Kafka テーブルエンジンの使用
Kafka テーブルエンジンを使用すると、Apache Kafka およびその他の Kafka API 互換ブローカー (例: Redpanda、Amazon MSK) からデータを読み取ることも、それらにデータを書き込むこともできます。
Kafka から ClickHouse へ
ClickHouse Cloud をご利用の場合は、代わりに ClickPipes の使用を推奨します。ClickPipes は、プライベートネットワーク接続をネイティブにサポートし、インジェスト処理とクラスターリソースをそれぞれ独立してスケールでき、Kafka ストリーミングデータを ClickHouse に取り込むための包括的なモニタリングも提供します。
Kafka テーブルエンジンを使用するには、ClickHouse マテリアライズドビューの基本的な仕組みに精通している必要があります。
概要
まずは最も一般的なユースケース、つまり Kafka テーブルエンジンを使用して Kafka から ClickHouse にデータを挿入するケースに焦点を当てます。
Kafka テーブルエンジンにより、ClickHouse は Kafka トピックから直接読み取ることができます。トピック上のメッセージを表示する用途には有用ですが、このエンジンの設計上、取得は一度きりしか許可されません。すなわち、テーブルに対してクエリが発行されると、キューからデータを消費し、結果を呼び出し元に返す前にコンシューマオフセットを進めます。これらのオフセットをリセットしない限り、データを再度読み込むことは実質的にできません。
テーブルエンジンから読み取ったデータを永続化するには、データを取り込み、別のテーブルに挿入する手段が必要です。トリガーベースのマテリアライズドビューは、この機能をネイティブに提供します。マテリアライズドビューはテーブルエンジンに対して読み取りを開始し、ドキュメントのバッチを受信します。TO 句はデータの宛先を決定し、通常は Merge Tree ファミリーのテーブルになります。このプロセスは次の図のように示されています。
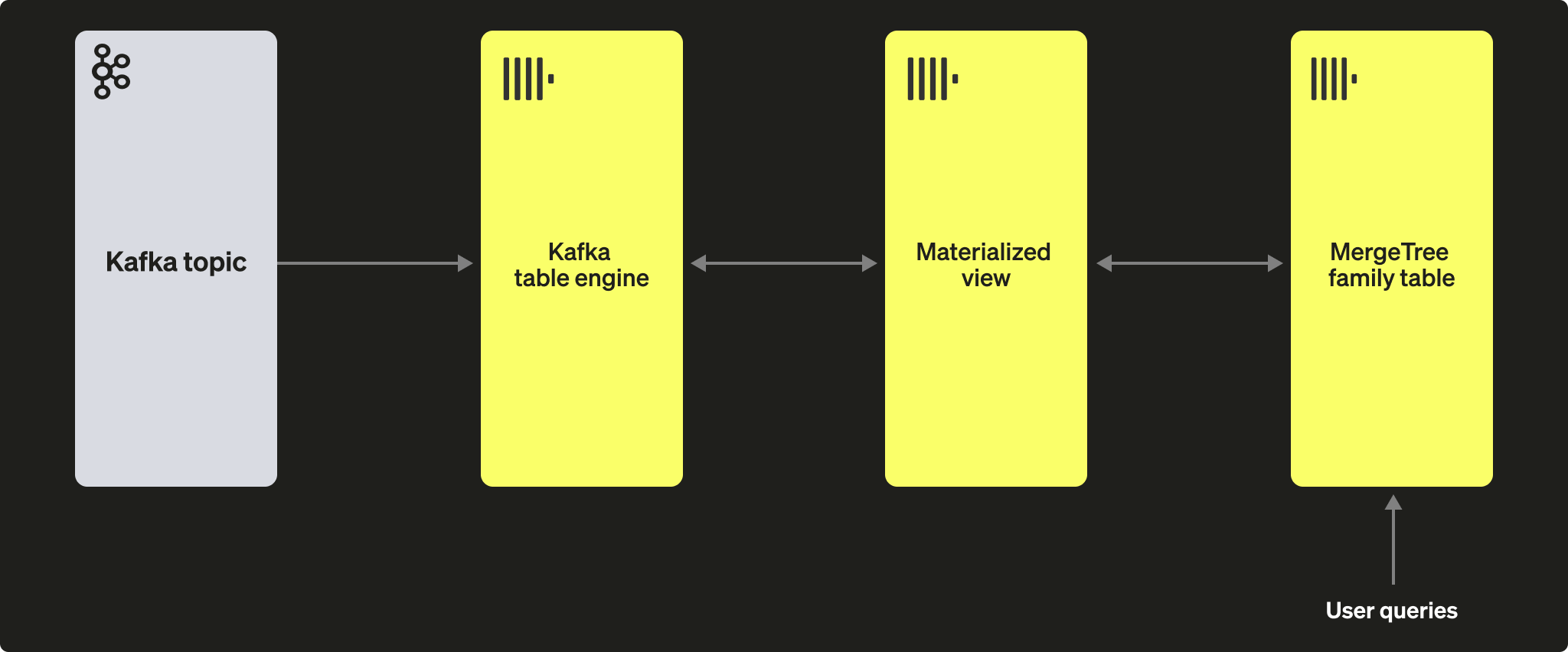
手順
1. 準備
対象のトピックにデータが入っている場合は、以下を自分のデータセット用に調整して利用できます。あるいは、サンプルの GitHub データセットがこちらに用意されています。このデータセットは以下の例で使用しており、スキーマを簡略化し、行もサブセットのみを使用しています(具体的には、ClickHouse リポジトリ に関する GitHub イベントに限定しています)。完全なデータセットはこちらから入手できますが、簡潔さのために縮小版を使用しています。それでも、このデータセットと共に公開されているクエリのほとんどを実行するには十分です。
2. ClickHouse の設定
セキュアな Kafka に接続する場合、この手順が必要です。これらの設定は SQL の DDL コマンドで渡すことはできず、ClickHouse の config.xml で設定する必要があります。ここでは、SASL で保護されたインスタンスに接続していることを前提とします。これは Confluent Cloud と連携する際に最も簡単な方法です。
上記のスニペットを conf.d/ ディレクトリ配下の新しいファイルに配置するか、既存の設定ファイルにマージしてください。設定可能なパラメータについてはこちらを参照してください。
このチュートリアルで使用するために、KafkaEngine という名前のデータベースも作成します。
データベースを作成したら、作成したデータベースに切り替えます。
3. 宛先テーブルを作成する
宛先テーブルを準備します。以下の例では、説明を簡潔にするために簡略化した GitHub スキーマを使用しています。MergeTree テーブルエンジンを使用していますが、この例は MergeTree family の任意のメンバーにも簡単に応用できます。
4. トピックを作成してデータを投入する
次に、トピックを作成します。これを行うために使えるツールはいくつかあります。自分のマシン上でローカルに、または Docker コンテナ内で Kafka を実行している場合は、RPK が便利です。次のコマンドを実行すると、github という名前でパーティション数 5 のトピックを作成できます。
Confluent Cloud 上で Kafka を実行している場合は、Confluent CLI を使うのがよいかもしれません:
次に、このトピックにデータを投入する必要があります。これには kcat を使用します。認証を無効にした状態でローカルで Kafka を実行している場合は、次のようなコマンドを実行できます。
または、Kafka クラスターで認証に SASL を使用している場合は、次のコマンドを実行します:
このデータセットには 200,000 行が含まれているため、取り込みは数秒で完了するはずです。より大きなデータセットを扱いたい場合は、GitHub リポジトリ ClickHouse/kafka-samples の large datasets セクション を参照してください。
5. Kafka テーブルエンジンを作成する
次の例では、MergeTree テーブルと同じスキーマを持つテーブルエンジンを作成します。これは必須ではなく、ターゲットテーブル側でエイリアス列や一時的な列を持つことも可能です。ただし設定は重要です。Kafka トピックから JSON を消費するためのデータ形式として JSONEachRow を使用している点に注意してください。github と clickhouse の値は、それぞれトピック名とコンシューマグループ名を表します。トピックは実際には値のリストを指定することもできます。
以下でエンジン設定とパフォーマンスチューニングについて説明します。この時点で、テーブル github_queue に対する単純な select により、いくつかの行が読み取れるはずです。なお、これによりコンシューマーのオフセットが進むため、リセット を行わない限り、これらの行を再度読み取ることはできなくなります。limit 句と、必須パラメータである stream_like_engine_allow_direct_select に注意してください。
6. マテリアライズドビューを作成する
マテリアライズドビューは、先ほど作成した 2 つのテーブルを接続し、Kafka テーブルエンジンからデータを読み取り、ターゲットの MergeTree テーブルに挿入します。さまざまなデータ変換が可能ですが、この例では単純な読み取りと挿入のみを行います。* を使用する場合、列名が同一であること(大文字・小文字を区別)が前提となります。
作成時点で、materialized view は Kafka エンジンに接続して読み取りを開始し、ターゲットテーブルに行を挿入します。この処理は、以降に Kafka へ挿入されたメッセージを順次消費しながら、無期限に継続します。Kafka にさらにメッセージを挿入するために、挿入スクリプトを再実行してもかまいません。
7. 行が挿入されたことを確認する
ターゲットテーブルにデータが存在することを確認します。
20万行が表示されているはずです。
一般的な操作
メッセージ消費の停止と再開
メッセージの消費を停止するには、Kafka エンジンテーブルをデタッチします。
この操作はコンシューマーグループのオフセットには影響しません。メッセージの消費を再開し、前回のオフセットから処理を続けるには、テーブルを再アタッチしてください。
Kafka メタデータの追加
元の Kafka メッセージが ClickHouse に取り込まれた後も、そのメタデータを保持しておけると便利な場合があります。例えば、特定のトピックやパーティションをどれだけ消費したかを把握したい場合です。この目的のために、Kafka テーブルエンジンはいくつかの仮想カラムを提供しています。スキーマとマテリアライズドビューの SELECT 文を変更することで、これらをターゲットテーブルのカラムとして永続化できます。
まず、ターゲットテーブルにカラムを追加する前に、上で説明した停止手順を実行します。
以下では、行がどのソーストピックおよびどのパーティションに由来したかを識別するための情報用カラムを追加します。
次に、バーチャルカラムが要件どおりにマッピングされていることを確認する必要があります。
バーチャルカラムには _ というプレフィックスが付きます。
バーチャルカラムの完全な一覧はこちらで確認できます。
テーブルをバーチャルカラムに対応させるには、マテリアライズドビューをいったんドロップし、Kafka エンジンテーブルを再アタッチしてから、マテリアライズドビューを再作成する必要があります。
新しく取り込まれた行にはメタデータが含まれるようになります。
結果は次のようになります:
| actor_login | event_type | created_at | topic | partition |
|---|---|---|---|---|
| IgorMinar | CommitCommentEvent | 2011-02-12 02:22:00 | github | 0 |
| queeup | CommitCommentEvent | 2011-02-12 02:23:23 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:23:24 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:24:50 | github | 0 |
| IgorMinar | CommitCommentEvent | 2011-02-12 02:25:20 | github | 0 |
| dapi | CommitCommentEvent | 2011-02-12 06:18:36 | github | 0 |
| sourcerebels | CommitCommentEvent | 2011-02-12 06:34:10 | github | 0 |
| jamierumbelow | CommitCommentEvent | 2011-02-12 12:21:40 | github | 0 |
| jpn | CommitCommentEvent | 2011-02-12 12:24:31 | github | 0 |
| Oxonium | CommitCommentEvent | 2011-02-12 12:31:28 | github | 0 |
Kafka エンジン設定の変更
Kafka エンジンテーブルを削除し、新しい設定で再作成することを推奨します。この手順の実行中も、マテリアライズドビューを変更する必要はありません。Kafka エンジンテーブルが再作成されると、メッセージの消費は自動的に再開されます。
問題のデバッグ
認証の問題などのエラーは、Kafka エンジンの DDL に対する応答には報告されません。問題を診断するには、メインの ClickHouse ログファイルである clickhouse-server.err.log を使用することを推奨します。背後で使用されている Kafka クライアントライブラリ librdkafka の詳細なトレースログは、設定で有効にできます。
不正なメッセージの扱い
Kafka はしばしばデータの「投げ込み先」として利用されます。これにより、1 つのトピック内に異なるメッセージ形式や一貫性のないフィールド名が混在する状況が発生します。これを避けるため、Kafka Streams や ksqlDB などの Kafka の機能を活用し、メッセージが Kafka へ挿入される前に正しい形式かつ一貫した内容になるようにしてください。これらのオプションが利用できない場合でも、ClickHouse には役立つ機能がいくつかあります。
- メッセージフィールドを文字列として扱います。必要に応じて、マテリアライズドビューのステートメント内で関数を使用してクレンジングや型変換を行うことができます。これは本番環境向けの解決策ではありませんが、単発のインジェストに役立つ可能性があります。
- トピックから JSON を
JSONEachRow形式で消費している場合は、設定input_format_skip_unknown_fieldsを使用します。データを書き込む際、デフォルトでは ClickHouse は、入力データに対象テーブルに存在しないカラムが含まれていると例外をスローします。しかし、このオプションを有効にすると、これらの余分なカラムは無視されます。ただし、これも本番レベルの解決策ではなく、他の利用者を混乱させる可能性があります。 - 設定
kafka_skip_broken_messagesの利用を検討してください。これは、不正なメッセージに対するブロックごとの許容レベルを、kafka_max_block_sizeのコンテキストで指定する必要があります。この許容値を超えた場合(メッセージ数で測定)、通常の例外動作に戻り、残りのメッセージはスキップされます。
配信セマンティクスと重複に関する課題
Kafka テーブルエンジンは at-least-once セマンティクスを持ちます。いくつかの、既知ではあるものの稀な状況では重複が発生する可能性があります。例えば、Kafka からメッセージを読み取り、ClickHouse への挿入に成功したとします。新しいオフセットをコミットする前に Kafka への接続が失われる可能性があります。この状況ではブロックの再試行が必要になります。このブロックは、分散テーブルまたは ReplicatedMergeTree をターゲットテーブルとして利用することで重複排除される場合があります。これは重複行の可能性を減らしますが、同一ブロックであることに依存しています。Kafka のリバランスなどのイベントによりこの前提が成り立たなくなると、稀な状況では重複が発生し得ます。
クォーラムベースの挿入
ClickHouse でより高い配信保証が必要なケースでは、クォーラムベースの挿入が必要になることがあります。これはマテリアライズドビューやターゲットテーブルでは設定できませんが、ユーザープロファイルには設定できます。例:
ClickHouse から Kafka へ
あまり一般的ではないユースケースですが、ClickHouse のデータを Kafka に永続化することもできます。例として、Kafka テーブルエンジンに対して行を手動で挿入します。このデータは同じ Kafka エンジンによって読み取られ、そのマテリアライズドビューによって MergeTree テーブルに格納されます。最後に、既存のソーステーブルからテーブルを読み取れるようにするため、Kafka への挿入にマテリアライズドビューを適用する方法を示します。
手順
最初の目的とする構成は、次の図のとおりです。
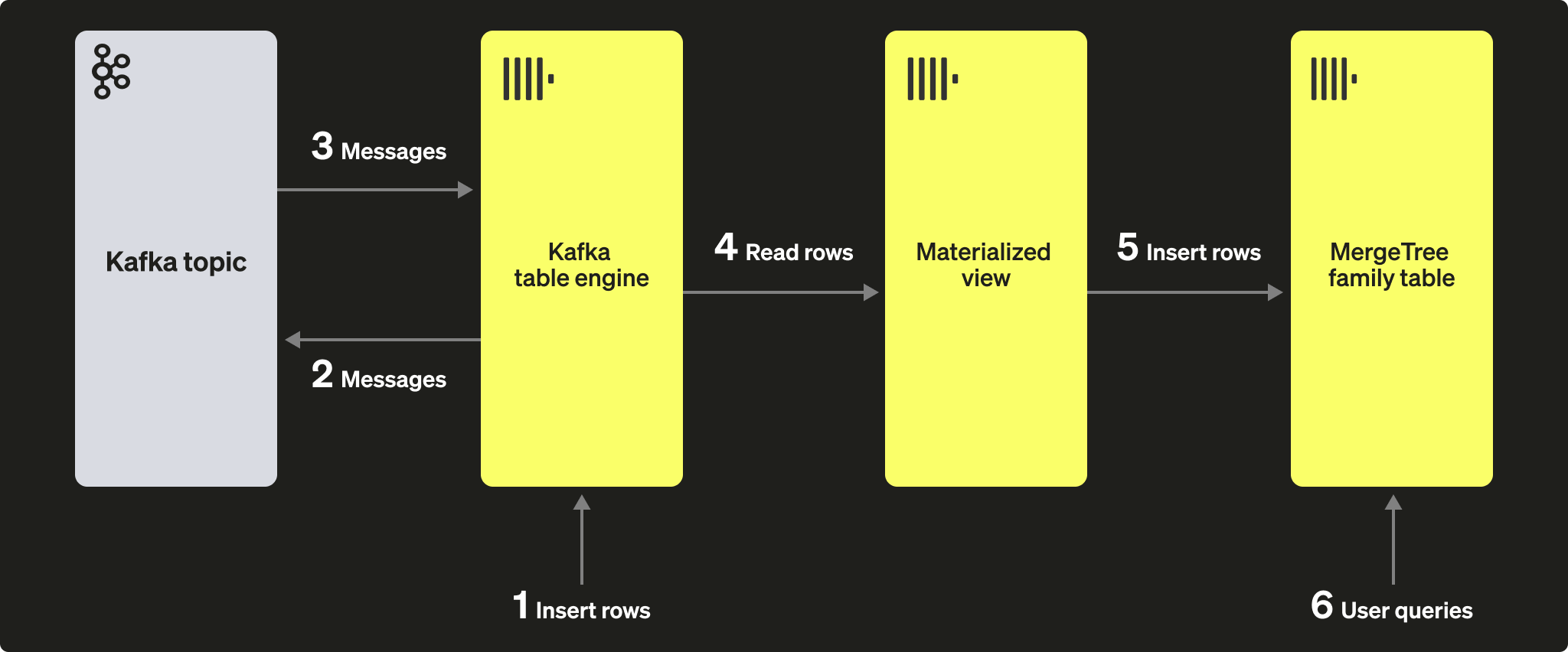
Kafka から ClickHouse の手順でテーブルとビューが作成済みであり、トピックが完全に消費されていることを前提とします。
1. 行を直接挿入する
まず、対象テーブルの件数を確認します。
20万行あるはずです。
次に、GitHub のターゲットテーブルから行を取得し、Kafka テーブルエンジン github_queue に再度挿入します。JSONEachRow フォーマットを利用し、SELECT に LIMIT 100 を指定している点に注目してください。
GitHub の行数を再度数えて、100 行増えていることを確認します。上の図に示されているように、行はまず Kafka テーブルエンジンを通じて Kafka に挿入され、その後同じエンジンによって再読み取りされ、マテリアライズドビューによって GitHub のターゲットテーブルに挿入されています!
100 行増えているはずです。
2. マテリアライズドビューの使用
テーブルにドキュメントが挿入されたときに、メッセージを Kafka エンジン(およびトピック)へ送信するために、マテリアライズドビューを利用できます。GitHub テーブルに行が挿入されると、マテリアライズドビューがトリガーされ、その行が Kafka エンジンおよび新しいトピックに再度挿入されます。これも次の図を見るのが最も分かりやすいでしょう。
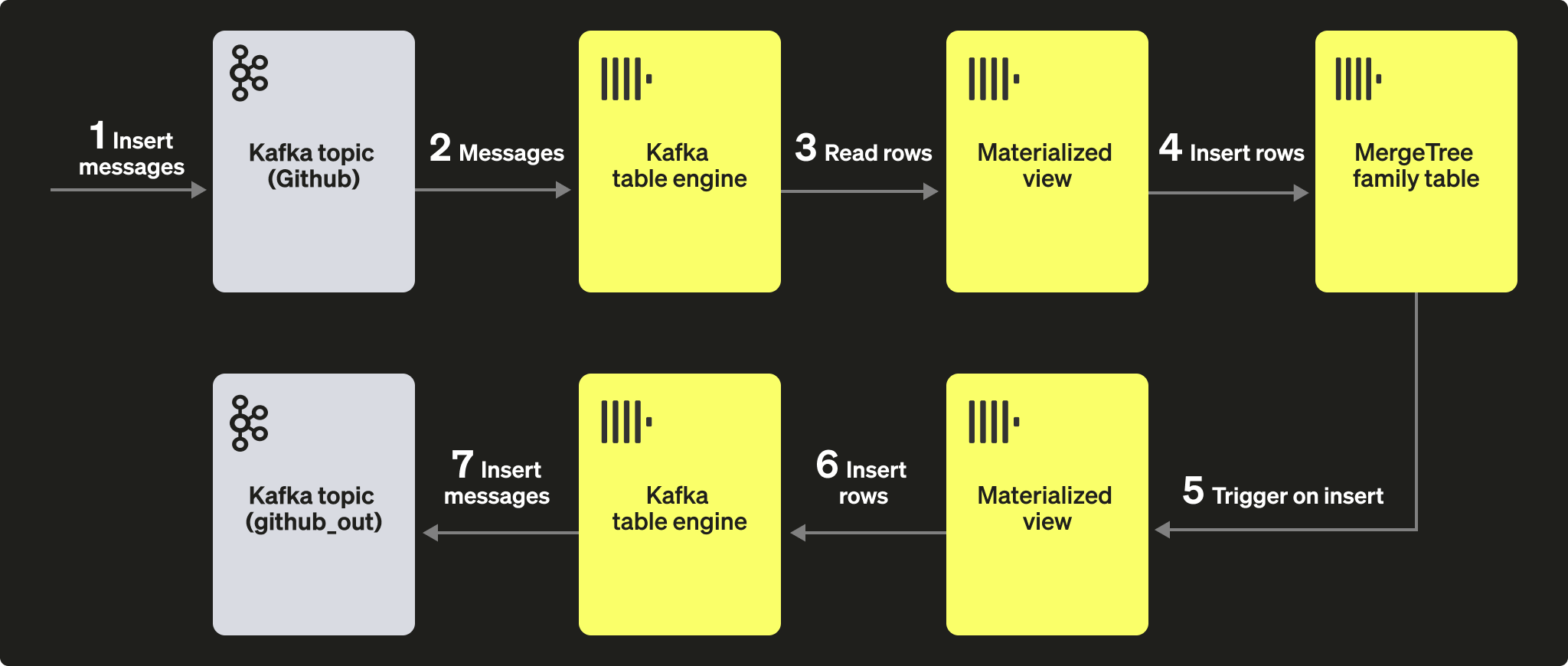
新しい Kafka トピック github_out(または同等のもの)を作成します。Kafka テーブルエンジン github_out_queue がこのトピックを参照するように設定してください。
次に、新しいマテリアライズドビュー github_out_mv を作成し、GitHub テーブルをソースとして、トリガー時に上記のエンジンへ行を挿入するようにします。その結果、GitHub テーブルに追加されたデータは、新しい Kafka トピックへ送信されるようになります。
Kafka to ClickHouse の一部として作成した元の GitHub トピックにデータを挿入すると、ドキュメントが自動的に "github_clickhouse" トピックに現れます。これを Kafka のネイティブツールを使って確認してください。例えば、以下では Confluent Cloud 上でホストされているトピックに対して、kcat を使用して GitHub トピックに 100 行を挿入します。
github_out トピックを読み取れば、メッセージが配信されたことを確認できるはずです。
やや込み入った例ではありますが、Kafka エンジンと組み合わせて使用した場合のマテリアライズドビューの強力さを示しています。
クラスターとパフォーマンス
ClickHouse クラスターの利用
Kafka のコンシューマグループを通じて、複数の ClickHouse インスタンスが同じトピックから読み取ることが可能です。各コンシューマには、トピックパーティションが 1:1 で割り当てられます。Kafka テーブルエンジンを使って ClickHouse によるコンシュームをスケールさせる場合、クラスター内のコンシューマ総数はトピック上のパーティション数を超えられないことに注意してください。そのため、事前にトピックに対して適切なパーティショニング設定を行っておく必要があります。
複数の ClickHouse インスタンスは、同一のコンシューマグループ ID(Kafka テーブルエンジン作成時に指定)を使用して、同じトピックから読み取るようにすべて設定できます。その結果、各インスタンスは 1 つ以上のパーティションから読み取り、自身のローカルのターゲットテーブルにセグメントを挿入します。ターゲットテーブルは、データの重複処理を行うために ReplicatedMergeTree を使用するように設定できます。この方法により、十分な Kafka パーティションが存在する限り、Kafka からの読み取りを ClickHouse クラスターに合わせてスケールさせることができます。
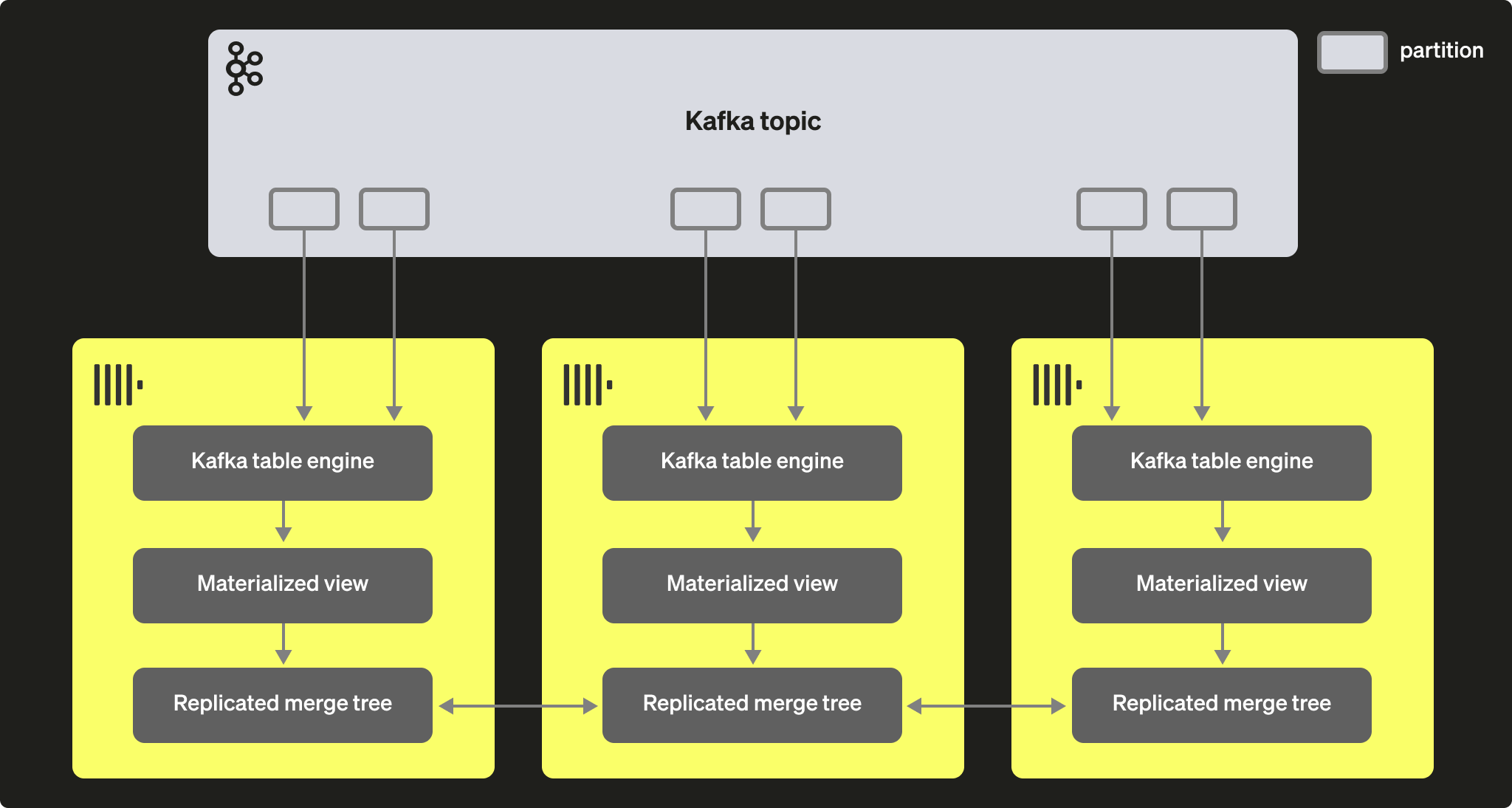
パフォーマンスチューニング
Kafka エンジンテーブルのスループットを向上させたい場合、次の点を検討してください。
- 性能はメッセージサイズ、フォーマット、ターゲットテーブルの種類によって変動します。単一のテーブルエンジンで 100k rows/sec(10 万行/秒)程度は達成可能と考えられます。デフォルトでは、メッセージはブロック単位で読み取られ、これはパラメータ kafka_max_block_size によって制御されます。既定では、これは max_insert_block_size に設定されており、デフォルト値は 1,048,576 です。メッセージが極端に大きくない限り、この値はほぼ常に増やすべきです。500k〜1M の範囲の値は珍しくありません。スループットへの影響をテストして評価してください。
- テーブルエンジンのコンシューマ数は kafka_num_consumers で増やすことができます。ただし、デフォルトでは、kafka_thread_per_consumer がデフォルト値の 1 のままの場合、挿入は単一スレッドで直列化されます。フラッシュが並列に行われるようにするには、これを 1 に設定してください。N 個のコンシューマ(かつ kafka_thread_per_consumer=1)を持つ Kafka エンジンテーブルを作成することは、論理的には、N 個の Kafka エンジンを作成し、それぞれにマテリアライズドビューを持たせ、kafka_thread_per_consumer=0 とすることと等価です。
- コンシューマを増やすことは「無料」の操作ではありません。各コンシューマは独自のバッファとスレッドを保持し、サーバー上のオーバーヘッドを増加させます。コンシューマのオーバーヘッドを意識し、まずは可能であればクラスター全体で線形にスケールさせてください。
- Kafka メッセージのスループットが変動し、遅延が許容される場合は、より大きなブロックがフラッシュされるように stream_flush_interval_ms を増やすことを検討してください。
- background_message_broker_schedule_pool_size はバックグラウンドタスクを実行するスレッド数を設定します。これらのスレッドは Kafka ストリーミングに使用されます。この設定は ClickHouse サーバーの起動時に適用され、ユーザーセッション内では変更できません。デフォルトは 16 です。ログにタイムアウトが見られる場合は、この値を増やすことが適切な場合があります。
- Kafka との通信には librdkafka ライブラリが使用されており、このライブラリ自体もスレッドを生成します。大量の Kafka テーブルやコンシューマが存在すると、多数のコンテキストスイッチが発生する可能性があります。この負荷をクラスター全体に分散し、可能であればターゲットテーブルのみをレプリケートするか、または複数トピックから読み取るテーブルエンジンの使用を検討してください(値のリストを指定できます)。複数のマテリアライズドビューを単一のテーブルから読み取り、それぞれ特定のトピックのデータのみにフィルタリングできます。
あらゆる設定変更はテストする必要があります。適切にスケールできていることを確認するため、Kafka のコンシューマラグをモニタリングすることを推奨します。
追加設定
上記で説明した設定以外にも、次の項目が参考になる場合があります。
- Kafka_max_wait_ms - 再試行前に Kafka からメッセージを読み込む際の待機時間(ミリ秒単位)。ユーザープロファイル単位で設定され、デフォルトは 5000 です。
基盤となる librdkafka の すべての設定は、ClickHouse の設定ファイル内の kafka 要素の中にも記述できます。設定名は、ピリオドをアンダースコアに置き換えた XML 要素として指定する必要があります(例)。
これらは上級者向けの設定であるため、より詳しい説明については Kafka のドキュメントを参照してください。
