Amazon Kinesis と ClickHouse Cloud の統合
Kinesis ClickPipes は、ClickPipes UI を使用して手動でデプロイおよび管理できるほか、OpenAPI や Terraform を使用してプログラムからデプロイおよび管理することもできます。
前提条件
ClickPipes の概要に目を通し、IAM 認証情報または IAM ロールを作成済みであること。ClickHouse Cloud と連携可能なロールの設定方法については、Kinesis ロールベースアクセスガイドに従ってください。
最初の ClickPipe を作成する
- ClickHouse Cloud サービスの SQL Console にアクセスします。
- 左側メニューで
Data Sourcesボタンを選択し、"Set up a ClickPipe" をクリックします。
- データソースを選択します。
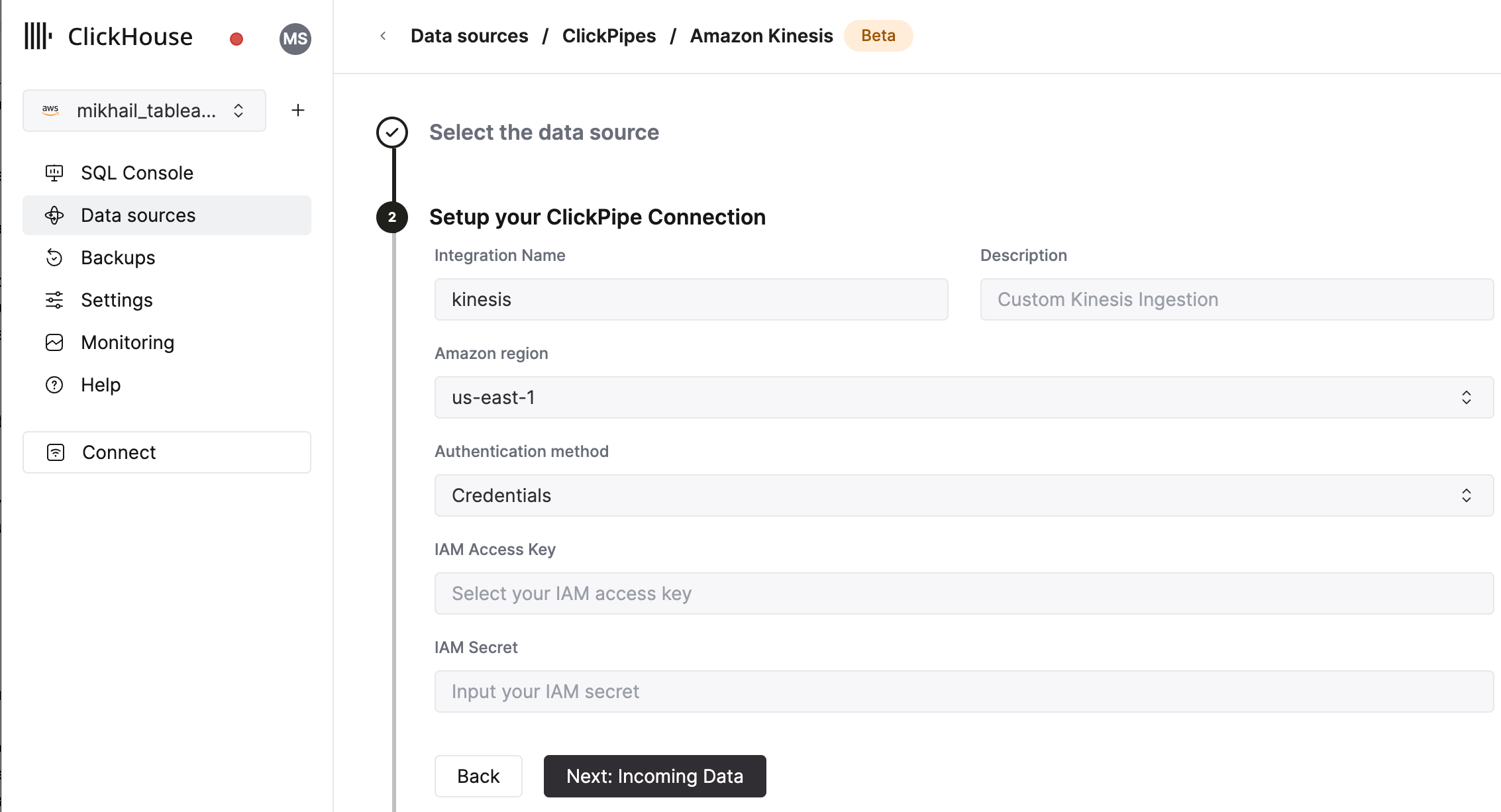
- ClickPipe の名前、説明(任意)、IAM ロールまたは認証情報、その他の接続詳細を入力してフォームを完成させます。
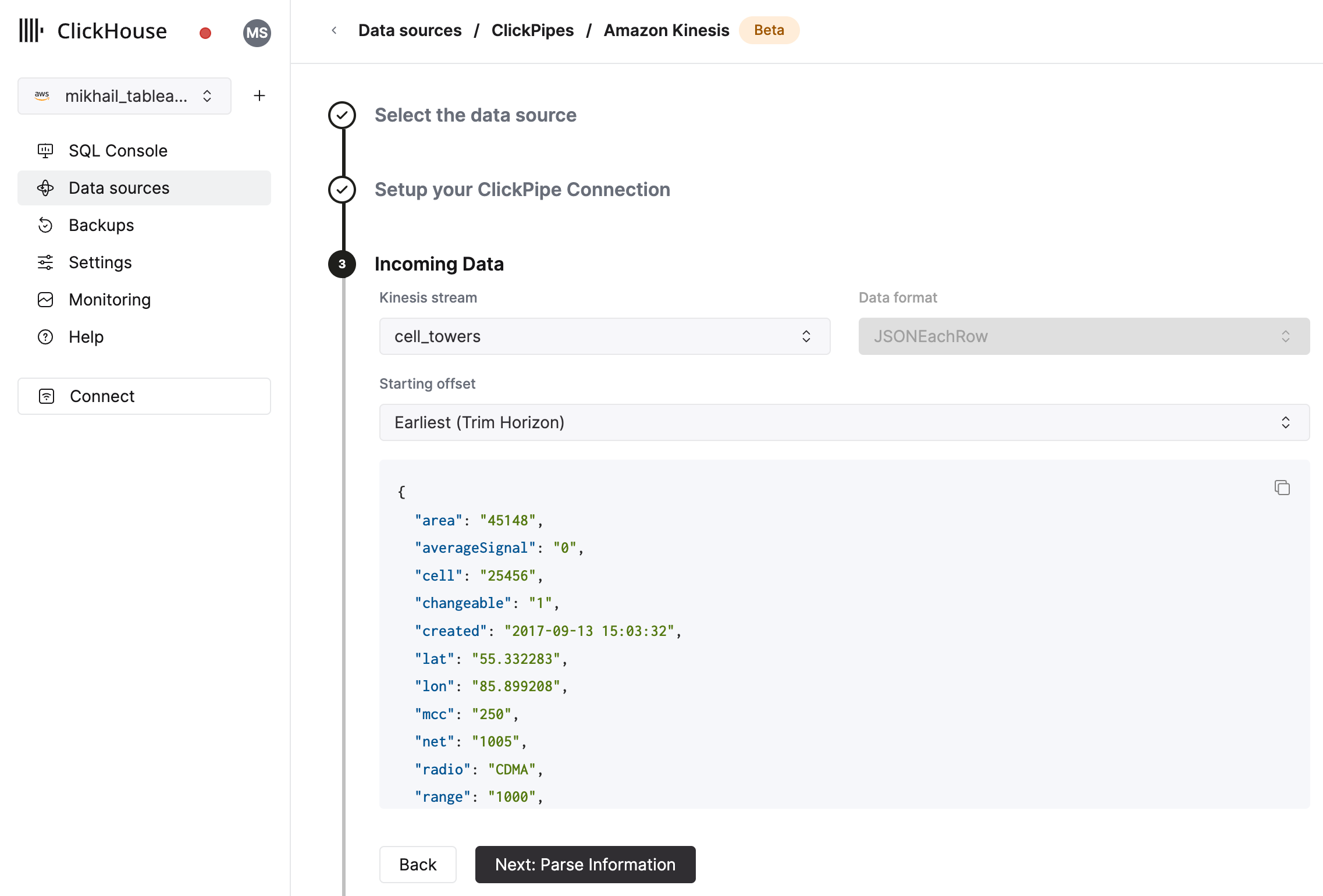
- Kinesis Stream と開始オフセットを選択します。UI には、選択したソース(Kafka トピックなど)からのサンプルドキュメントが表示されます。ClickPipe のパフォーマンスと安定性を向上させるために、Kinesis ストリームで Enhanced Fan-out を有効にすることもできます(Enhanced Fan-out の詳細はこちらを参照してください)。
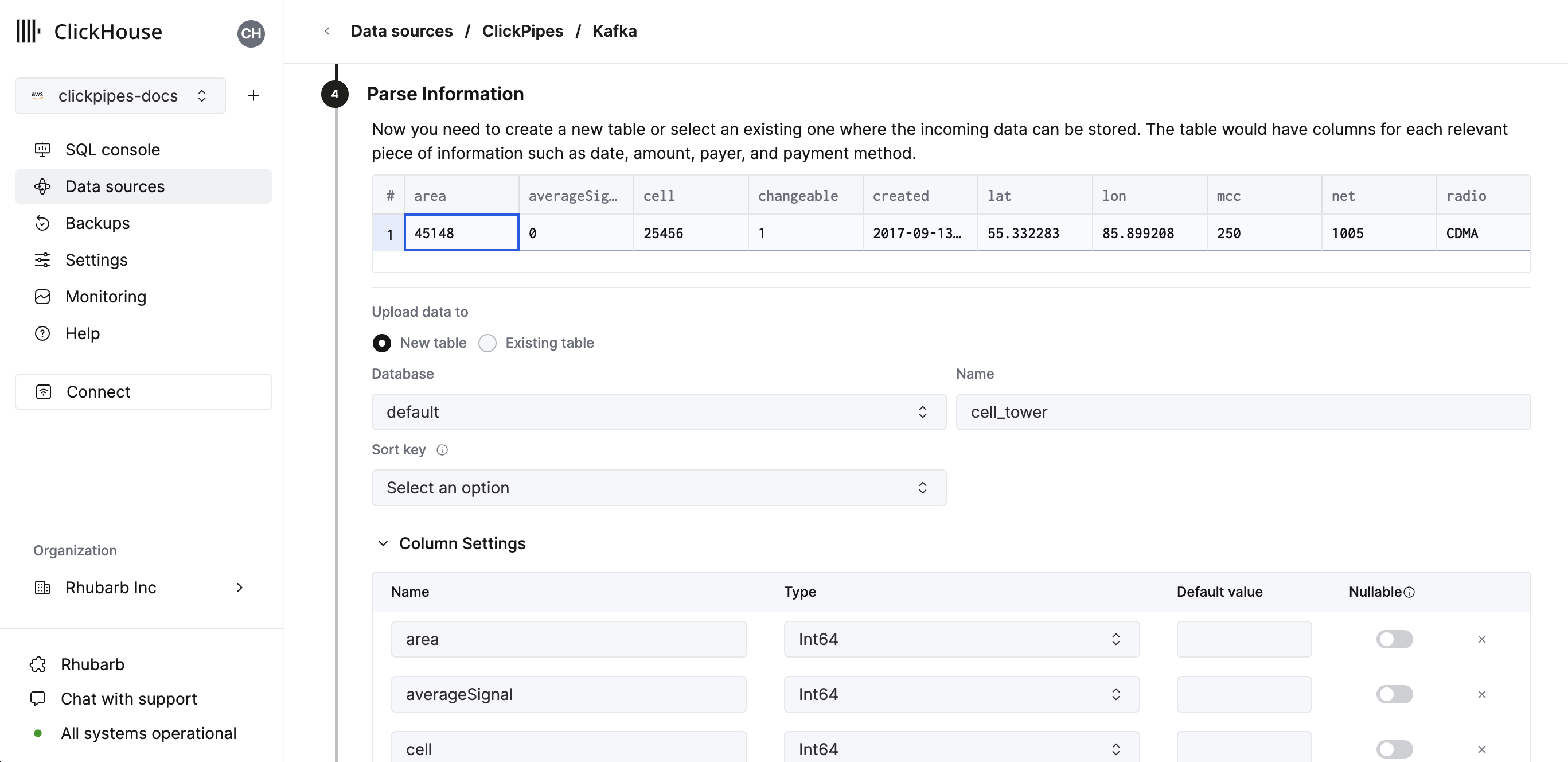
- 次のステップでは、新しい ClickHouse テーブルにデータを取り込むか、既存のテーブルを再利用するかを選択できます。画面の指示に従って、テーブル名、スキーマ、設定を変更します。画面上部のサンプルテーブルで、変更内容をリアルタイムにプレビューできます。
提供されているコントロールを使用して、詳細設定をカスタマイズすることもできます。
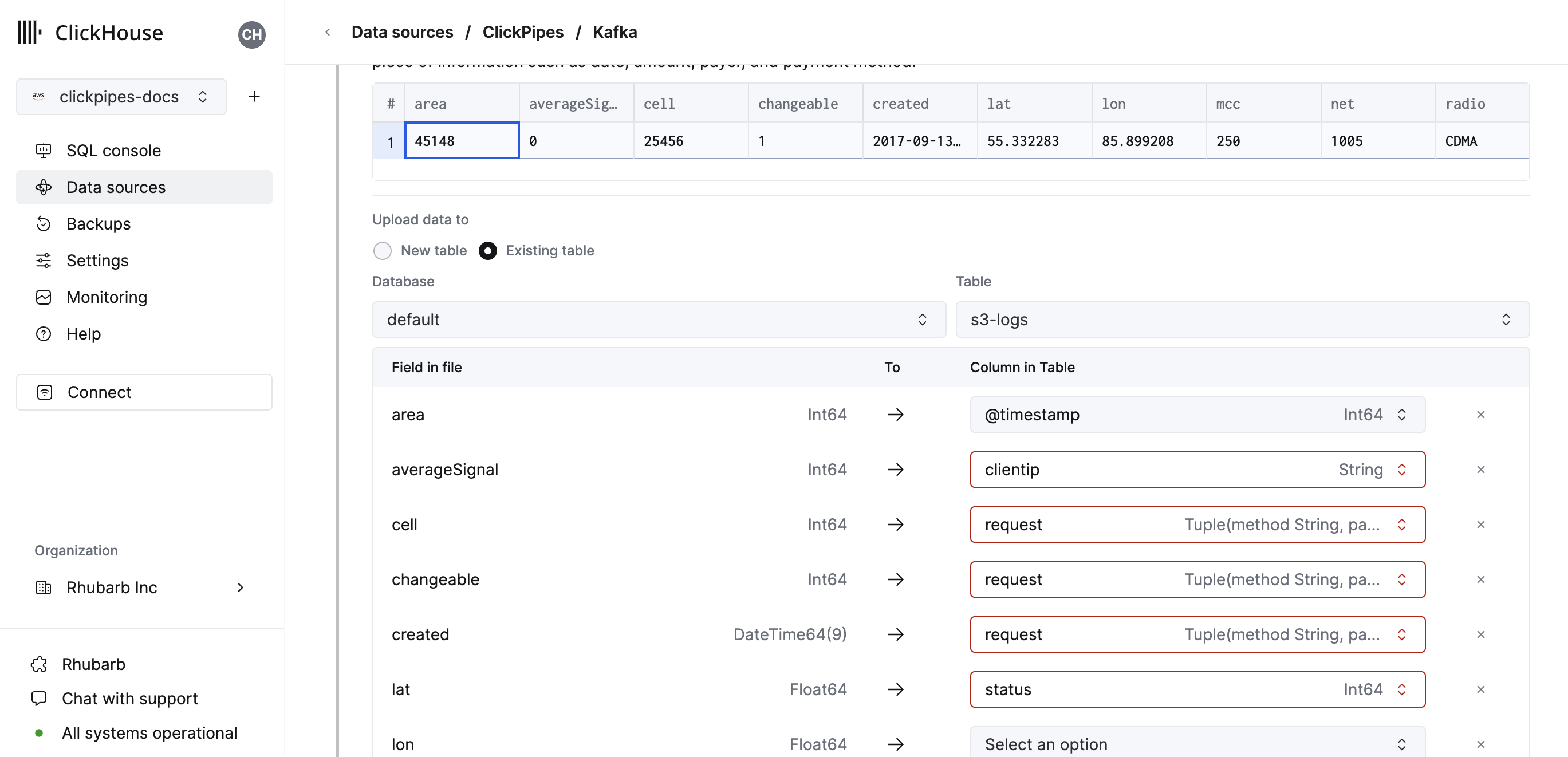
- 代わりに、既存の ClickHouse テーブルにデータを取り込むこともできます。その場合、UI でソースのフィールドを、選択した宛先テーブル内の ClickHouse フィールドにマッピングできます。
- 最後に、内部 ClickPipes ユーザーの権限を構成できます。
権限: ClickPipes は、宛先テーブルにデータを書き込む専用のユーザーを作成します。この内部ユーザーに対して、カスタムロールまたはあらかじめ定義されたロールのいずれかを選択できます。
Full access: クラスタへのフルアクセスを持つロールです。宛先テーブルで materialized view や Dictionary を使用する場合に有用です。Only destination table: 宛先テーブルに対するINSERT権限のみを持つロールです。
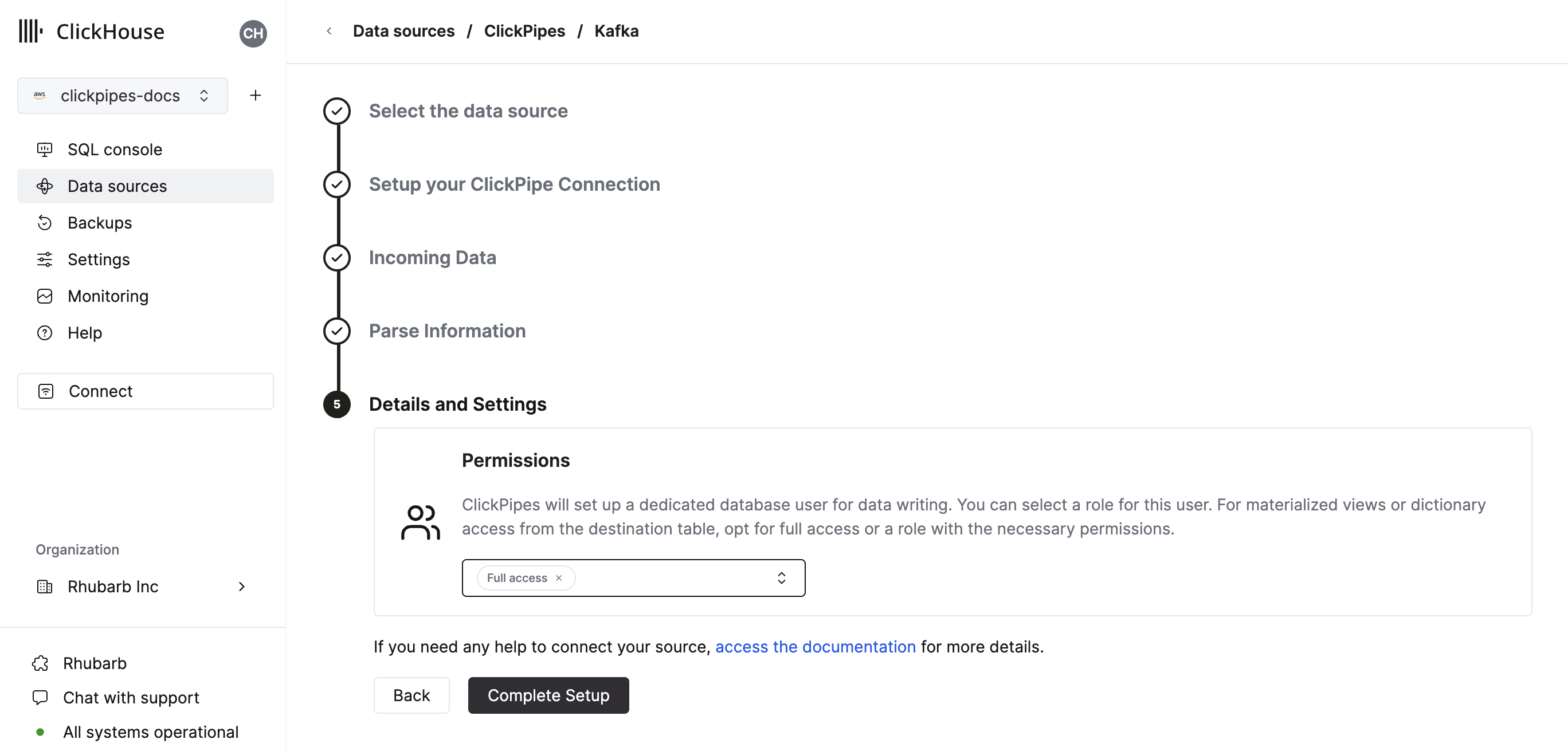
- "Complete Setup" をクリックすると、システムが ClickPipe を登録し、サマリーテーブルに一覧表示されるようになります。

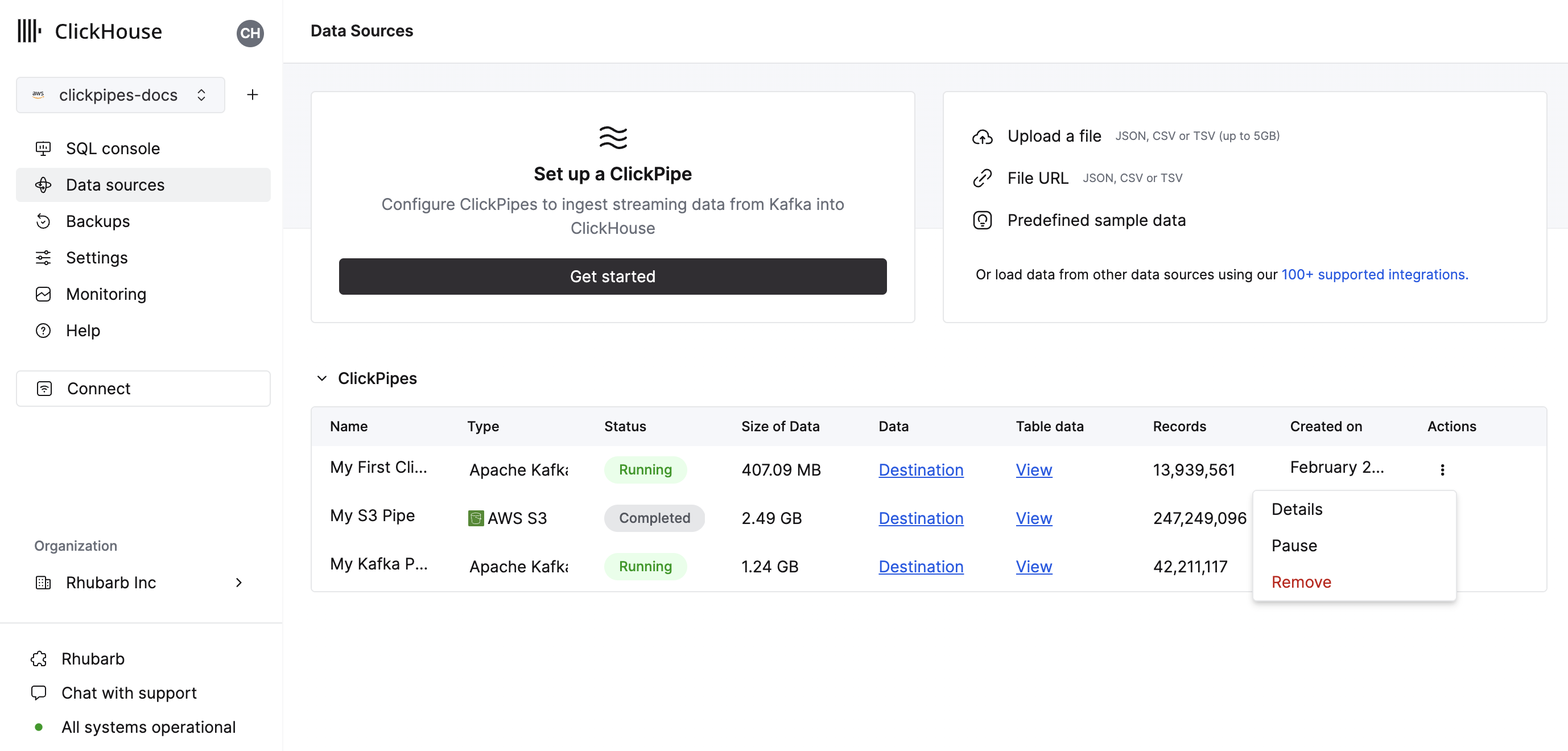
- サマリーテーブルには、ClickHouse のソースまたは宛先テーブルからサンプルデータを表示するためのコントロールが用意されています。
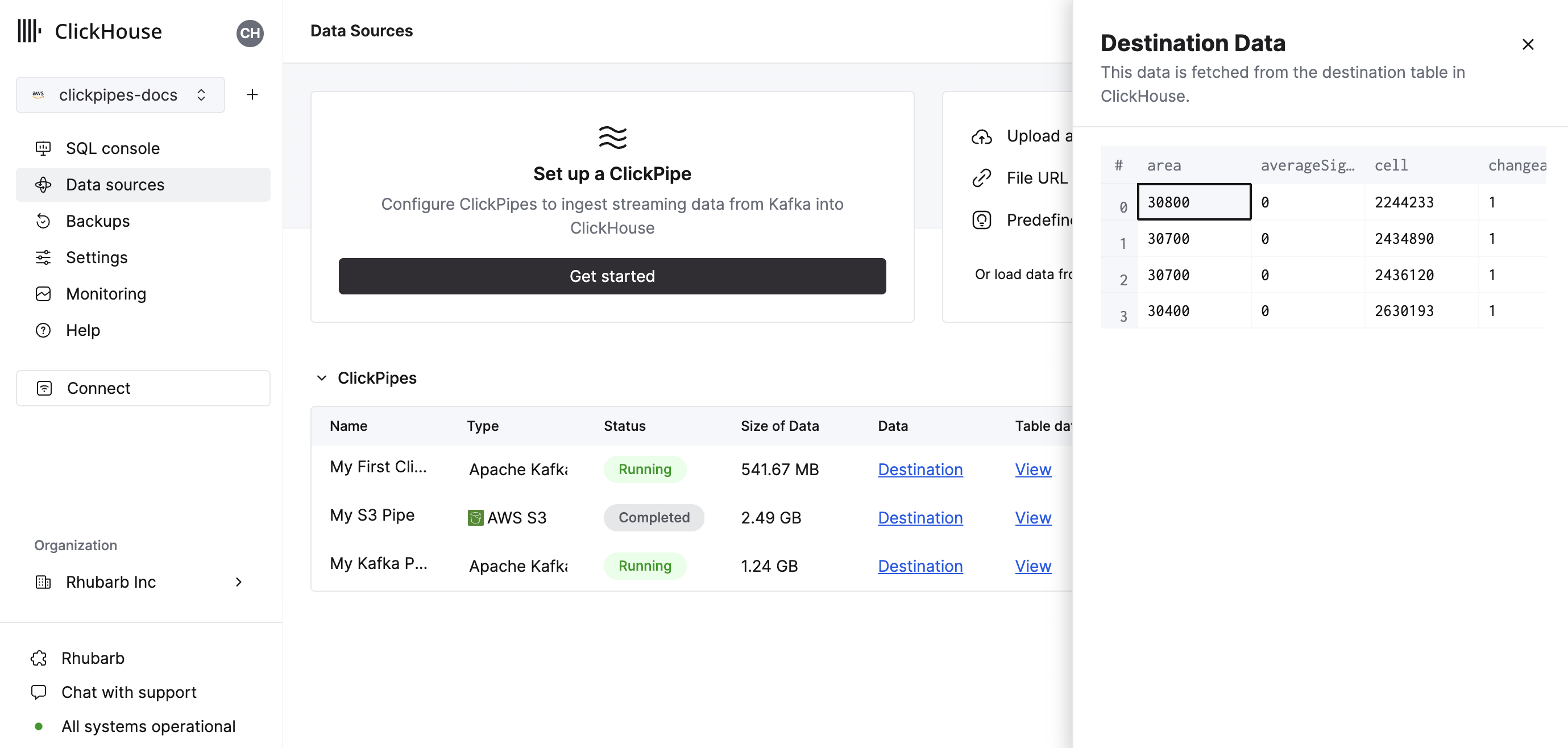
- また、ClickPipe を削除したり、取り込みジョブの概要を表示したりするためのコントロールも提供されます。
- おめでとうございます! 最初の ClickPipe のセットアップが完了しました。これがストリーミング ClickPipe の場合、リモートデータソースからリアルタイムでデータを継続的に取り込み続けます。それ以外の場合は、バッチを取り込んで完了します。
サポートされているデータ形式
サポートされているデータ形式は次のとおりです。
Compression
ClickPipes for Kinesis は、圧縮されたレコードを自動的に検出して解凍します。Kafka ではクライアントライブラリが透過的に解凍を処理するのに対し、Kinesis は生のバイト列を配信しますが、これは ClickPipes が設定不要で処理します。
サポートされている圧縮 codec は次のとおりです。
- gzip
- zstd
- lz4
- snappy (フレーム形式)
圧縮は、各レコード内のマジックバイトによって自動的に検出されます。既知の圧縮シグネチャが見つからない場合、そのレコードは非圧縮として扱われます。検出された圧縮の型は schema inference 時にも表示されるため、UI のサンプルデータプレビューには解凍後のデータが正しく表示されます。
自動検出は、JSON や CSV などのテキストベースの形式に対して安全です。これは、表示可能な ASCII 文字が圧縮のマジックバイトと衝突することがないためです。
サポート対象のデータ型
標準型のサポート
現在、ClickPipes でサポートされている ClickHouse データ型は次のとおりです:
- 基本的な数値型 - [U]Int8/16/32/64、Float32/64、および BFloat16
- 大きな整数型 - [U]Int128/256
- Decimal 型
- Boolean
- String
- FixedString
- Date, Date32
- DateTime, DateTime64(UTC タイムゾーンのみ)
- Enum8/Enum16
- UUID
- IPv4
- IPv6
- すべての ClickHouse の LowCardinality 型
- 上記のいずれかの型(Nullable を含む)をキーおよび値として使用する Map 型
- 上記のいずれかの型(Nullable を含む、1 レベルの深さのみ)を要素として使用する Tuple 型および Array 型
- SimpleAggregateFunction 型(AggregatingMergeTree または SummingMergeTree を宛先とする場合)
Variant 型サポート
ソースデータストリーム内の任意の JSON フィールドに対して、Variant(String, Int64, DateTime) のように Variant 型を手動で指定できます。
ClickPipes が使用する正しい Variant サブタイプを判別する仕組み上、Variant の定義内では整数型や DateTime 型はそれぞれ 1 種類しか使用できません。たとえば、Variant(Int64, UInt32) はサポートされません。
JSON 型サポート
常に JSON オブジェクトとなる JSON フィールドは、JSON 型の出力先カラムに割り当てることができます。固定パスやスキップするパスを含めて、出力先カラムを目的の JSON 型に手動で変更する必要があります。
Kinesis 仮想カラム
Kinesis ストリームでは、次の仮想カラムがサポートされています。新しい宛先テーブルを作成する際、Add Column ボタンを使用して仮想カラムを追加できます。
| Name | Description | Recommended Data Type |
|---|---|---|
| _key | Kinesis Partition Key | String |
| _timestamp | Kinesis Approximate Arrival Timestamp (millisecond precision) | DateTime64(3) |
| _stream | Kinesis Stream Name | String |
| _sequence_number | Kinesis Sequence Number | String |
| _raw_message | Full Kinesis Message | String |
_raw_message フィールドは、完全な Kinesis JSON レコードのみが必要な場合(下流のマテリアライズド VIEW を作成するために ClickHouse の JsonExtract* 関数を使用するケースなど)に利用できます。そのような ClickPipes パイプラインでは、すべての「非仮想」カラムを削除することで ClickPipes のパフォーマンスが向上する可能性があります。
制限事項
- DEFAULT はサポートされていません。
- 個々のメッセージは、最小のレプリカサイズ (XS) で実行している場合はデフォルトで 8MB(非圧縮)、それより大きなレプリカでは 16MB(非圧縮)に制限されます。この上限を超えるメッセージはエラーとなり、拒否されます。より大きなメッセージが必要な場合は、サポートチームまでお問い合わせください。
パフォーマンス
バッチ処理
ClickPipes はデータをバッチ単位で ClickHouse に挿入します。これは、データベース内に過剰な数のパーツが作成されることを防ぎ、それによるクラスタ内のパフォーマンス低下を回避するためです。
バッチは、次のいずれかの条件を満たしたときに挿入されます。
- バッチサイズが最大サイズに達した場合(100,000 行、またはレプリカメモリ 1GB あたり 32MB)
- バッチのオープン時間が最大値(5 秒)に達した場合
レイテンシ
レイテンシ(ここでは、Kinesis メッセージがストリームに送信されてから、そのメッセージが ClickHouse で利用可能になるまでの時間と定義します)は、複数の要因(Kinesis のレイテンシ、ネットワークのレイテンシ、メッセージのサイズやフォーマットなど)に依存します。前のセクションで説明した バッチ処理 もレイテンシに影響します。どの程度のレイテンシが見込まれるかを把握するために、ご自身のユースケースでテストすることを推奨します。
具体的な低レイテンシ要件がある場合は、こちらからお問い合わせください。
アクティブな分片
必要とするスループット要件に合わせて、同時にアクティブな分片の数を制限することを強く推奨します。"On Demand" の Kinesis ストリームの場合、AWS はスループットに基づいて自動的に適切な数の分片を割り当てますが、 "Provisioned" ストリームでは、過剰な数の分片をプロビジョニングすると、以下で説明するようなレイテンシの原因となるだけでなく、そのようなストリームに対する Kinesis の料金が分片単位で発生するため、コスト増にもつながります。
プロデューサーアプリケーションが多数のアクティブな分片に対して継続的に書き込みを行うと、パイプがこれらの分片を効率的に処理できるだけ十分にスケールしていない場合、レイテンシが発生する可能性があります。Kinesis のスループット制限に基づき、 ClickPipes は分片データを読み取るために、レプリカごとに所定数の「worker」を割り当てます。たとえば、最小構成の場合、ClickPipes レプリカにはこれらの worker スレッドが 4 つあります。プロデューサーが 同時に 4 つを超える分片に書き込みを行っている場合、worker スレッドが利用可能になるまで、追加の分片からのデータは処理されません。特に、パイプが "enhanced fanout" を使用している場合、各 worker スレッドは 1 つの分片に 5 分間サブスクライブし、 その間は他の分片を読み取ることができません。これにより、5 分単位のレイテンシの「スパイク」が発生する可能性があります。
スケーリング
ClickPipes for Kinesis は、スケールアウトおよびスケールアップの両方に対応するように設計されています。デフォルトでは、1 つのコンシューマーから成るコンシューマーグループを作成します。これは ClickPipe の作成時、または任意のタイミングで Settings -> Advanced Settings -> Scaling から設定できます。
ClickPipes は、アベイラビリティーゾーンに分散したアーキテクチャにより、高可用性を提供します。 このためには、少なくとも 2 つのコンシューマーにスケールさせる必要があります。
実行中のコンシューマー数に関係なく、フォールトトレランスは設計上備わっています。 コンシューマー、またはその基盤となるインフラストラクチャに障害が発生した場合でも、 ClickPipe はコンシューマーを自動的に再起動し、メッセージの処理を継続します。
認証
Amazon Kinesis ストリームへアクセスするには、IAM 認証情報 または IAM ロール を使用できます。IAM ロールの設定方法の詳細については、ClickHouse Cloud で利用するロールの設定手順を説明した このガイド を参照してください。
