このコネクタは、データがシンプルで、int などのプリミティブなデータ型だけで構成されている場合にのみ使用してください。Map などの ClickHouse 固有の型はサポートされていません。
ライセンス
手順
接続情報を確認する
ClickHouse Cloud サービスの詳細は、ClickHouse Cloud コンソールで確認できます。
サービスを選択し、Connect をクリックします。
curl コマンドの例として表示されます。
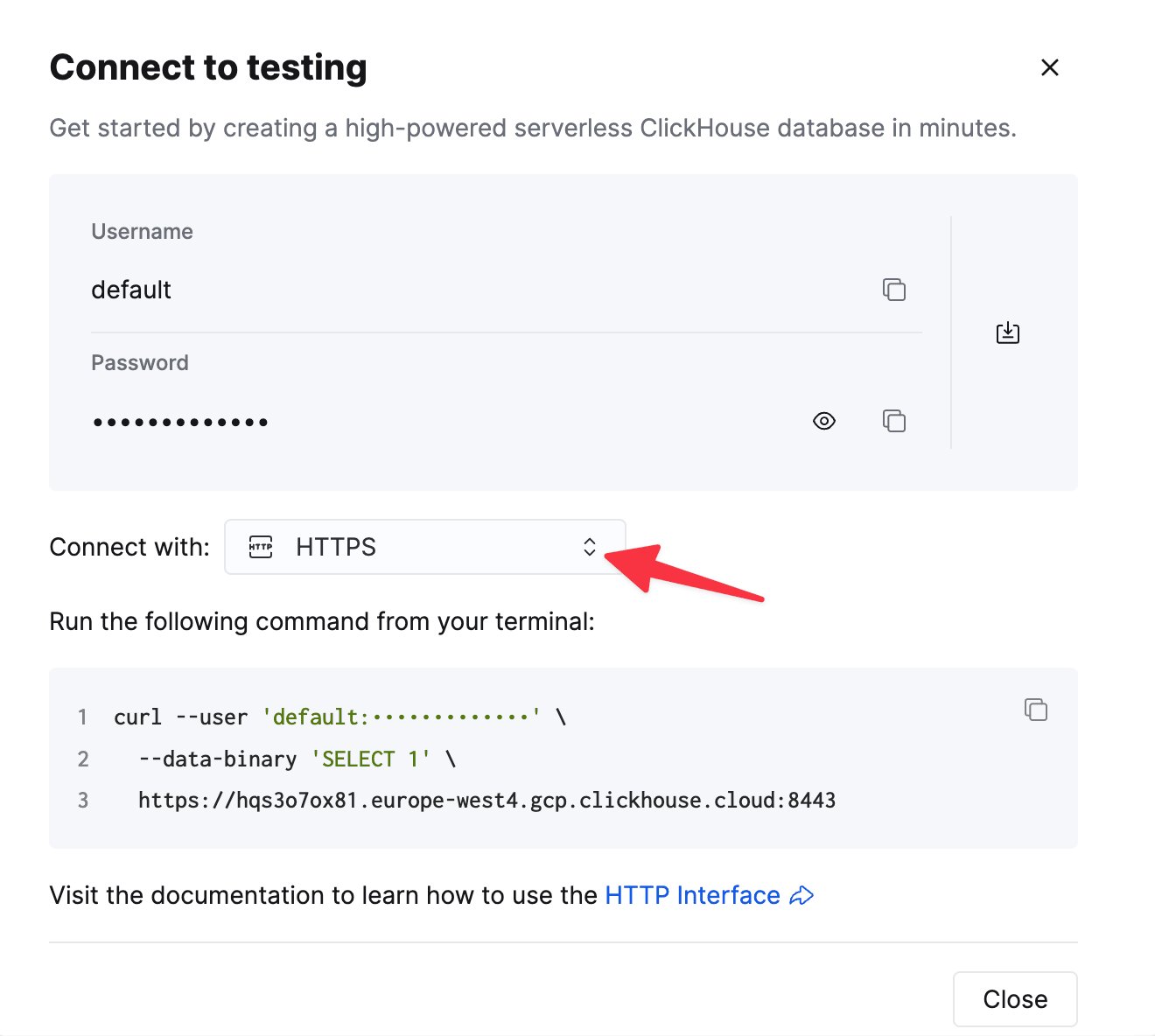
1
Kafka Connect とコネクタをインストールする
Confluent パッケージをダウンロードし、ローカル環境にインストール済みであることを前提としています。コネクタのインストールについては、こちらに記載されている手順に従ってください。
confluent-hub を使用してインストールする場合、ローカルの設定ファイルが更新されます。Kafka から ClickHouse にデータを送信するには、コネクタの Sink コンポーネントを使用します。2
JDBC ドライバーをダウンロードしてインストールする
こちらから ClickHouse JDBCドライバー
clickhouse-jdbc-<version>-shaded.jar をダウンロードしてインストールしてください。Kafka Connect へのインストールは、こちらの手順に従ってください。他のドライバーでも動作する可能性はありますが、テストは行っていません。よくある問題: ドキュメントでは jar を
share/java/kafka-connect-jdbc/ にコピーするよう案内されています。Connect がドライバーを見つけられない場合は、ドライバーを share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib/ にコピーしてください。あるいは、plugin.path を変更してドライバーを含めてください。詳細は以下を参照してください。3
設定を準備する
インストール形態に応じた Connect の設定については、スタンドアロン クラスターと 分散 クラスターの違いに注意しつつ、こちらの手順に従ってください。Confluent Cloud を使用する場合は、分散 構成が該当します。以下のパラメータは、ClickHouse で JDBC コネクタを使用する際に重要です。パラメータの完全な一覧はこちらで確認できます。
_connection.url_-jdbc:clickhouse://<clickhouse host>:<clickhouse http port>/<target database>の形式で指定する必要がありますconnection.user- 移行先データベースへの書き込み権限を持つユーザーtable.name.format- データの挿入先となる ClickHouse テーブル。事前に存在している必要があります。batch.size- 1 回のバッチで送信する行数です。適切に大きな値を設定してください。ClickHouse の推奨事項では、1000 を最低値の目安とすることを推奨しています。tasks.max- JDBC Sink コネクタは 1 つ以上の task の実行をサポートしています。これはパフォーマンス向上に利用できます。batch size とあわせて、パフォーマンス改善の主要な手段となります。value.converter.schemas.enable- スキーマレジストリを使用する場合は false、メッセージ内にスキーマを埋め込む場合は true に設定します。value.converter- データ型に応じて設定します。たとえば JSON の場合はio.confluent.connect.json.JsonSchemaConverterです。key.converter-org.apache.kafka.connect.storage.StringConverterに設定します。String の key を利用します。pk.mode- ClickHouse では関係ありません。none に設定します。auto.create- サポートされていないため、false にする必要があります。auto.evolve- 将来的にサポートされる可能性はありますが、この設定は false を推奨します。insert.mode- “insert” に設定します。現在、他のモードはサポートされていません。key.converter- key の型に応じて設定します。value.converter- topic 上のデータ型に応じて設定します。このデータには、JSON、Avro、または Protobuf フォーマットのいずれかでサポートされるスキーマが必要です。
value.converter.schemas.enable- スキーマレジストリを利用するため false に設定します。各メッセージにスキーマを埋め込む場合は true に設定します。key.converter- “org.apache.kafka.connect.storage.StringConverter” に設定します。String の key を利用します。value.converter- “io.confluent.connect.json.JsonSchemaConverter” に設定します。value.converter.schema.registry.url- スキーマサーバーの URL を設定し、あわせてパラメータvalue.converter.schema.registry.basic.auth.user.infoでスキーマサーバーの認証情報を設定します。
4
ClickHouse テーブルを作成する
テーブルが作成されていることを確認し、以前の例ですでに存在している場合は削除してください。縮小版の GitHub dataset に対応した例を以下に示します。現在サポートされていない Array 型や Map 型が含まれていない点に注意してください:
6
Kafka にデータを投入する
提供されているスクリプトと設定を使用して、Kafka にメッセージを送信します。このスクリプトを使うと、任意の ndjson ファイルを Kafka topic に挿入できます。スキーマの自動推論も試みます。提供されているサンプル config では 10k 件のメッセージしか挿入されません。必要に応じてこちらで変更してください。この設定では、Kafka への挿入時にデータセットから互換性のない Array フィールドも削除されます。これは、JDBC コネクタがメッセージを INSERT 文に変換するために必要です。独自のデータを使用する場合は、すべてのメッセージにスキーマを含めて挿入する (_value.converter.schemas.enable _を true に設定する) か、client がスキーマレジストリ内のスキーマを参照するメッセージを公開するようにしてください。Kafka Connect はメッセージの消費を開始し、ClickHouse への行の挿入を開始するはずです。“[JDBC Compliant Mode] Transaction isn’t supported.” に関する警告は想定内であり、無視してかまいません。ターゲットテーブル “Github” を単純に読み取れば、データが挿入されたことを確認できるはずです。
github.config を変更して、Kafka の認証情報を含める必要があります。このスクリプトは現在、Confluent Cloud で使用するように設定されています。