Object Storage ClickPipes は、Amazon S3、Google Cloud Storage、Azure Blob Storage、DigitalOcean Spaces から ClickHouse Cloud へデータを取り込むための、シンプルかつ堅牢な方法を提供します。一度限りのインジェストと継続的なインジェストの両方を、厳密に 1 回だけ処理されるセマンティクスでサポートします。
最初のオブジェクトストレージ ClickPipe の作成
前提条件
- ClickPipes の概要 に目を通していること。
データソースに移動する
クラウドコンソールで、左側メニューの Data Sources ボタンを選択し、「Set up a ClickPipe」をクリックします。
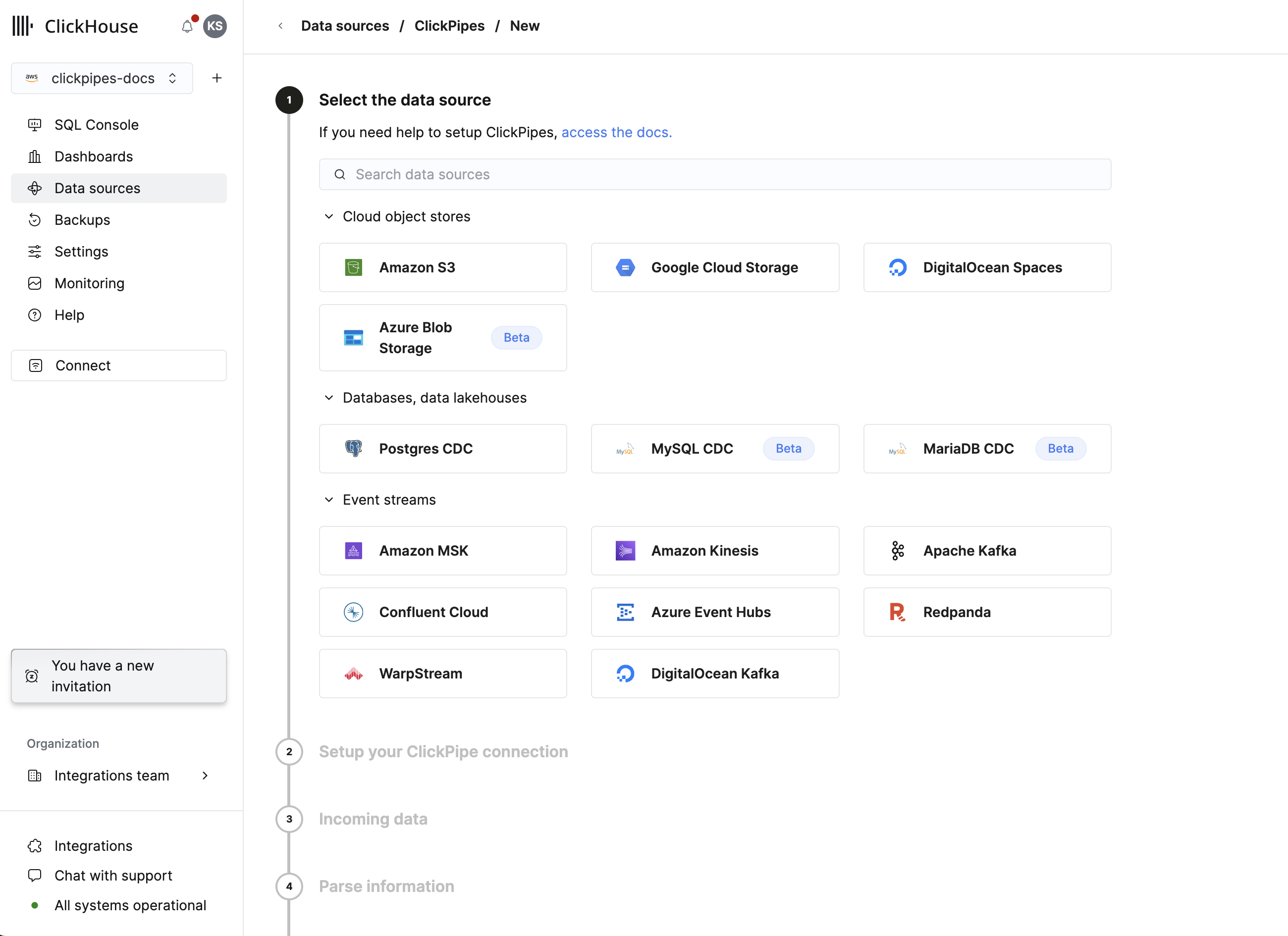
データソースを選択する
データソースを選択します。
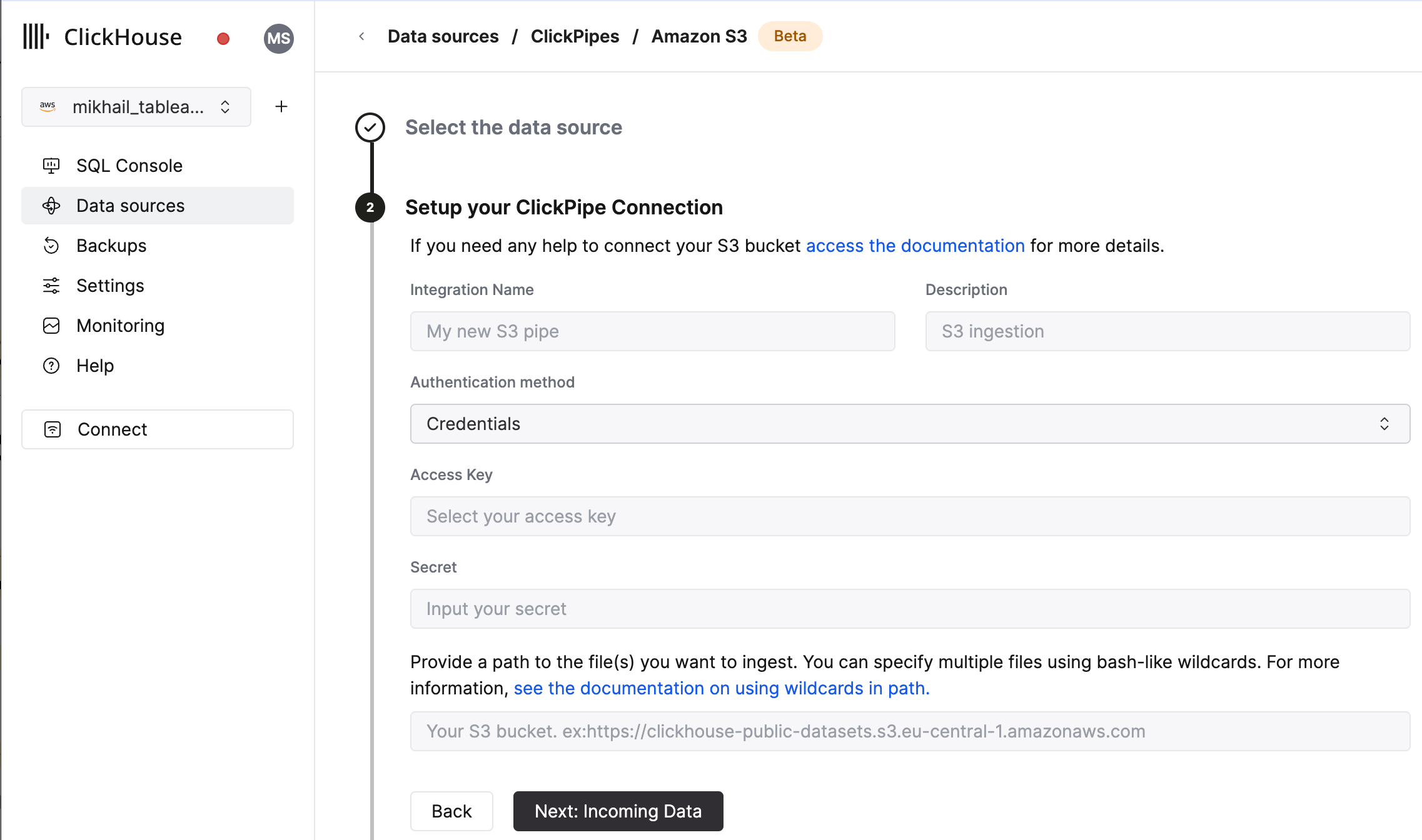
ClickPipe を構成する
ClickPipe に名前、説明(任意)、IAM ロールまたはクレデンシャル、バケット URL を指定してフォームに入力します。 bash 形式のワイルドカードを使用して複数のファイルを指定できます。 詳細については、パスでのワイルドカードの使用に関するドキュメントを参照してください。
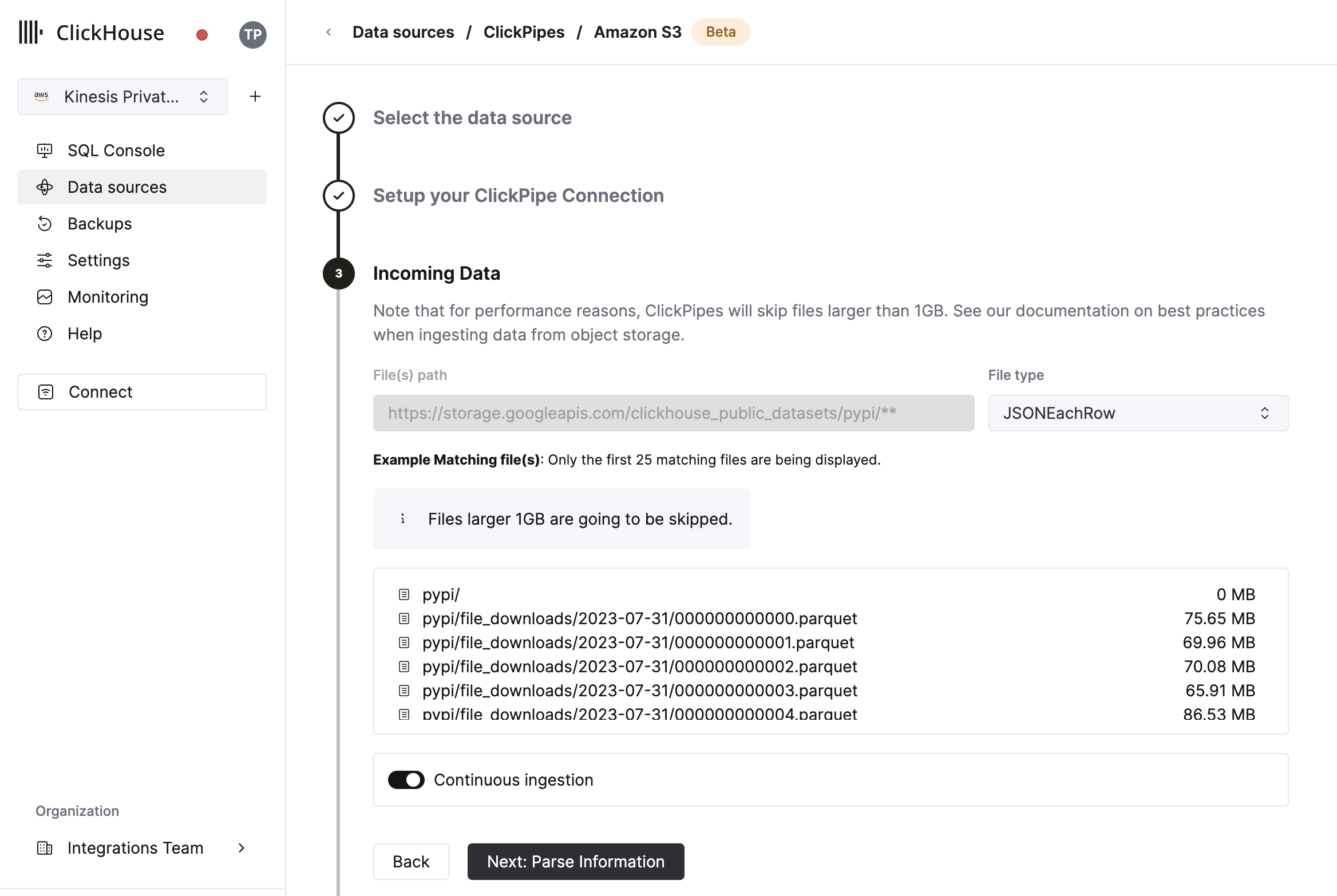
データ形式を選択する
UI には、指定したバケット内のファイル一覧が表示されます。 データ形式(現在は ClickHouse フォーマットの一部に対応)と、継続的なインジェストを有効にするかどうかを選択します。 (詳細は以下を参照)。
テーブル、スキーマ、設定を構成する
次のステップでは、新しい ClickHouse テーブルにデータを取り込むか、既存のテーブルを再利用するかを選択できます。 画面の案内に従って、テーブル名、スキーマ、設定を変更してください。 画面上部のサンプルテーブルで、変更内容をリアルタイムにプレビューできます。
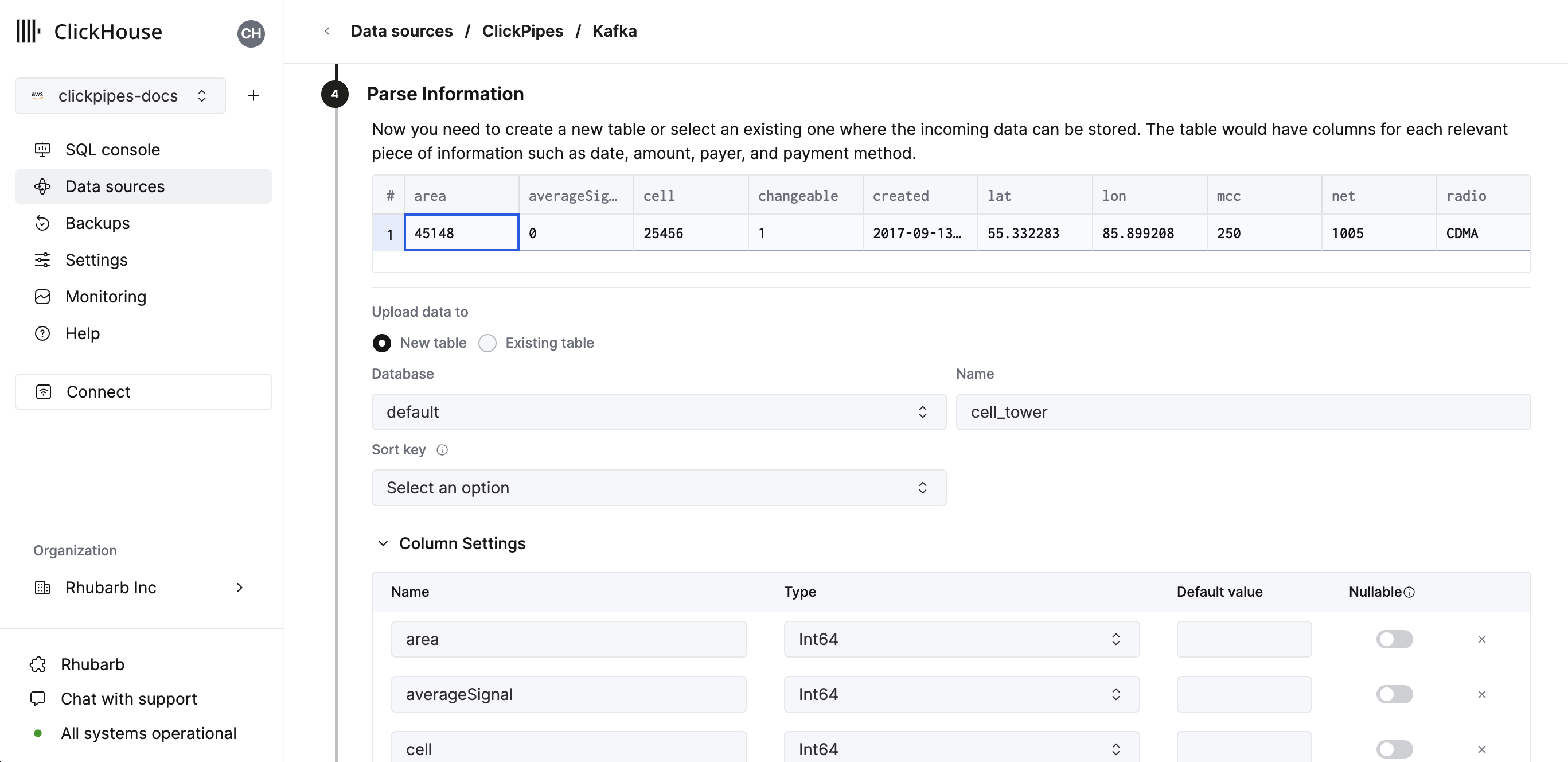
用意されているコントロールを使用して、詳細設定をカスタマイズすることもできます。
また、既存の ClickHouse テーブルにデータを取り込むこともできます。 その場合、UI からソースのフィールドを、選択した宛先テーブルの ClickHouse 側のフィールドにマッピングできます。
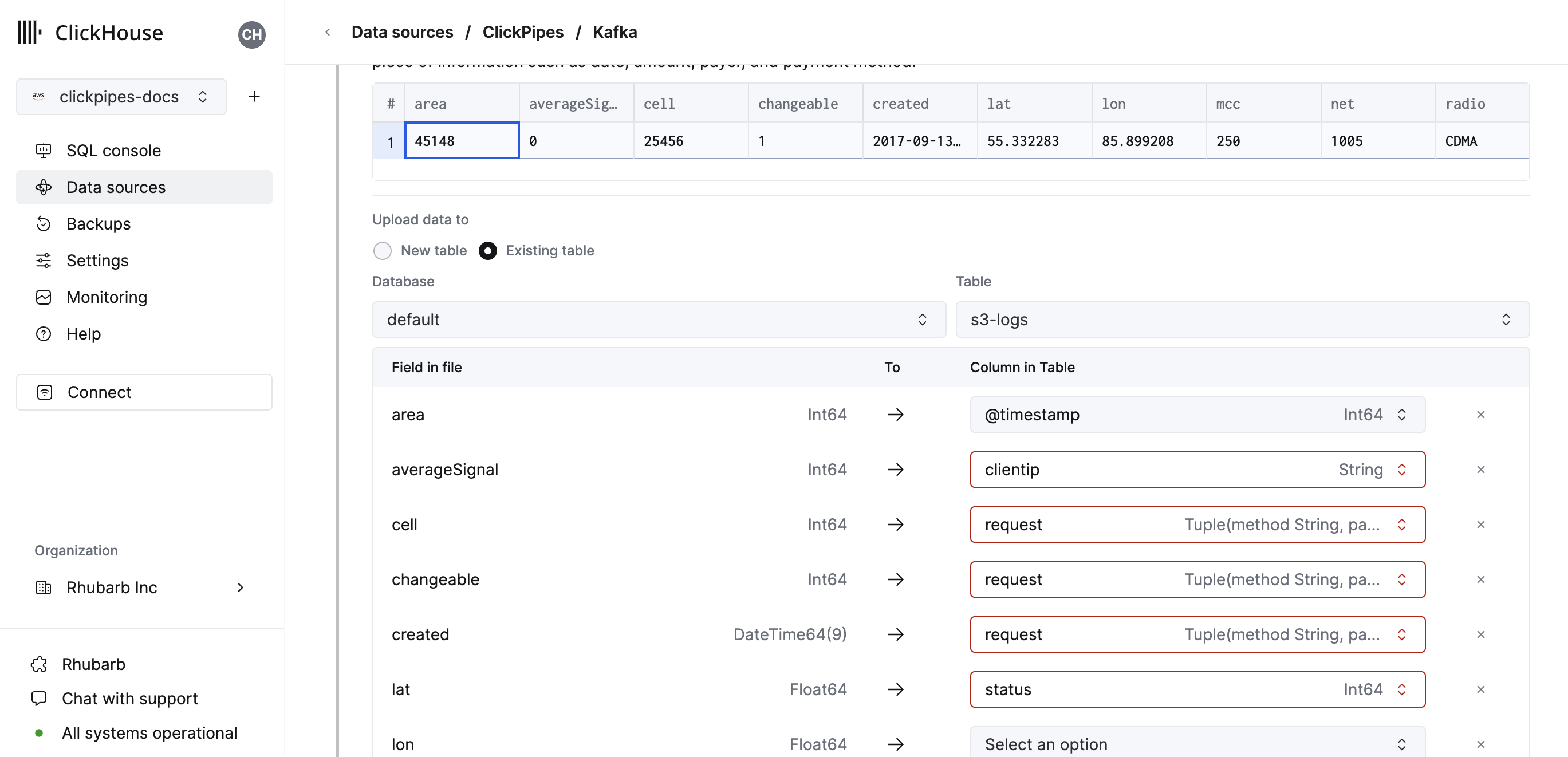
_path や _size などの仮想カラムをフィールドにマッピングすることもできます。
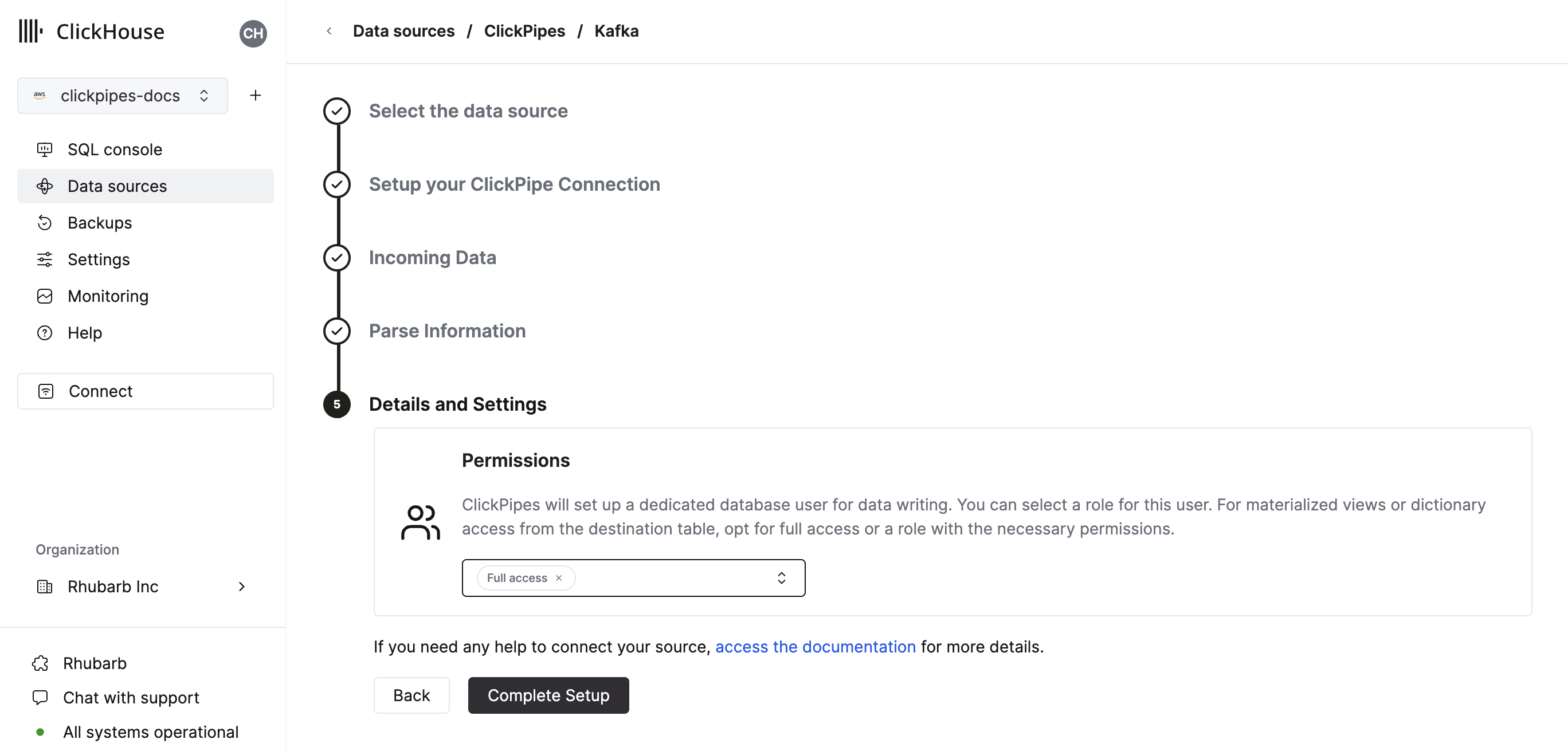
権限を設定する
最後に、ClickPipes の内部ユーザー向けの権限を設定できます。
権限: ClickPipes は、宛先テーブルにデータを書き込むための専用ユーザーを作成します。この内部ユーザーには、カスタムロール、またはあらかじめ定義されたロールのいずれかを選択できます:
Full access: クラスター全体へのフルアクセス権を持ちます。宛先テーブルでマテリアライズドビューまたは Dictionary を使用する場合に必要です。Only destination table: 宛先テーブルに対するINSERT権限のみを持ちます。
セットアップを完了する
"Complete Setup" をクリックすると、システムが ClickPipe を登録し、サマリー テーブルに一覧表示されるようになります。

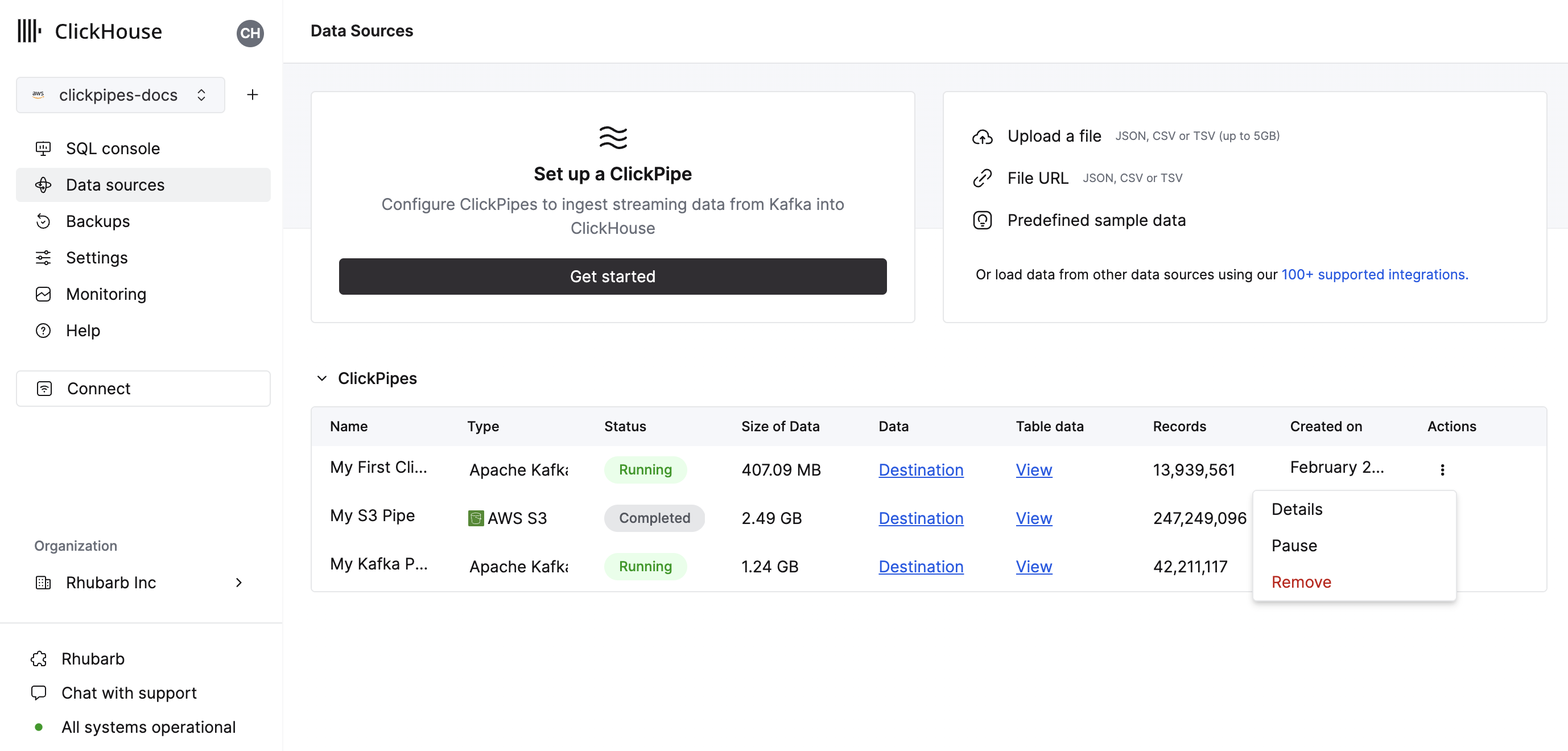
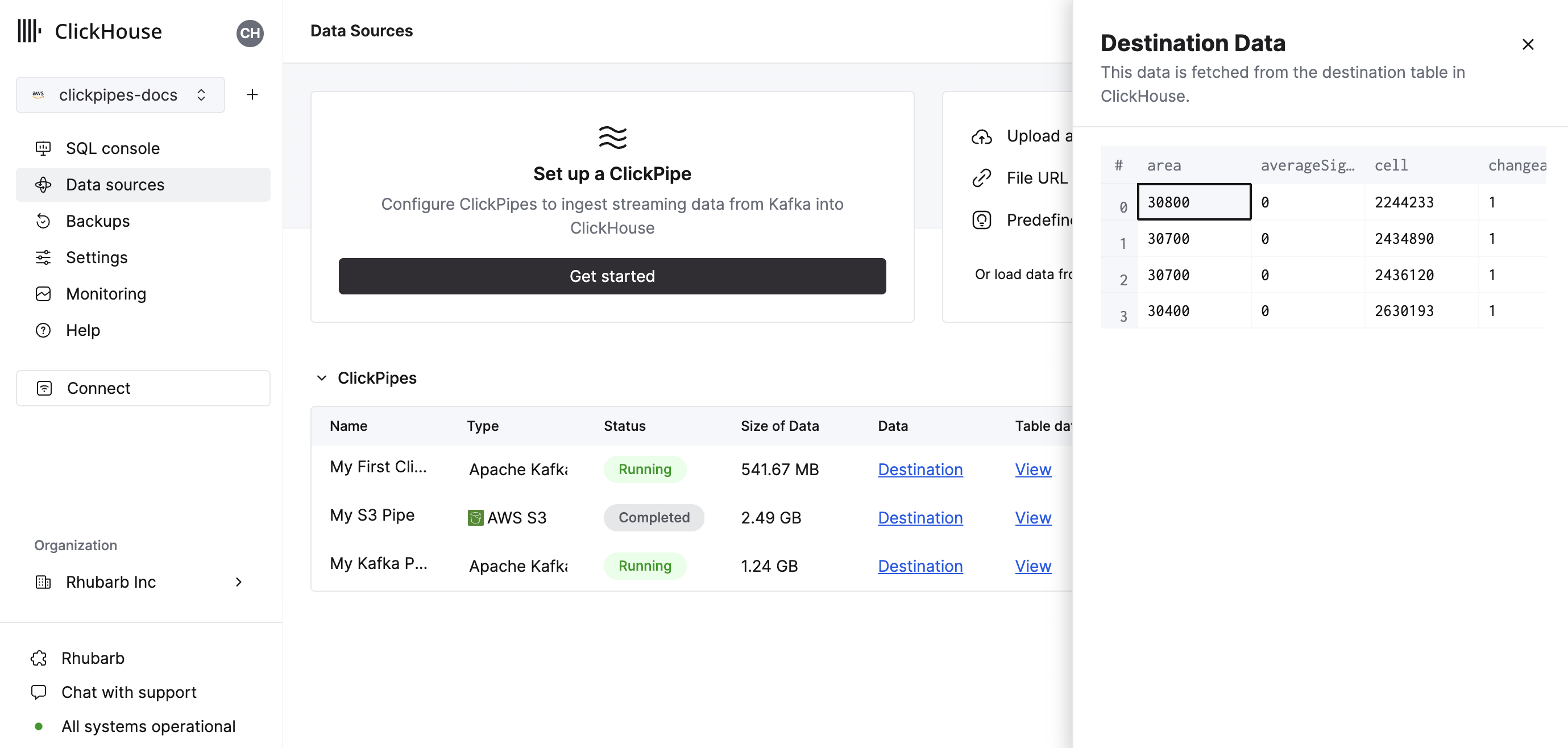
サマリー テーブルでは、ソース側または ClickHouse 上の宛先テーブルからサンプルデータを表示するための操作を行えます。
また、ClickPipe を削除したり、取り込みジョブの概要を表示したりするための操作も行えます。
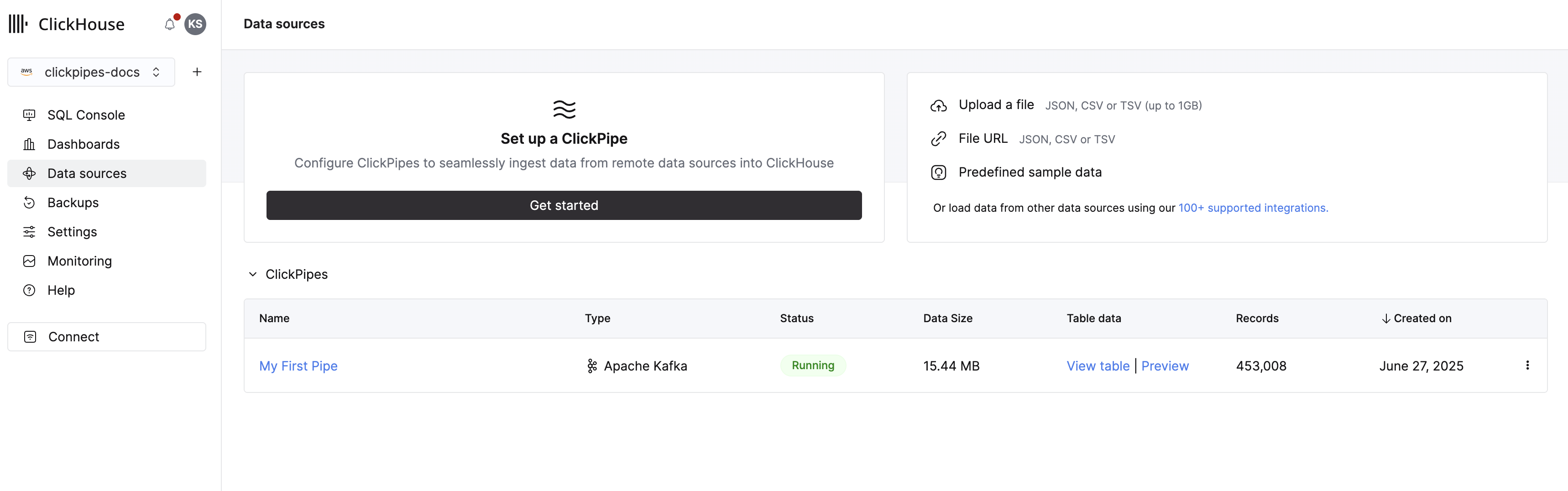
おめでとうございます! 最初の ClickPipe のセットアップが完了しました。 これがストリーミング ClickPipe の場合、リモートデータソースからリアルタイムで継続的にデータを取り込みます。 それ以外の場合は、バッチで取り込み、完了した時点で終了します。
