Amazon Glue を ClickHouse および Spark と連携する
ClickHouse Supported
Amazon Glue は、Amazon Web Services (AWS) が提供する完全マネージド型のサーバーレス データ統合サービスです。分析、機械学習、アプリケーション開発に向けたデータの検出、準備、変換を簡素化できます。
インストール
Glue コードを ClickHouse と統合するには、Glue で公式の Spark コネクタを次のいずれかの方法で利用できます。
- AWS Marketplace から ClickHouse Glue コネクタをインストールする (推奨) 。
- Spark コネクタの jar を Glue ジョブに手動で追加する。
- AWS Marketplace
- 手動インストール
-
コネクタをサブスクライブする
アカウントからコネクタにアクセスするには、AWS Marketplace で ClickHouse AWS Glue Connector をサブスクライブしてください。 -
必要な権限を付与する
Glue ジョブの IAM role に必要な権限があることを確認してください。詳細は、最小権限のガイドを参照してください。 -
コネクタを有効化して接続を作成する
このリンクをクリックすると、主要なフィールドが事前入力された Glue の接続作成ページが開き、そこから直接コネクタを有効化して接続を作成できます。接続に名前を付けて、作成をクリックしてください (この段階では ClickHouse の接続情報を入力する必要はありません) 。 -
Glue ジョブで使用する
Glue ジョブでJob detailsタブを選択し、Advanced propertiesウィンドウを展開します。Connectionsセクションで、先ほど作成した接続を選択してください。コネクタは、必要な JAR をジョブのランタイムに自動的に追加します。
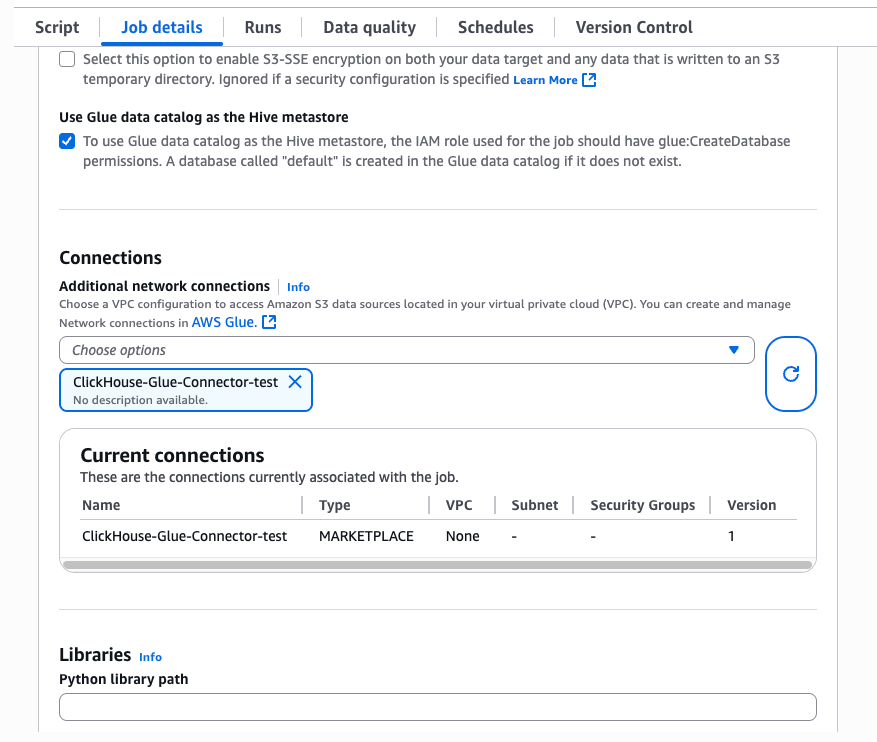
注記
Glue コネクタで使用される JAR は、Spark 3.3、Scala 2、Python 3 向けにビルドされています。Glue ジョブを設定する際は、これらのバージョンを選択してください。
必要な jar を手動で追加するには、次の手順に従ってください。
- 次の jar を S3 バケットにアップロードします:
clickhouse-jdbc-0.6.X-all.jar、clickhouse-spark-runtime-3.X_2.X-0.8.X.jar - Glue ジョブがこのバケットにアクセスできることを確認します。
Job detailsタブで下にスクロールし、Advanced propertiesドロップダウンを展開して、Dependent JARs pathに jar のパスを入力します。
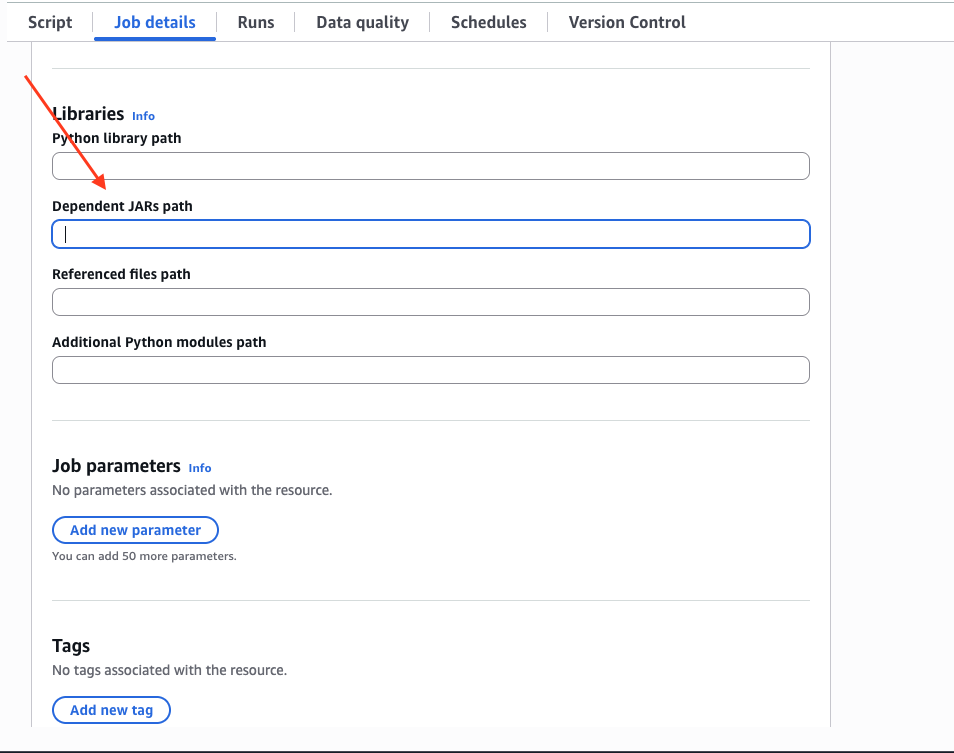
例
- Scala
- Python
詳細については、Spark のドキュメントをご覧ください。
