Confluent HTTP sink connector
The HTTP Sink Connector はデータ型に依存しないため、Kafka のスキーマを必要とせず、Map や Array などの ClickHouse 固有のデータ型にも対応しています。この柔軟性が高まる一方で、設定はやや複雑になります。
以下では、単一の Kafkaトピック からメッセージを取得し、ClickHouse テーブルに行を挿入するシンプルなインストール方法について説明します。
HTTP Connector は Confluent Enterprise License に基づいて配布されています。
クイックスタート手順
1. 接続情報を収集する
HTTP(S) で ClickHouse に接続するには、次の情報が必要です。
| Parameter(s) | Description |
|---|---|
HOST and PORT | 通常、TLS を使用する場合のポートは 8443、TLS を使用しない場合のポートは 8123 です。 |
DATABASE NAME | 既定で default という名前のデータベースが用意されています。接続したいデータベースの名前を使用してください。 |
USERNAME and PASSWORD | 既定のユーザー名は default です。用途に応じて適切なユーザー名を使用してください。 |
ClickHouse Cloud サービスに関する詳細情報は、ClickHouse Cloud コンソールで確認できます。 サービスを選択し、Connect をクリックします。
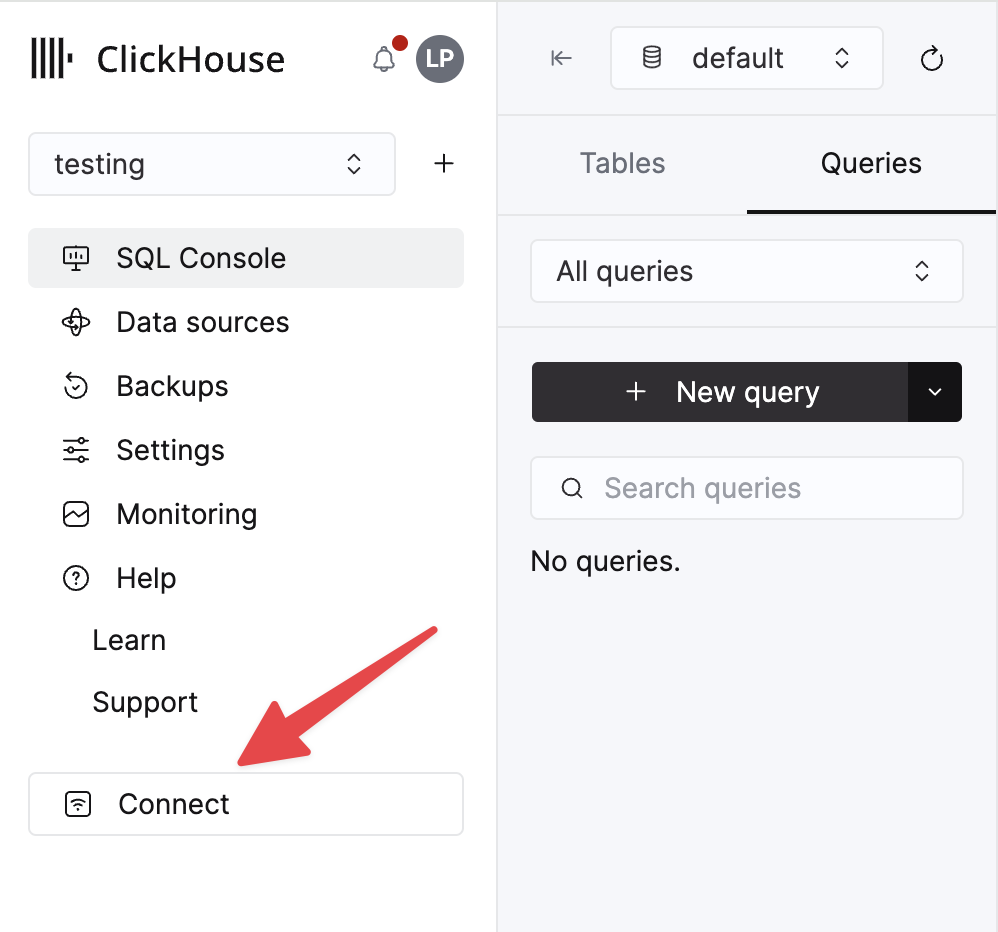
HTTPS を選択します。接続情報は、サンプルの curl コマンド内に表示されます。
セルフマネージドの ClickHouse を使用している場合、接続情報は ClickHouse 管理者によって設定されます。
2. Kafka Connect と HTTP シンクコネクタを実行する
選択肢は 2 つあります。
-
セルフマネージド: Confluent パッケージをダウンロードしてローカルにインストールします。こちら に記載されているコネクタのインストール手順に従ってください。 confluent-hub のインストール方法を使用する場合、ローカルの設定ファイルが更新されます。
-
Confluent Cloud: Kafka のホスティングに Confluent Cloud を使用しているユーザー向けに、完全マネージド版の HTTP Sink コネクタが利用可能です。これには、Confluent Cloud から ClickHouse 環境へアクセス可能である必要があります。
以下の例では Confluent Cloud を使用しています。
3. ClickHouse に宛先テーブルを作成する
接続テストの前に、まず ClickHouse Cloud にテストテーブルを作成します。このテーブルは Kafka からのデータを受信します。
4. HTTP Sink の設定
Kafka トピックと HTTP Sink Connector のインスタンスを作成します:
HTTP Sink Connector を次のように設定します:
- 作成したトピック名を指定
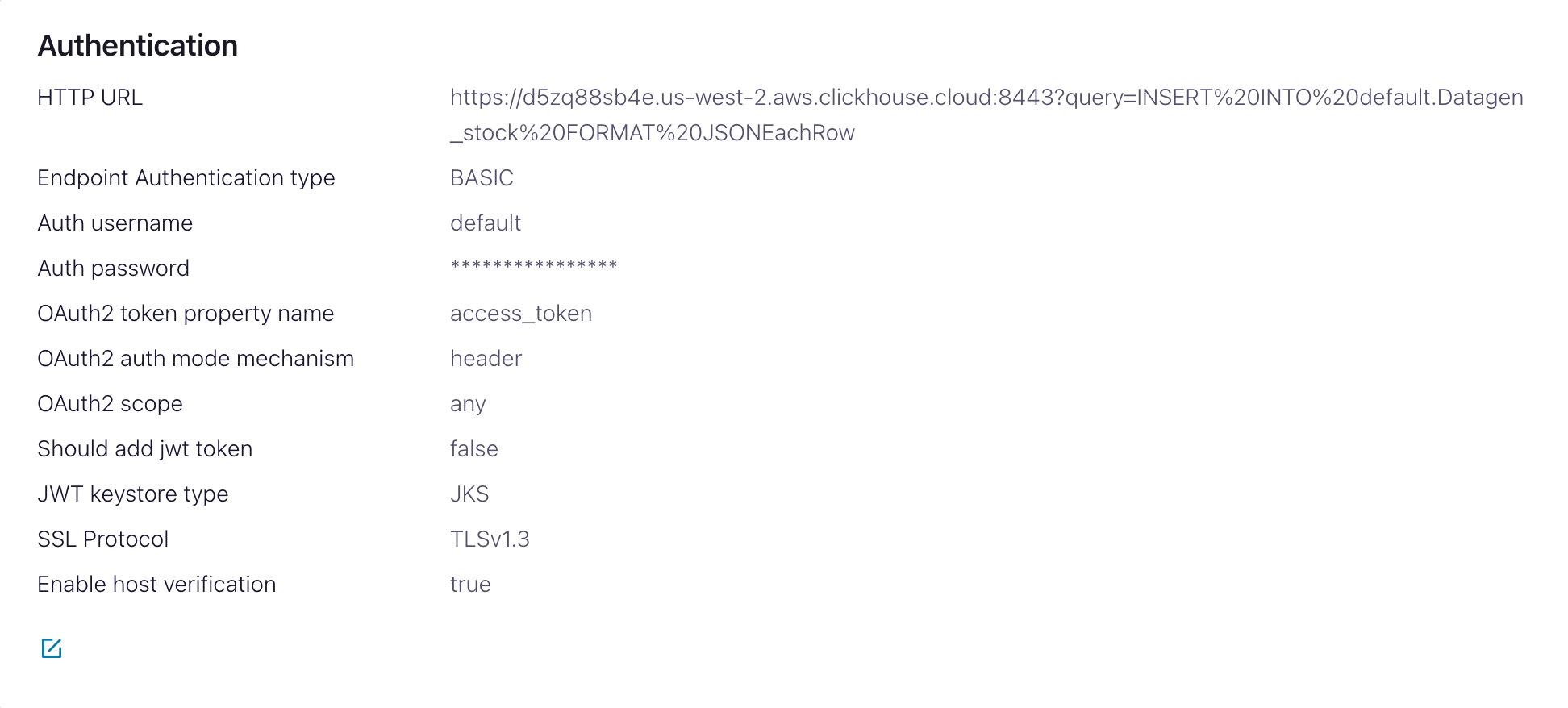
- Authentication
HTTP Url-INSERTクエリを指定した ClickHouse Cloud の URL<protocol>://<clickhouse_host>:<clickhouse_port>?query=INSERT%20INTO%20<database>.<table>%20FORMAT%20JSONEachRow。Note: クエリはエンコードされている必要があります。Endpoint Authentication type- BASICAuth username- ClickHouse のユーザー名Auth password- ClickHouse のパスワード
この HTTP Url はエラーになりやすい値です。問題を避けるため、エスケープが正確であることを確認してください。
- Configuration
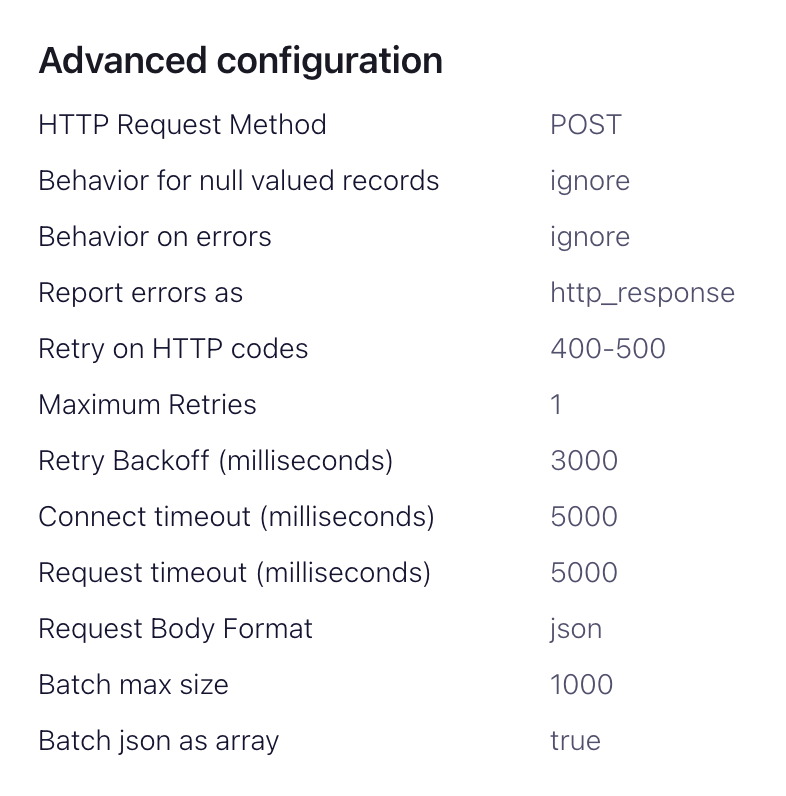
Input Kafka record value formatはソースデータに依存しますが、ほとんどの場合 JSON か Avro です。以降の設定ではJSONを前提とします。advanced configurationsセクション:HTTP Request Method- POST に設定Request Body Format- jsonBatch batch size- ClickHouse の推奨に従い、少なくとも 1000 に設定します。Batch json as array- trueRetry on HTTP codes- 400-500 を指定しますが、必要に応じて調整してください。例: ClickHouse の前段に HTTP プロキシがある場合は変更が必要な場合があります。Maximum Reties- デフォルト値 (10) で問題ありませんが、より堅牢なリトライが必要であれば調整してください。
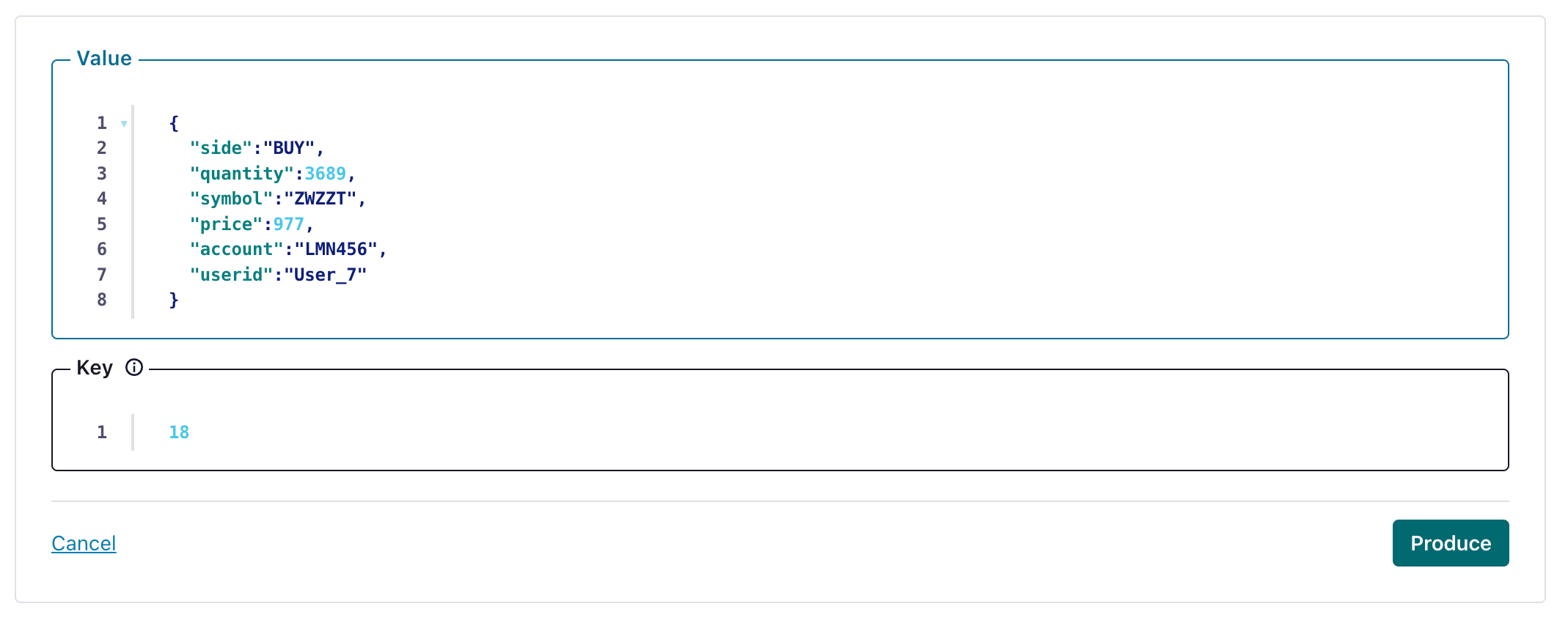
5. 接続テスト
HTTP Sink で設定したトピックにメッセージを 1 件作成します。
そのメッセージが ClickHouse インスタンスに書き込まれていることを確認します。
トラブルシューティング
HTTP Sink がメッセージをバッチ処理しない
HTTP Sink コネクタは、Kafka ヘッダー値が異なるメッセージに対してはリクエストをバッチ処理しません。
- すべての Kafka レコードが同じキーを持っていることを確認します。
- HTTP API の URL にパラメータを追加すると、各レコードごとに一意の URL になる可能性があります。このため、追加の URL パラメータを使用している場合はバッチ処理が無効になります。
400 bad request
CANNOT_PARSE_QUOTED_STRING
String 列に JSON オブジェクトを挿入する際に、HTTP Sink が次のメッセージとともに失敗した場合:
URL に設定として input_format_json_read_objects_as_strings=1 を、URL エンコードした文字列 SETTINGS%20input_format_json_read_objects_as_strings%3D1 として指定します。
GitHub データセットをロードする(オプション)
このサンプルでは、GitHub データセットの Array フィールドが保持される点に注意してください。examples 内に空の GitHub トピックが存在し、Kafka へのメッセージ投入には kcat を使用することを前提とします。
1. 設定の準備
インストール形態に応じた Connect のセットアップについては、スタンドアロン構成と分散クラスタ構成の違いに留意しつつ、この手順に従ってください。Confluent Cloud を利用している場合は、分散構成が該当します。
最も重要なパラメータは http.api.url です。ClickHouse の HTTP インターフェイス では、INSERT 文を URL のパラメータとしてエンコードする必要があります。ここにはフォーマット(この例では JSONEachRow)と対象データベースを含めなければなりません。フォーマットは Kafka データと整合している必要があり、Kafka データは HTTP ペイロード内で文字列に変換されます。これらのパラメータは URL エスケープする必要があります。GitHub データセット向けのこのフォーマットの例(ClickHouse をローカルで実行していると仮定)は、以下のとおりです。
ClickHouse で HTTP Sink を使用する場合、次の追加パラメーターが重要です。パラメーターの完全な一覧はこちらを参照してください。
request.method- POST に設定します。retry.on.status.codes- 任意のエラーコードでリトライするために 400-500 に設定します。データで想定されるエラーに基づいて適宜調整してください。request.body.format- ほとんどの場合は JSON になります。auth.type- ClickHouse 側で認証を有効にしている場合は BASIC に設定します。他の ClickHouse 互換の認証メカニズムは現在サポートされていません。ssl.enabled- SSL を使用する場合は true に設定します。connection.user- ClickHouse のユーザー名。connection.password- ClickHouse のパスワード。batch.max.size- 1 回のバッチで送信する行数です。十分に大きな値に設定されていることを確認してください。ClickHouse の推奨事項によると、1000 を最低値として検討すべきです。tasks.max- HTTP Sink コネクターは 1 つ以上のタスクで実行できます。これによりパフォーマンスを向上させることができます。バッチサイズと合わせて、これがパフォーマンスを改善する主な手段となります。key.converter- キーの型に応じて設定します。value.converter- トピック上のデータ型に基づいて設定します。このデータにスキーマは不要です。ここでのフォーマットは、パラメーターhttp.api.urlで指定した FORMAT と一致している必要があります。最も単純なのは JSON と org.apache.kafka.connect.json.JsonConverter コンバーターを使用することです。値を文字列として扱う org.apache.kafka.connect.storage.StringConverter コンバーターを使用することも可能ですが、その場合はユーザーが関数を用いた insert 文で値を抽出する必要があります。Avro フォーマットも、io.confluent.connect.avro.AvroConverter コンバーターを使用する場合には ClickHouse でサポートされています。
プロキシの設定方法、リトライ、および高度な SSL 設定を含む設定の完全な一覧はこちらで確認できます。
GitHub サンプルデータ用の設定ファイル例は、Connect がスタンドアロンモードで実行され、Kafka が Confluent Cloud 上でホストされていることを前提に、こちらで確認できます。
2. ClickHouse テーブルを作成する
テーブルが作成されていることを確認してください。標準的な MergeTree を使用した最小構成の GitHub データセットの例を次に示します。
3. Kafka にデータを追加する
Kafka にメッセージを送信します。以下では、kcat を使用して 1 万件のメッセージを送信します。
ターゲットテーブル github に対して簡単な読み取りクエリを実行することで、データが挿入されたことを確認できます。
