ClickHouse Kafka Connect Sink
サポートが必要な場合は、リポジトリで issue を報告するか、ClickHouse public Slack で質問してください。
ClickHouse Kafka Connect Sink は、Kafka トピックから ClickHouse テーブルにデータを取り込む Kafka コネクタです。
ライセンス
Kafka Connector Sink は Apache 2.0 License の下で配布されています。
環境要件
Kafka Connect フレームワーク v2.7 以降が環境にインストールされている必要があります。
バージョン互換性マトリクス
| ClickHouse Kafka Connect version | ClickHouse version | Kafka Connect | Confluent platform |
|---|---|---|---|
| 1.0.0 | > 23.3 | > 2.7 | > 6.1 |
主な機能
- 標準で厳密な exactly-once セマンティクスを提供します。これは、新しい ClickHouse コア機能である KeeperMap(コネクタのステートストアとして使用)によって実現されており、ミニマルなアーキテクチャを可能にします。
- サードパーティ製ステートストアのサポート: 現在はデフォルトでインメモリストアを使用しますが、KeeperMap も利用可能です(Redis は今後追加予定)。
- コア統合コンポーネント: ClickHouse によってビルド・保守・サポートされています。
- ClickHouse Cloud に対して継続的にテストされています。
- 宣言されたスキーマあり/スキーマレスのどちらの場合でもデータ挿入をサポートします。
- ClickHouse のすべてのデータ型をサポートします。
インストール手順
接続情報を取得する
HTTP(S) で ClickHouse に接続するには、次の情報が必要です。
| Parameter(s) | Description |
|---|---|
HOST and PORT | 通常、TLS を使用する場合のポートは 8443、TLS を使用しない場合のポートは 8123 です。 |
DATABASE NAME | 既定で default という名前のデータベースが用意されています。接続したいデータベースの名前を使用してください。 |
USERNAME and PASSWORD | 既定のユーザー名は default です。用途に応じて適切なユーザー名を使用してください。 |
ClickHouse Cloud サービスに関する詳細情報は、ClickHouse Cloud コンソールで確認できます。 サービスを選択し、Connect をクリックします。
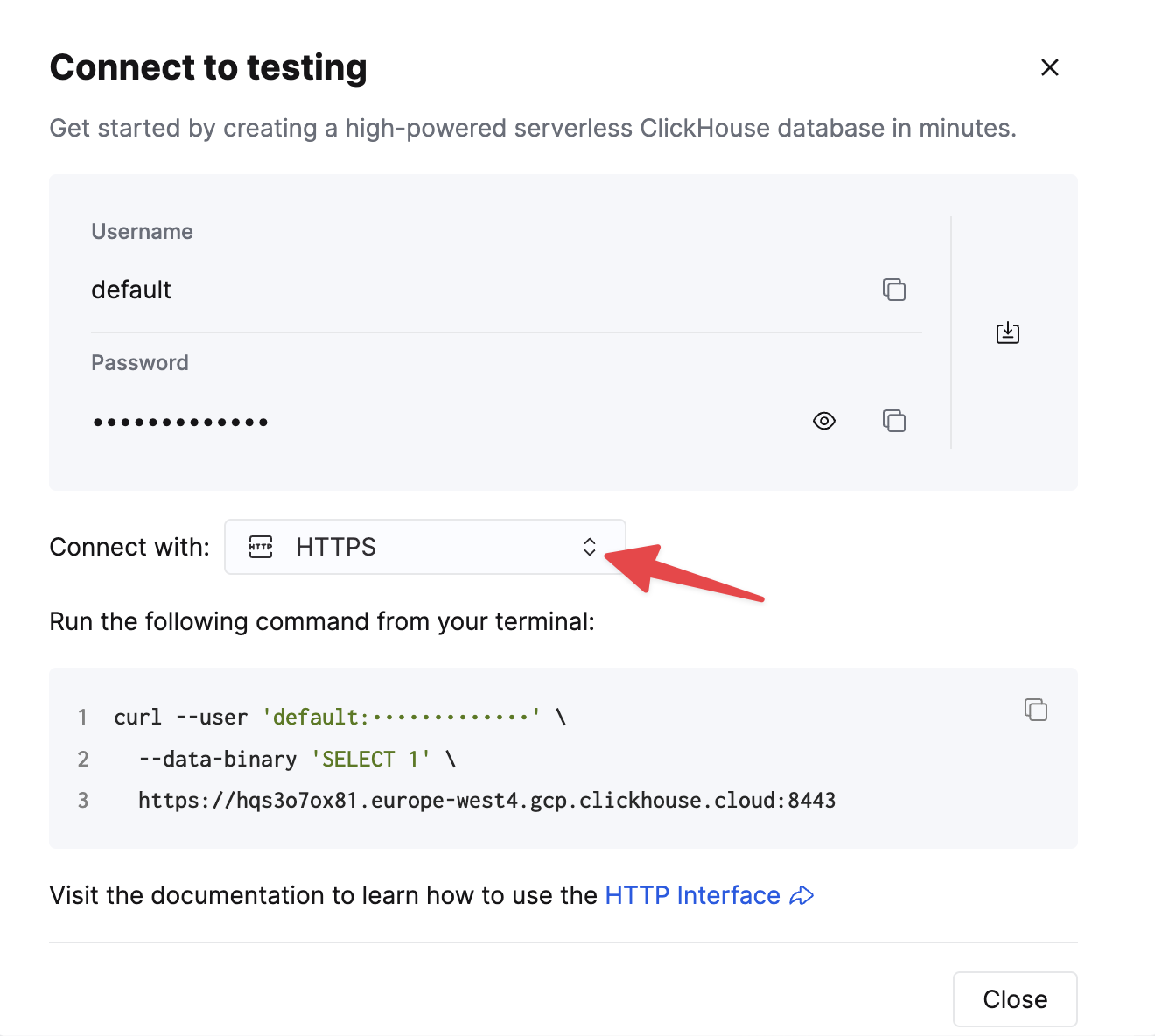
HTTPS を選択します。接続情報は、サンプルの curl コマンド内に表示されます。
セルフマネージドの ClickHouse を使用している場合、接続情報は ClickHouse 管理者によって設定されます。
一般的なインストール手順
このコネクタは、プラグインの実行に必要なすべてのクラスファイルを含む単一の JAR ファイルとして配布されています。
プラグインをインストールするには、次の手順に従ってください。
- ClickHouse Kafka Connect Sink リポジトリの Releases ページから、Connector JAR ファイルを含む zip アーカイブをダウンロードします。
- ZIP ファイルの内容を展開し、任意の場所にコピーします。
- Confluent Platform がプラグインを検出できるように、プラグインディレクトリのパスを Connect プロパティファイル内の plugin.path 設定に追加します。
- 設定で、トピック名、ClickHouse インスタンスのホスト名、およびパスワードを指定します。
- Confluent Platform を再起動します。
- Confluent Platform を使用している場合は、Confluent Control Center UI にログインし、利用可能なコネクタ一覧に ClickHouse Sink が表示されていることを確認します。
設定オプション
ClickHouse Sink を ClickHouse サーバーに接続するには、次の情報を指定する必要があります。
- 接続情報: ホスト名(必須)とポート(任意)
- ユーザー認証情報: パスワード(必須)とユーザー名(任意)
- コネクタクラス:
com.clickhouse.kafka.connect.ClickHouseSinkConnector(必須) - topics または topics.regex: ポーリングする Kafka トピック。トピック名はテーブル名と一致している必要があります(必須)
- キーおよび値コンバーター: トピック上のデータ種別に基づいて設定します。ワーカー設定で既に定義されていない場合は必須です。
設定オプションの完全な一覧表:
| プロパティ名 | 説明 | デフォルト値 |
|---|---|---|
hostname (Required) | サーバーのホスト名または IP アドレス | N/A |
port | ClickHouse のポート。デフォルトは 8443 (クラウドでの HTTPS 用) ですが、HTTP (セルフホスト時のデフォルト) の場合は 8123 を指定する必要がある | 8443 |
ssl | ClickHouse への SSL 接続を有効にするかどうか | true |
jdbcConnectionProperties | ClickHouse に接続する際の接続プロパティ。? で開始し、param=value を & で連結する必要がある | "" |
username | ClickHouse データベースのユーザー名 | default |
password (Required) | ClickHouse データベースのパスワード | N/A |
database | ClickHouse データベース名 | default |
connector.class (Required) | Connector クラス (明示的に設定し、デフォルト値のままにしておくこと) | "com.clickhouse.kafka.connect.ClickHouseSinkConnector" |
tasks.max | Connector Task の最大数 | "1" |
errors.retry.timeout | Kafka Connect の最大リトライ時間 (ミリ秒) 。リトライしない場合は 0。無限にリトライする場合は -1。推奨値は "10000" ms (10 秒) を超える値 タイムアウト | "0" |
exactlyOnce | Exactly Once (正確に 1 回) 処理の有効化フラグ | "false" |
topics (Required) | ポーリングする Kafka トピック。トピック名はテーブル名と一致している必要がある | "" |
key.converter (Required* - See Description) | キーの型に応じて設定します。ここで必須 (キーを渡す場合、かつ worker 設定で定義されていない場合) 。 | "org.apache.kafka.connect.storage.StringConverter" |
value.converter (Required* - See Description) | トピック上のデータの型に基づいて設定します。サポートされる形式: JSON、String、Avro、Protobuf。worker 設定で定義されていない場合はここで必須。 | "org.apache.kafka.connect.json.JsonConverter" |
value.converter.schemas.enable | Connector の Value Converter のスキーマサポート | "false" |
errors.tolerance | Connector のエラー許容度。サポート: none、all | "none" |
errors.deadletterqueue.topic.name | 設定されている場合 (かつ errors.tolerance=all のとき) 、失敗したバッチに対して DLQ が使用される (Troubleshooting を参照) | "" |
errors.deadletterqueue.context.headers.enable | DLQ に追加のヘッダーを付与する | "" |
clickhouseSettings | ClickHouse の設定をカンマ区切りで指定 (例: "insert_quorum=2, etc...") | "" |
topic2TableMap | トピック名をテーブル名にマッピングするリストをカンマ区切りで指定 (例: "topic1=table1, topic2=table2, etc...") | "" |
tableRefreshInterval | テーブル定義キャッシュをリフレッシュする間隔 (秒) | 0 |
keeperOnCluster | セルフホスト環境向けに、exactly-once 用 connect_state テーブルに対する ON CLUSTER パラメータを設定可能にする (例: ON CLUSTER clusterNameInConfigFileDefinition。 Distributed DDL Queries を参照) | "" |
bypassRowBinary | スキーマベースのデータ (Avro、Protobuf など) に対して RowBinary および RowBinaryWithDefaults の使用を無効化できる。データに欠損カラムがあり、Nullable/Default が許容できない場合にのみ使用すること | "false" |
dateTimeFormats | DateTime64 スキーマフィールドをパースするための日時フォーマット。; 区切りで指定する (例: someDateField=yyyy-MM-dd HH:mm:ss.SSSSSSSSS;someOtherDateField=yyyy-MM-dd HH:mm:ss) 。 | "" |
tolerateStateMismatch | AFTER_PROCESSING に保存されている現在のオフセットよりも「前」のレコードを connector が破棄することを許可する (例: オフセット 250 が最後に記録されたオフセットである状態で、オフセット 5 が送信された場合など) 。障害後のインジェストを復旧するために使用し、完了したら "false" に戻すこと。 | "false" |
ignorePartitionsWhenBatching | insert 用にメッセージを収集する際にパーティションを無視する (ただし exactlyOnce が false の場合のみ) 。パフォーマンス上の注意: Connector Task が多いほど、1 Task あたりに割り当てられる Kafka パーティションは少なくなり、効果が逓減しうる。 | "false" |
bufferCount (since v1.3.6) | ClickHouse にフラッシュする前にメモリにバッファリングするレコード数。0 は内部バッファリングを無効にする。exactlyOnce=true の場合、バッファリングはサポートされない。 | "0" |
bufferFlushTime (since v1.3.6) | exactlyOnce=false の場合に、フラッシュ前にレコードをバッファリングする最大時間 (ミリ秒) 。0 は時間ベースのフラッシュを無効にする。デフォルト値は 0。時間ベースの閾値にのみ必要。bufferCount > 0 の場合にのみ有効。 | "0" |
reportInsertedOffsets (v1.3.6 以降) | exactlyOnce=false の場合、preCommit から currentOffsets ではなく、正常に insert されたオフセットのみを返すよう有効にする。ignorePartitionsWhenBatching=true の場合は適用されず、その場合も currentOffsets が返される。 | "false" |
対象テーブル
ClickHouse Connect Sink は Kafka のトピックからメッセージを読み取り、適切なテーブルに書き込みます。ClickHouse Connect Sink が書き込むのは既存のテーブルのみです。データの挿入を開始する前に、対象テーブルが ClickHouse 上に適切なスキーマで作成済みであることを必ず確認してください。
各トピックごとに、ClickHouse 上に専用の対象テーブルが必要です。対象テーブル名は、元のトピック名と一致している必要があります。
前処理
ClickHouse Kafka Connect Sink に送信される前に送信するメッセージを変換する必要がある場合は、Kafka Connect Transformations を使用してください。
サポートされるデータ型
スキーマを宣言している場合:
| Kafka Connect Type | ClickHouse Type | Supported | Primitive |
|---|---|---|---|
| STRING | String | ✅ | Yes |
| STRING | JSON. See below (1) | ✅ | Yes |
| INT8 | Int8 | ✅ | Yes |
| INT16 | Int16 | ✅ | Yes |
| INT32 | Int32 | ✅ | Yes |
| INT64 | Int64 | ✅ | Yes |
| FLOAT32 | Float32 | ✅ | Yes |
| FLOAT64 | Float64 | ✅ | Yes |
| BOOLEAN | Boolean | ✅ | Yes |
| ARRAY | Array(T) | ✅ | No |
| MAP | Map(Primitive, T) | ✅ | No |
| STRUCT | Variant(T1, T2, ...) | ✅ | No |
| STRUCT | Tuple(a T1, b T2, ...) | ✅ | No |
| STRUCT | Nested(a T1, b T2, ...) | ✅ | No |
| STRUCT | JSON. See below (1), (2) | ✅ | No |
| BYTES | String | ✅ | No |
| org.apache.kafka.connect.data.Time | Int64 / DateTime64 | ✅ | No |
| org.apache.kafka.connect.data.Timestamp | Int32 / Date32 | ✅ | No |
| org.apache.kafka.connect.data.Decimal | Decimal | ✅ | No |
-
(1) - JSON がサポートされるのは、ClickHouse の設定で
input_format_binary_read_json_as_string=1が有効になっている場合のみです。これは RowBinary フォーマットファミリーでのみ動作し、この設定は挿入リクエスト内のすべてのカラムに影響するため、すべて文字列型である必要があります。この場合、コネクタは STRUCT を JSON 文字列に変換します。 -
(2) - 構造体に
oneofのような ユニオン が含まれている場合、コンバータはフィールド名にプレフィックス/サフィックスを追加しないように設定する必要があります。ProtobufConverterにはgenerate.index.for.unions=falseという 設定 があります。
スキーマを宣言していない場合:
レコードは JSON に変換され、JSONEachRow フォーマットの値として ClickHouse に送信されます。
設定レシピ
すぐに使い始めるための、一般的な設定レシピをいくつか示します。
基本構成
使い始めるための最も基本的な構成です。Kafka Connect を分散モードで実行しており、localhost:8443 で SSL が有効な ClickHouse サーバーが稼働していて、データはスキーマレスな JSON であることを前提としています。
上記のコネクタ設定では、connector.client.config.override.policy=All を使用して、worker の設定でクライアントの override を有効にする必要があります。詳細については、Kafka Connect のドキュメントを参照してください。
複数トピックを使用した基本構成
このコネクタは複数のトピックからデータを取り込めます。
DLQ を使用した基本構成
異なるデータ形式での利用
Avro スキーマのサポート
Avro 型マッピング
以下の型マッピングは、Kafka Connect における公式の Avro シリアライザー/デシリアライザー実装である io.confluent.connect.avro.AvroConverter で定義されています。変換ロジックの詳細については、Kafka Connect の ドキュメント を参照してください。
✅: サポート
❌: 非サポート
️⚠️: 一部サポート
| Avro Type | Kafka Connect Type | Supported | Notes |
|---|---|---|---|
| null | N/A | ❌ | 単独の型としてはサポートされませんが、ユニオン では使用できます |
| boolean | BOOLEAN | ✅ | |
| int | INT8/INT16/INT32 | ✅ | デフォルトは INT32 です。スキーマ にプロパティ connect.type=int8 がある場合は INT8 に解決されます (connect.type=int16 の場合も同様に INT16) |
| long | INT64 | ✅ | |
| float | FLOAT32 | ✅ | |
| double | FLOAT64 | ✅ | |
| bytes | BYTES | ✅ | |
| string | STRING | ✅ | |
| record | STRUCT | ✅ | |
| enum | STRING | ✅ | |
| array | ARRAY/MAP | ✅ | デフォルトは ARRAY です。フィールドが元々 AvroData.fromConnectSchema を介して構築されていた場合は MAP に解決されます (source) |
| map | MAP | ✅ | |
| union | STRUCT/<T> | ⚠️ | デフォルトは STRUCT です。flatten.singleton.unions=true の場合、ユニオン 定義内の singleton 型 T に解決されます (docs を参照) |
| fixed | BYTES | ⚠️ | Fixed decimal 論理型はサポートされていません (以下を参照) |
Kafka Connect の型と ClickHouse の型の対応については、サポートされるデータ型を参照してください。
サポート対象外の Avro スキーマ
このコネクタでは、次の Avro スキーマ はサポート対象外です:
- fixed
decimal論理型
- Nullable なユニオン
- レコードのユニオン
Protobuf スキーマのサポート
注意:クラスが見つからないといった問題が発生する場合は、一部の環境には protobuf コンバーターが同梱されていないため、依存関係をバンドルした別の jar リリースを使用する必要がある場合があります。
Protobuf 型マッピング
以下の型マッピングは、Kafka Connect における公式の Protobuf シリアライザー/デシリアライザー実装である io.confluent.connect.protobuf.ProtobufConverter で定義されています。変換ロジックの詳細については、Kafka Connect のドキュメントを参照してください。
✅: サポート
❌: サポート対象外
️⚠️: 一部サポート
| Protobuf Type | Kafka Connect Type | Supported | Notes |
|---|---|---|---|
| double | FLOAT64 | ✅ | |
| float | FLOAT32 | ✅ | |
| int32 | INT8/INT16/INT32 | ✅ | デフォルトは INT32 です。スキーマ に connect.type=int8 オプションがある場合は INT8 になり (connect.type=int16 の場合は同様に INT16) 、それに応じて解釈されます。 |
| sint32 | INT8/INT16/INT32 | ✅ | デフォルトは INT32 です。スキーマ に connect.type=int8 オプションがある場合は INT8 になり (connect.type=int16 の場合は同様に INT16) 、それに応じて解釈されます。 |
| sfixed32 | INT8/INT16/INT32 | ✅ | デフォルトは INT32 です。スキーマ に connect.type=int8 オプションがある場合は INT8 になり (connect.type=int16 の場合は同様に INT16) 、それに応じて解釈されます。 |
| uint32 | INT64 | ✅ | |
| fixed32 | INT64 | ✅ | |
| int64 | INT64 | ✅ | |
| uint64 | INT64 | ✅ | |
| sint64 | INT64 | ✅ | |
| fixed64 | INT64 | ✅ | |
| sfixed64 | INT64 | ✅ | |
| bool | BOOLEAN | ✅ | |
| string | STRING | ✅ | |
| bytes | BYTES | ✅ | |
| enum | INT32/STRING | ✅ | デフォルトは STRING です。int.for.enums=true の場合は INT32 になります (schema registry docsを参照) 。 |
| message | STRUCT | ⚠️ | 後述のサポート対象外の スキーマ セクションを参照してください。 |
| repeated T (where T is not a map entry) | ARRAY | ✅ | |
map<K, V> | MAP | ✅ | |
| oneof | STRUCT | ⚠️ | oneof を ClickHouse スキーマ に変換する方法については、後述のセクションを参照してください。 |
| google.protobuf.DoubleValue | FLOAT64 | ✅ | |
| google.protobuf.FloatValue | FLOAT32 | ✅ | |
| google.protobuf.Int64Value | INT64 | ✅ | |
| google.protobuf.UInt64Value | INT64 | ✅ | |
| google.protobuf.UInt32Value | INT64 | ✅ | |
| google.protobuf.Int32Value | INT32 | ✅ | |
| google.protobuf.BoolValue | BOOLEAN | ✅ | |
| google.protobuf.StringValue | STRING | ✅ | |
| google.protobuf.BytesValue | BYTES | ✅ | |
| google.protobuf.Timestamp | org.apache.kafka.connect.data.Timestamp | ✅ | |
| google.type.Date | org.apache.kafka.connect.data.Date | ✅ | |
| google.type.TimeOfDay | org.apache.kafka.connect.data.Time | ✅ |
Kafka Connect 型と ClickHouse 型の対応については、サポートされるデータ型を参照してください。
oneof フィールドを ClickHouse のカラムに変換する際の注意
このコネクタは、Protobuf のユニオン (oneof) を ClickHouse の Variant 型に変換することをサポートしていません。代わりに、ClickHouse テーブルの スキーマ では、oneof フィールドを個別の Nullable フィールドとして定義してください。
例:
次の ClickHouse のテーブル定義に変換されます:
サポート対象外の Protobuf スキーマ
以下の Protobuf スキーマ は、このコネクタのサポート対象外です:
- 複数メッセージのユニオン (CH バージョン 26.1 より前)
CH バージョン 26.1 以降では、allow_experimental_nullable_tuple_type=1 を設定すると、この スキーマ がサポートされます (このドキュメントページを参照) 。
JSON スキーマのサポート
文字列のサポート
このコネクタは、ClickHouse のさまざまなフォーマット(JSON、CSV、TSV)で String コンバーターをサポートします。
内部バッファリング
内部バッファリングを使用すると、sink タスクは複数回の poll() 呼び出しで取得したレコードを蓄積し、それらをより大きなバッチとして ClickHouse にフラッシュできます。これにより、各 poll がパーティションごとに多数の小さなバッチを生成するワークロードでは、スループットが向上する場合があります。
主な動作:
bufferCountは、フラッシュ前にバッファリングするレコード数を制御します。bufferFlushTimeは、バッファリングされたレコードをフラッシュする前の最大待機時間 (ミリ秒) を設定します。bufferFlushTimeは、bufferCount > 0の場合にのみ有効です。bufferCount=0とbufferFlushTime=0の場合、バッファリングは無効のままです (デフォルトの動作) 。exactlyOnce=trueの場合、バッファリングはサポートされません。
バッファリングが exactly-once モードと互換性がない理由:
バッファリングによってバッチ境界が変わるため、ClickHouse のブロック重複排除とコネクタのオフセット状態マシンが機能しなくなります。
これを解決するには、コネクタの設定で exactlyOnce=false を指定して exactly-once モードを無効にするか、bufferCount=0 を指定してバッファリングを無効にします。
例:
ログ記録
ログ記録は Kafka Connect Platform によって自動的に行われます。 ログの出力先や形式は、Kafka Connect の設定ファイルで設定できます。
Confluent Platform を使用している場合は、CLI コマンドを実行することでログを確認できます。
詳細については、公式のチュートリアルを参照してください。
モニタリング
ClickHouse Kafka Connect は、Java Management Extensions (JMX) を通じて実行時メトリクスを公開します。JMX は Kafka Connector でデフォルトで有効になっています。
ClickHouse 固有のメトリクス
コネクタは、次の MBean 名でカスタムメトリクスを公開します。
| Metric Name | Type | Description |
|---|---|---|
receivedRecords | long | 受信したレコードの総数。 |
recordProcessingTime | long | レコードをグループ化し、統一された構造に変換するのに要した合計時間(ナノ秒)。 |
taskProcessingTime | long | データを処理して ClickHouse に挿入するのに要した合計時間(ナノ秒)。 |
Kafka Producer/Consumer のメトリクス
このコネクタは、データフロー、スループット、およびパフォーマンスを把握するための標準的な Kafka Producer/Consumer メトリクスを公開します。
トピックレベルのメトリクス:
records-sent-total: トピックに送信されたレコードの総数bytes-sent-total: トピックに送信されたバイト数の総量record-send-rate: 1 秒あたりに送信されたレコードの平均レートbyte-rate: 1 秒あたりに送信されたバイト数の平均レートcompression-rate: 達成された圧縮率
パーティションレベルのメトリクス:
records-sent-total: パーティションに送信されたレコードの総数bytes-sent-total: パーティションに送信されたバイト数の総量records-lag: パーティションの現在のラグrecords-lead: パーティションの現在のリードreplica-fetch-lag: レプリカに関するラグ情報
ノードレベルの接続メトリクス:
connection-creation-total: Kafka ノードに対して作成された接続の総数connection-close-total: クローズされた接続の総数request-total: ノードに送信されたリクエストの総数response-total: ノードから受信したレスポンスの総数request-rate: 1 秒あたりの平均リクエストレートresponse-rate: 1 秒あたりの平均レスポンスレート
これらのメトリクスは次の監視に役立ちます:
- スループット: データのインジェストレートを追跡
- ラグ: ボトルネックと処理遅延の特定
- 圧縮: データ圧縮効率の測定
- 接続状態: ネットワーク接続性と安定性の監視
Kafka Connect フレームワークのメトリクス
コネクタは Kafka Connect フレームワークと統合されており、タスクのライフサイクルおよびエラー追跡のためのメトリクスを公開します。
タスクステータスメトリクス:
task-count: コネクタ内のタスクの総数running-task-count: 現在実行中のタスク数paused-task-count: 現在一時停止中のタスク数failed-task-count: 失敗したタスクの数destroyed-task-count: 破棄されたタスクの数unassigned-task-count: 未割り当てタスクの数
タスクステータスの値には次が含まれます: running, paused, failed, destroyed, unassigned
エラーメトリクス:
deadletterqueue-produce-failures: 失敗したデッドレターキュー (DLQ) への書き込みの数deadletterqueue-produce-requests: デッドレターキューへの書き込み試行の総数last-error-timestamp: 直近のエラーのタイムスタンプrecords-skip-total: エラーによりスキップされたレコードの総数records-retry-total: リトライされたレコードの総数errors-total: 発生したエラーの総数
パフォーマンスメトリクス:
offset-commit-failures: 失敗したオフセットコミットの数offset-commit-avg-time-ms: オフセットコミットに要する平均時間offset-commit-max-time-ms: オフセットコミットに要する最大時間put-batch-avg-time-ms: バッチ処理に要する平均時間put-batch-max-time-ms: バッチ処理に要する最大時間source-record-poll-total: 取得されたレコードの総数
監視のベストプラクティス
- コンシューマラグを監視する: パーティションごとに
records-lagを追跡して処理ボトルネックを特定します - エラーレートを追跡する:
errors-totalとrecords-skip-totalを監視してデータ品質の問題を検出します - タスクの健全性を確認する: タスクステータスメトリクスを監視してタスクが正しく実行されていることを確認します
- スループットを計測する:
records-send-rateとbyte-rateを使用してインジェスト性能を追跡します - 接続状態を監視する: ノードレベルの接続メトリクスを確認してネットワークの問題を検出します
- 圧縮効率を追跡する:
compression-rateを使用してデータ転送を最適化します
JMX メトリクスの詳細な定義および Prometheus との統合については、jmx-export-connector.yml 設定ファイルを参照してください。
制限事項
- 削除はサポートされていません。
- バッチサイズは Kafka Consumer のプロパティから継承されます。
- exactly-once 処理のために KeeperMap を使用していて、オフセットが変更または巻き戻された場合、その特定のトピックの KeeperMap の内容を削除する必要があります(詳細については、以下のトラブルシューティングガイドを参照してください)。
パフォーマンスチューニングとスループット最適化
このセクションでは、ClickHouse Kafka Connect Sink のパフォーマンスチューニング戦略について説明します。高スループットなユースケースを扱う場合や、リソース使用状況を最適化してラグを最小化する必要がある場合、パフォーマンスチューニングは重要です。
いつパフォーマンスチューニングが必要になるか
パフォーマンスチューニングが一般的に必要となるのは、次のようなシナリオです:
- 高スループットワークロード: Kafka トピックから毎秒数百万件のイベントを処理する場合
- コンシューマラグ: コネクタがデータ生成レートに追いつかず、ラグが増加している場合
- リソース制約: CPU、メモリ、またはネットワーク使用量を最適化する必要がある場合
- 複数トピック: 複数の高ボリュームトピックを同時に消費している場合
- メッセージサイズが小さい場合: 多数の小さなメッセージを扱い、サーバーサイドでのバッチ処理の恩恵を受けられる場合
次のような場合には、パフォーマンスチューニングは通常必要ありません:
- 低〜中程度のボリューム(< 10,000 メッセージ/秒)を処理している場合
- コンシューマラグが安定しており、ユースケース上許容可能な場合
- デフォルトのコネクタ設定で既にスループット要件を満たしている場合
- ClickHouse クラスターが受信負荷を容易に処理できている場合
データフローの理解
チューニングを行う前に、コネクタ内でデータがどのように流れるかを理解しておくことが重要です。
- Kafka Connect フレームワーク がバックグラウンドで Kafka のトピックからメッセージを取得する
- コネクタがポーリング してフレームワークの内部バッファからメッセージを取得する
- コネクタがバッチ化 し、ポーリングサイズに基づいてメッセージをまとめる
- ClickHouse が受信 し、バッチ化された
INSERTを HTTP/S 経由で受け取る - ClickHouse が処理 し、
INSERTを同期または非同期で処理する
これら各段階でパフォーマンスを最適化できます。
Kafka Connect のバッチサイズ調整
最初の最適化ポイントは、Kafka からコネクタが 1 バッチあたりに受け取るデータ量を制御することです。
フェッチ設定
Kafka Connect(フレームワーク)は、コネクタとは独立してバックグラウンドで Kafka のトピックからメッセージを取得します。
fetch.min.bytes: フレームワークが値をコネクタに渡す前に必要となる最小データ量(デフォルト: 1 バイト)fetch.max.bytes: 1 回のリクエストで取得する最大データ量(デフォルト: 52428800 / 50 MB)fetch.max.wait.ms:fetch.min.bytesに満たない場合にデータを返すまで待機する最大時間(デフォルト: 500 ms)
Confluent Cloud では、これらの設定を変更するには Confluent Cloud 経由でサポートケースを起票する必要があります。
ポーリング設定
コネクタはフレームワークの内部バッファからメッセージをポーリングします。
max.poll.records: 1 回のポーリングで返される最大レコード数(デフォルト: 500)max.partition.fetch.bytes: パーティションごとの最大データ量(デフォルト: 1048576 / 1 MB)
Confluent Cloud では、これらの設定を調整するには Confluent Cloud を通じてサポートケースを起票する必要があります。
高スループット向けの推奨設定
ClickHouse で最適なパフォーマンスを得るには、より大きなバッチを使用することを推奨します:
上記のプロパティを使用するには、connector.client.config.override.policy=All を設定して、ワーカー設定でクライアントのオーバーライドを有効にする必要があります。詳細は Kafka Connect documentation を参照してください。
重要: Kafka Connect のフェッチ設定は圧縮データを基準としますが、ClickHouse が受け取るのは非圧縮データです。圧縮率に応じて、これらの設定のバランスを調整してください。
トレードオフ:
- 大きなバッチ = ClickHouse のインジェスト性能向上、パーツ数の削減、オーバーヘッドの低減
- 大きなバッチ = メモリ使用量の増加、エンドツーエンドレイテンシ増大の可能性
- バッチが大きすぎる = タイムアウトや OutOfMemory エラー、
max.poll.interval.ms超過のリスク
詳細: Confluent documentation | Kafka documentation
Asynchronous inserts
コネクタが比較的小さなバッチを送信する場合や、バッチングの責務を ClickHouse 側に移すことでインジェストをさらに最適化したい場合、非同期インサートは強力な機能です。
非同期インサートを使用するタイミング
次のような場合に、非同期インサートの有効化を検討してください。
- 多数の小さなバッチ: コネクタが 1 バッチあたり 1000 行未満の小さなバッチを高頻度で送信している場合
- 高い同時実行性: 複数のコネクタタスクが同じテーブルに書き込んでいる場合
- 分散デプロイメント: 複数のホストにまたがって多数のコネクタインスタンスを実行している場合
- パーツ作成のオーバーヘッド: 「too many parts」エラーが発生している場合
- 混在ワークロード: リアルタイムのインジェストとクエリワークロードを組み合わせている場合
次のような場合は、非同期インサートを使用 しないでください。
- すでに制御された頻度で、1 バッチあたり 10,000 行を超える大きなバッチを送信している場合
- 即時のデータ可視性が必要な場合(クエリがデータを即座に参照できる必要がある)
wait_for_async_insert=0を用いた厳密な 1 回限りのセマンティクスが要件と競合する場合- クライアント側でのバッチ処理の改善によって要件を満たせるユースケースである場合
非同期インサートの仕組み
非同期インサートを有効にすると、ClickHouse は次のように動作します:
- コネクタからインサートクエリを受信する
- データを (すぐにディスクへ書き込むのではなく) メモリ上のバッファに書き込む
- コネクタに成功を返す (
wait_for_async_insert=0の場合) - 次のいずれかの条件を満たしたときにバッファをディスクへフラッシュする:
- バッファが
async_insert_max_data_sizeに到達した場合 (デフォルト: 100 MB) - 最初のインサートから
async_insert_busy_timeout_msミリ秒が経過した場合 (デフォルト: 1000 ms) - 蓄積されたクエリ数が上限に達した場合 (
async_insert_max_query_number, デフォルト: 100)
- バッファが
これにより作成されるパーツの数が大幅に削減され、全体的なスループットが向上します。
非同期インサートの有効化
clickhouseSettings 構成パラメータに非同期インサート用の設定を追加します。
主要な設定:
async_insert=1: 非同期インサートを有効にするwait_for_async_insert=1(推奨): コネクタは、ClickHouse ストレージへのフラッシュ完了を待ってから ACK を返す。配信を保証する。wait_for_async_insert=0: コネクタはバッファリング直後に即座に ACK を返す。パフォーマンスは向上するが、フラッシュ前にサーバーがクラッシュした場合、データが失われる可能性がある。
非同期 INSERT 動作のチューニング
非同期 INSERT におけるフラッシュ動作を細かく調整できます。
一般的なチューニングパラメータ:
async_insert_max_data_size(デフォルト: 104857600 / 100 MB): フラッシュ前の最大バッファサイズasync_insert_busy_timeout_ms(デフォルト: 1000): フラッシュまでの最大時間 (ミリ秒)async_insert_stale_timeout_ms(デフォルト: 0): 最後の挿入からフラッシュまでの経過時間 (ミリ秒)async_insert_max_query_number(デフォルト: 100): フラッシュ前の最大クエリ数
トレードオフ:
- 利点: パーツ数の削減、マージ性能の向上、CPU オーバーヘッドの低減、高い同時実行時のスループット向上
- 考慮点: データが即座にはクエリ可能にならない、エンドツーエンドのレイテンシがわずかに増加
- リスク:
wait_for_async_insert=0の場合、サーバークラッシュ時のデータ損失の可能性、大きなバッファによるメモリ圧迫の可能性
exactly-once セマンティクスを持つ非同期インサート
exactlyOnce=true と非同期インサートを併用する場合:
重要: データが永続化された後にのみオフセットのコミットが行われるようにするため、exactly-once を使用する場合は必ず wait_for_async_insert=1 を指定してください。
async insert の詳細については、ClickHouse の async inserts ドキュメントを参照してください。
コネクタの並列度
スループットを向上させるには並列度を高めます:
コネクタあたりのタスク数
各タスクは、トピックのパーティションの一部を処理します。タスク数が多いほど並列度は高くなりますが、次のようなトレードオフがあります:
- 実効的なタスク数の上限 = トピックのパーティション数
- 各タスクは ClickHouse への独立した接続を維持する
- タスク数が多いほどオーバーヘッドとリソース競合の可能性が高くなる
推奨: まずは tasks.max をトピックのパーティション数と同じ値に設定し、その後 CPU とスループットのメトリクスに基づいて調整してください。
バッチ処理時にパーティションを無視する
デフォルトでは、コネクタはパーティションごとにメッセージをバッチ処理します。より高いスループットを得るには、パーティションをまたいでバッチ化できます。
警告: exactlyOnce=false の場合にのみ使用してください。この設定は、より大きなバッチを作成することでスループットを向上させられますが、パーティションごとの順序保証が失われます。
Multiple high throughput topics
コネクタが複数のトピックを購読するように設定されており、topic2TableMap を使用してトピックをテーブルにマッピングしていて、挿入処理がボトルネックとなることでコンシューマラグが発生している場合は、代わりにトピックごとに 1 つずつコネクタを作成することを検討してください。
この問題が発生する主な理由は、現時点ではバッチが各テーブルに対して直列に挿入されるためです。
推奨: 高スループットのトピックが複数ある場合は、並列挿入スループットを最大化するために、トピックごとに 1 つのコネクタインスタンスをデプロイしてください。
ClickHouse テーブルエンジンに関する考慮事項
ユースケースに応じて適切な ClickHouse テーブルエンジンを選択します。
MergeTree: ほとんどのユースケースに最適で、クエリと書き込み性能のバランスが良いReplicatedMergeTree: 高可用性に必須だが、レプリケーションによるオーバーヘッドが発生する*MergeTreeと適切なORDER BY: クエリパターンに合わせて最適化できる
検討すべき設定:
コネクタレベルの挿入設定:
接続プーリングとタイムアウト
コネクタは ClickHouse への HTTP 接続を維持します。高遅延のネットワーク環境では、タイムアウト値を調整してください。
socket_timeout(デフォルト: 30000 ms): 読み取り処理の最大待機時間connection_timeout(デフォルト: 10000 ms): 接続確立までの最大待機時間
大きなバッチ処理でタイムアウトエラーが発生する場合は、これらの値を増やしてください。
パフォーマンスの監視とトラブルシューティング
次の主要なメトリクスを監視します:
- Consumer lag: Kafka の監視ツールを使用して、パーティションごとの lag を追跡する
- Connector メトリクス: JMX を介して
receivedRecords,recordProcessingTime,taskProcessingTimeを監視する(Monitoring を参照) - ClickHouse メトリクス:
system.asynchronous_inserts: 非同期インサート用バッファの使用状況を監視system.parts: パーツ数を監視してマージの問題を検出system.merges: 実行中のマージを監視system.events:InsertedRows,InsertedBytes,FailedInsertQueryを追跡
一般的なパフォーマンス問題:
| 症状 | 考えられる原因 | 解決策 |
|---|---|---|
| Consumer lag が大きい | バッチが小さすぎる | max.poll.records を増やし、非同期インサートを有効にする |
| "Too many parts" エラー | 小さなインサートが頻繁に行われている | 非同期インサートを有効にし、バッチサイズを増やす |
| Timeout エラー | バッチサイズが大きい、ネットワークが遅い | バッチサイズを小さくし、socket_timeout を増やし、ネットワークを確認する |
| CPU 使用率が高い | 小さいパーツが多すぎる | 非同期インサートを有効にし、マージ関連の設定値を増やす |
| OutOfMemory エラー | バッチサイズが大きすぎる | max.poll.records, max.partition.fetch.bytes を減らす |
| タスク負荷が不均一 | パーティション分布が不均一 | パーティションを再バランスするか、tasks.max を調整する |
ベストプラクティスのまとめ
- まずはデフォルト設定から始め、実際のパフォーマンスを測定してからチューニングする
- より大きなバッチを優先する:可能であれば、1 回の挿入あたり 10,000~100,000 行を目標にする
- 多数の小さなバッチを送信する場合や高い並行性がある場合は、async insert を使用する
- exactly-once セマンティクスを利用する場合は、常に
wait_for_async_insert=1を使用する - 水平方向にスケールする:パーティション数に達するまで
tasks.maxを増やす - 最大スループットのために、高トラフィックなトピックごとに 1 つのコネクタを使用する
- 継続的にモニタリングする:consumer lag、part 数、マージのアクティビティを追跡する
- 十分にテストする:本番デプロイ前に、現実的な負荷の下で設定変更を必ずテストする
例:高スループット構成
以下は、高スループット向けに最適化した完全な構成例です。
上記のコネクタ設定では、connector.client.config.override.policy=All を指定して、worker の設定で client overrides を有効にする必要があります。詳しくは、Kafka Connect ドキュメントを参照してください。
この構成では:
- 1 回のポーリングあたり最大 10,000 レコードを処理します
- より大きな単位で挿入できるよう、パーティションをまたいでバッチ処理します
- 16 MB のバッファを使用して非同期 INSERT を行います
- 8 個の並列タスクを実行します (パーティション数に合わせます)
- 厳密な順序保証よりもスループットを優先して最適化されています
トラブルシューティング
"State mismatch for topic [someTopic] partition [0]"
これは、KeeperMap に保存されているオフセットが Kafka に保存されているオフセットと異なる場合に発生します。通常は、トピックが削除された場合やオフセットが手動で調整された場合に発生します。 これを修正するには、該当するトピックとパーティションに対して保存されている古い値を削除する必要があります。
この調整は exactly-once セマンティクスに影響を与える可能性があります。
"コネクタはどのエラーをリトライしますか?"
現時点では、一時的でリトライ可能なエラーの特定に注力しており、次のものが含まれます:
ClickHouseException- これは ClickHouse によってスローされる汎用的な例外です。 通常、サーバーが過負荷状態のときにスローされ、次のエラーコードは特に一時的なものと見なされます:- 3 - UNEXPECTED_END_OF_FILE
- 107 - FILE_DOESNT_EXIST
- 159 - TIMEOUT_EXCEEDED
- 164 - READONLY
- 202 - TOO_MANY_SIMULTANEOUS_QUERIES
- 203 - NO_FREE_CONNECTION
- 209 - SOCKET_TIMEOUT
- 210 - NETWORK_ERROR
- 241 - MEMORY_LIMIT_EXCEEDED
- 242 - TABLE_IS_READ_ONLY
- 252 - TOO_MANY_PARTS
- 285 - TOO_FEW_LIVE_REPLICAS
- 319 - UNKNOWN_STATUS_OF_INSERT
- 425 - SYSTEM_ERROR
- 999 - KEEPER_EXCEPTION
SocketTimeoutException- ソケットがタイムアウトしたときにスローされます。UnknownHostException- ホスト名を解決できないときにスローされます。IOException- ネットワークに問題があるときにスローされます。
"すべてのデータが空白/ゼロになる"
おそらく、データ内のフィールドがテーブルのフィールドと一致していません。これは特に CDC(および Debezium フォーマット)を使用している場合によく発生します。 一般的な解決策の 1 つは、コネクタ設定に flatten 変換を追加することです。
これは、入れ子になった JSON データをフラットな JSON に変換します(区切り文字として _ を使用します)。変換後、テーブル内のフィールドは「field1_field2_field3」形式(例: 「before_id」「after_id」など)に従うようになります。
"ClickHouse で Kafka のキーを使いたい"
Kafka のキーはデフォルトでは value フィールドに保存されませんが、KeyToValue 変換を使用して、キーを新しい _key フィールド名として value フィールドに移動できます。
