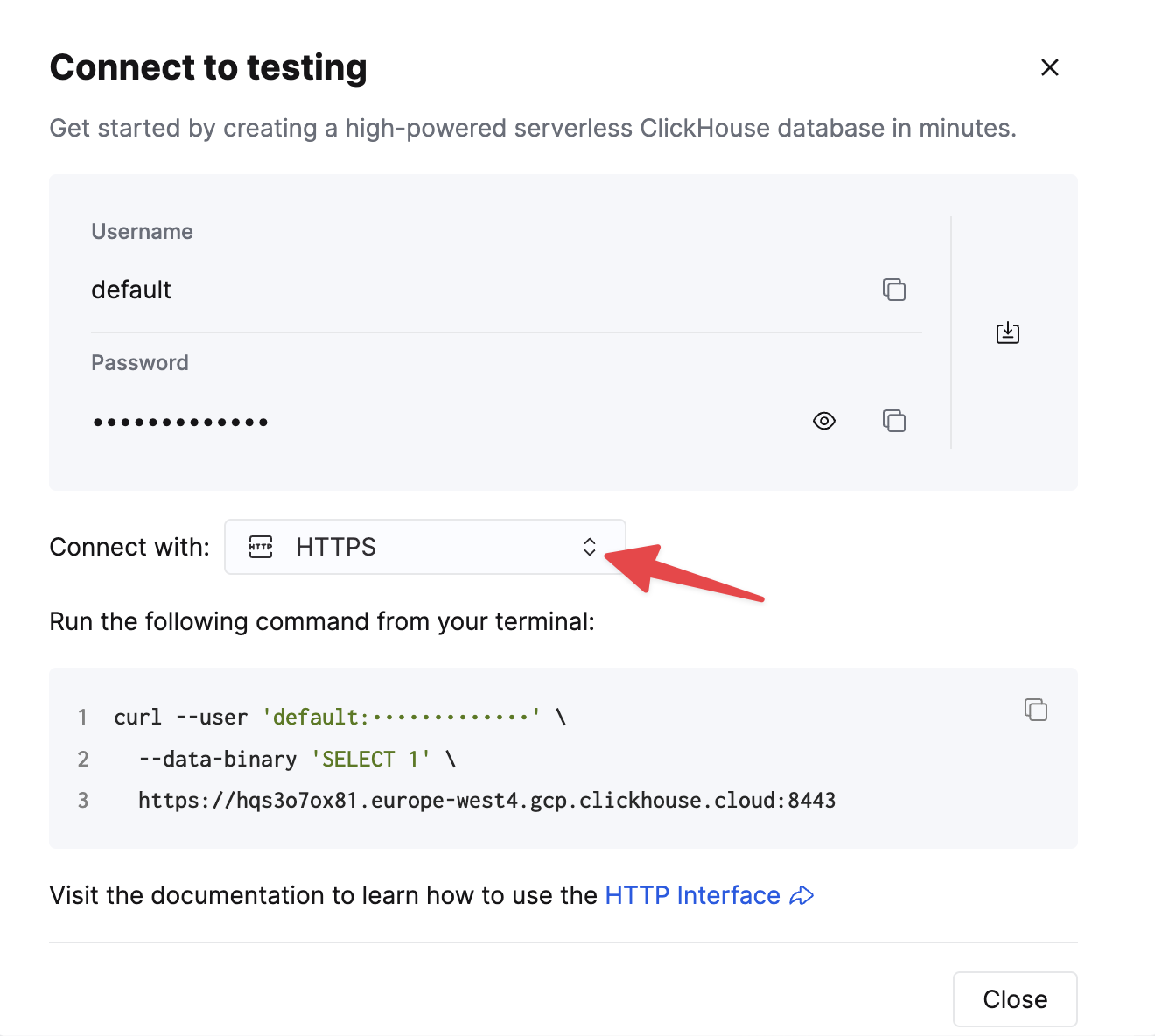
接続情報を確認する
HTTP(S) で ClickHouse に接続するには、次の情報が必要です。
| Parameter(s) | Description |
|---|---|
HOST and PORT | 通常、TLS を使用する場合のポートは 8443、TLS を使用しない場合のポートは 8123 です。 |
DATABASE NAME | 既定で default という名前のデータベースが用意されています。接続したいデータベースの名前を使用してください。 |
USERNAME and PASSWORD | 既定のユーザー名は default です。用途に応じて適切なユーザー名を使用してください。 |
ClickHouse Cloud サービスに関する詳細情報は、ClickHouse Cloud コンソールで確認できます。 サービスを選択し、Connect をクリックします。
HTTPS を選択します。接続情報は、サンプルの curl コマンド内に表示されます。
セルフマネージドの ClickHouse を使用している場合、接続情報は ClickHouse 管理者によって設定されます。
手順
- Kafka の
githubトピックを作成し、GitHub データセット を取り込みます。
このデータセットは、ClickHouse/ClickHouse リポジトリに焦点を当てた 200,000 行で構成されています。
- 対象テーブルが作成済みであることを確認します。以下では、デフォルトデータベースを使用します。
- Vectorをダウンロードしてインストールします。
kafka.toml設定ファイルを作成し、KafkaおよびClickHouseインスタンスに合わせて値を変更してください。
この設定と Vector の動作について、いくつか重要な注意点があります。
- この例は Confluent Cloud に対してテストされています。そのため、
sasl.*およびssl.enabledセキュリティオプションは、セルフマネージドなケースでは適切でない可能性があります。 - 設定パラメータ
bootstrap_serversにはプロトコルのプレフィックスは不要です(例:pkc-2396y.us-east-1.aws.confluent.cloud:9092)。 - ソースパラメータ
decoding.codec = "json"は、メッセージが単一の JSON オブジェクトとして ClickHouse sink に渡されることを保証します。メッセージを文字列として扱い、デフォルト値のbytesを使用する場合、メッセージの内容はフィールドmessageに格納されます。多くの場合、これは Vector getting started ガイドで説明しているように、ClickHouse 側での処理が必要になります。 - Vector はメッセージに対して多数のフィールドを追加します。この例では、ClickHouse sink の設定パラメータ
skip_unknown_fields = trueによって、これらのフィールドを無視しています。これは、ターゲットテーブルのスキーマに含まれないフィールドを無視する設定です。offsetのようなこれらのメタフィールドが追加されるように、スキーマを調整してもかまいません。 inputsパラメータによって、sink がイベントのソースを参照している点に注目してください。- ClickHouse sink の動作についてはこちらを参照してください。スループットを最適化するため、
buffer.max_events、batch.timeout_secs、batch.max_bytesパラメータのチューニングを検討してください。ClickHouse の推奨事項に従うと、1 バッチあたりのイベント数については、1000 を最小値として考慮する必要があります。スループットが一様に高いユースケースでは、buffer.max_eventsパラメータを増やすことができます。スループットにばらつきがある場合は、batch.timeout_secsパラメータの調整が必要になることがあります。 - パラメータ
auto_offset_reset = "smallest"は、Kafka ソースがトピックの先頭から読み取りを開始することを強制し、これによりステップ (1) で公開されたメッセージを確実に消費できるようにします。ユーザーによっては、異なる動作が必要になることがあります。詳細はこちらを参照してください。
- Vector を起動する
デフォルトでは、ClickHouse への挿入処理が開始される前に、health check が必要です。これにより、接続が確立できることと、スキーマが読み取れることが保証されます。問題が発生した場合に役立つ、より詳細なログを取得するには、コマンドの前に VECTOR_LOG=debug を付けて実行してください。
- データが挿入されたことを確認します。
| 件数 |
|---|
| 200000 |
