ClickHouse Cloud クイックスタート
ClickHouse をすばやく簡単に使い始める最も手軽な方法は、ClickHouse Cloud で新しい サービスを作成することです。このクイックスタートガイドでは、3 つの簡単な手順でセットアップします。
ClickHouseサービスを作成する
ClickHouse Cloudで無料のClickHouseサービスを作成するには、以下の手順に従ってサインアップしてください:
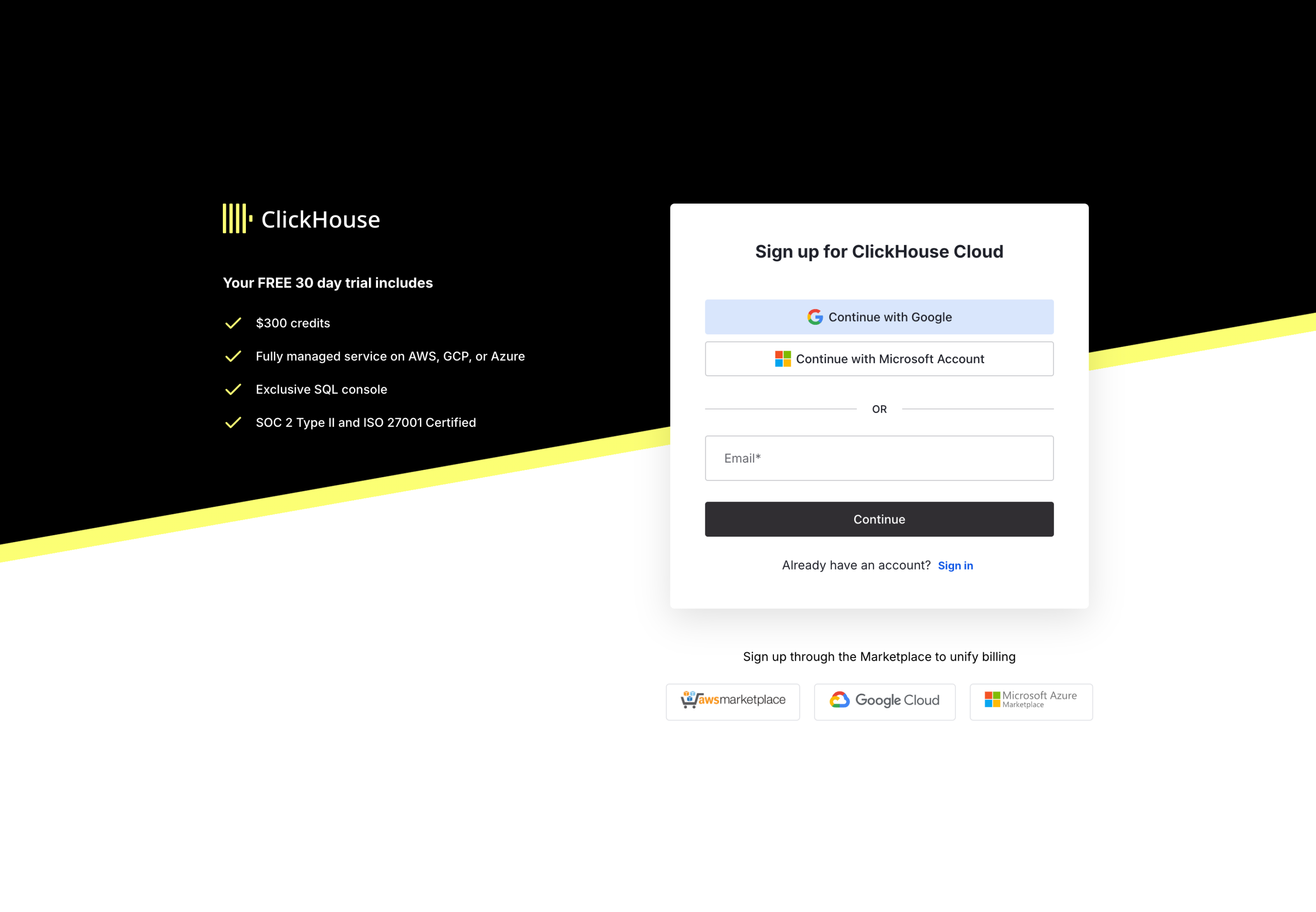
- サインアップページでアカウントを作成してください
- メールアドレス、または Google SSO、Microsoft SSO、AWS Marketplace、Google Cloud、Microsoft Azure のいずれかを利用してサインアップできます
- メールアドレスとパスワードでサインアップした場合は、届いたメール内のリンクから24時間以内にメールアドレスの確認を完了してください
- 先ほど作成したユーザー名とパスワードでログインしてください
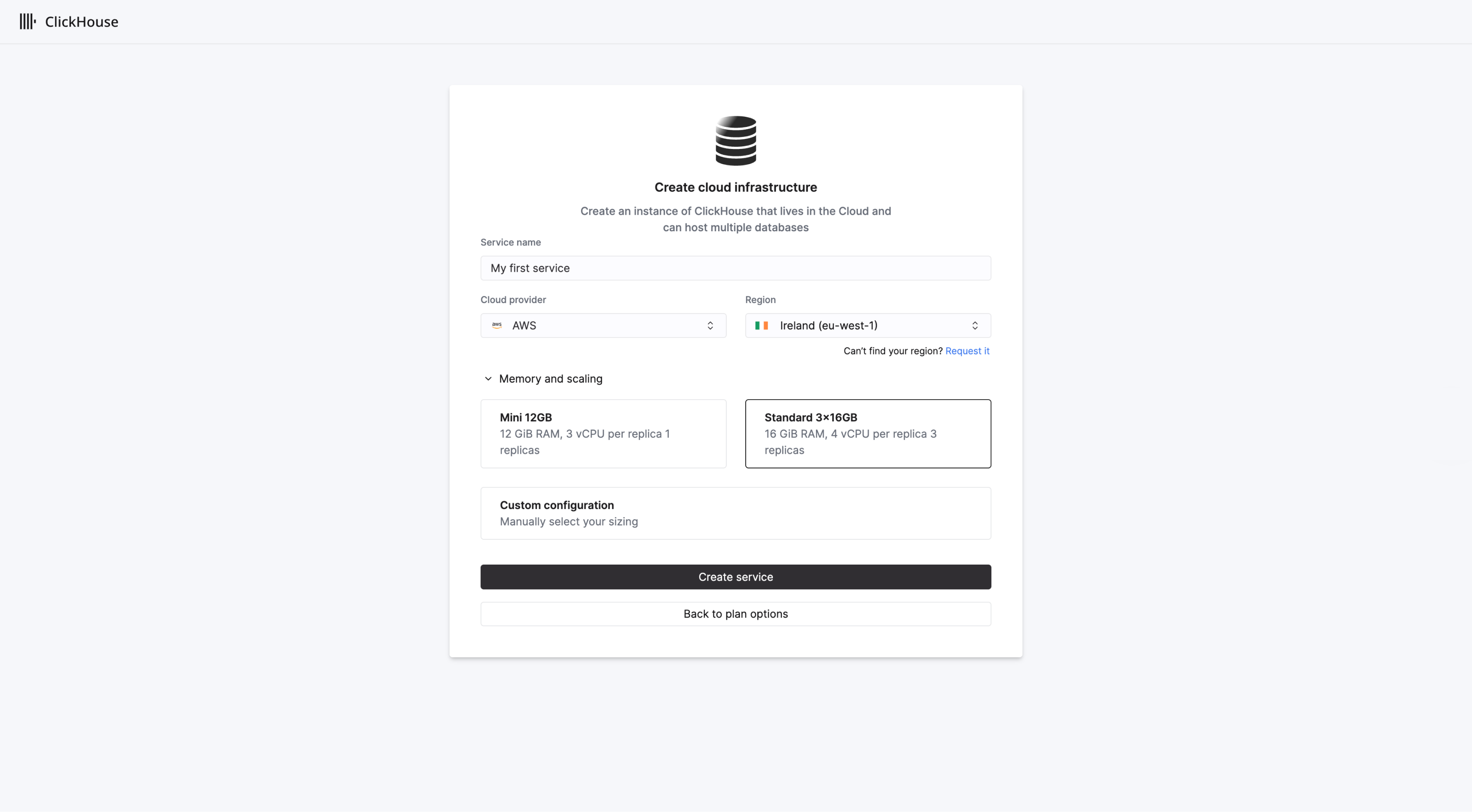
ログイン後、ClickHouse Cloudのオンボーディングウィザードが起動し、新しいClickHouseサービスの作成手順を案内します。サービスをデプロイするリージョンを選択し、新しいサービスに名前を付けてください。
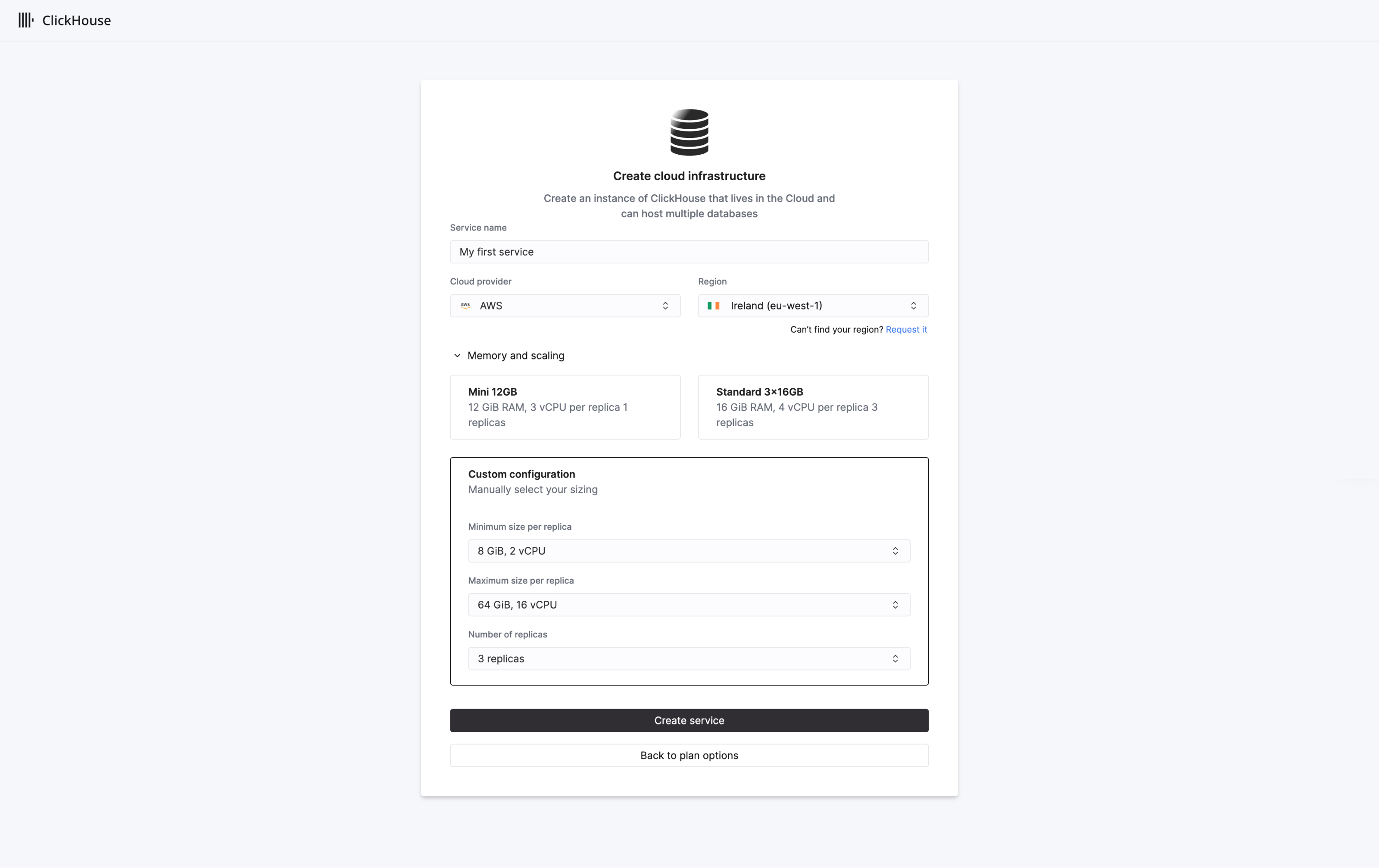
デフォルトでは、新規組織はScaleティアに配置され、各レプリカに4 vCPUと16 GiB RAMを持つ3つのレプリカが作成されます。Scaleティアでは、垂直オートスケーリングがデフォルトで有効になります。組織ティアは、後で「Plans」ページで変更できます。
必要に応じて、レプリカのスケール範囲となる最小サイズと最大サイズを指定して、サービスリソースをカスタマイズします。準備ができたら、Create serviceを選択します。
おめでとうございます!ClickHouse Cloudサービスが稼働し、オンボーディングが完了しました。データの取り込みとクエリの実行方法については、以下をご参照ください。
ClickHouseに接続する
ClickHouseへの接続方法は2つあります:
- Web ベースの SQL コンソールから接続する
- アプリケーションへの接続
SQLコンソールを使用して接続する
迅速に開始するには、ClickHouseがWebベースのSQLコンソールを提供しており、オンボーディング完了後に自動的にリダイレクトされます。
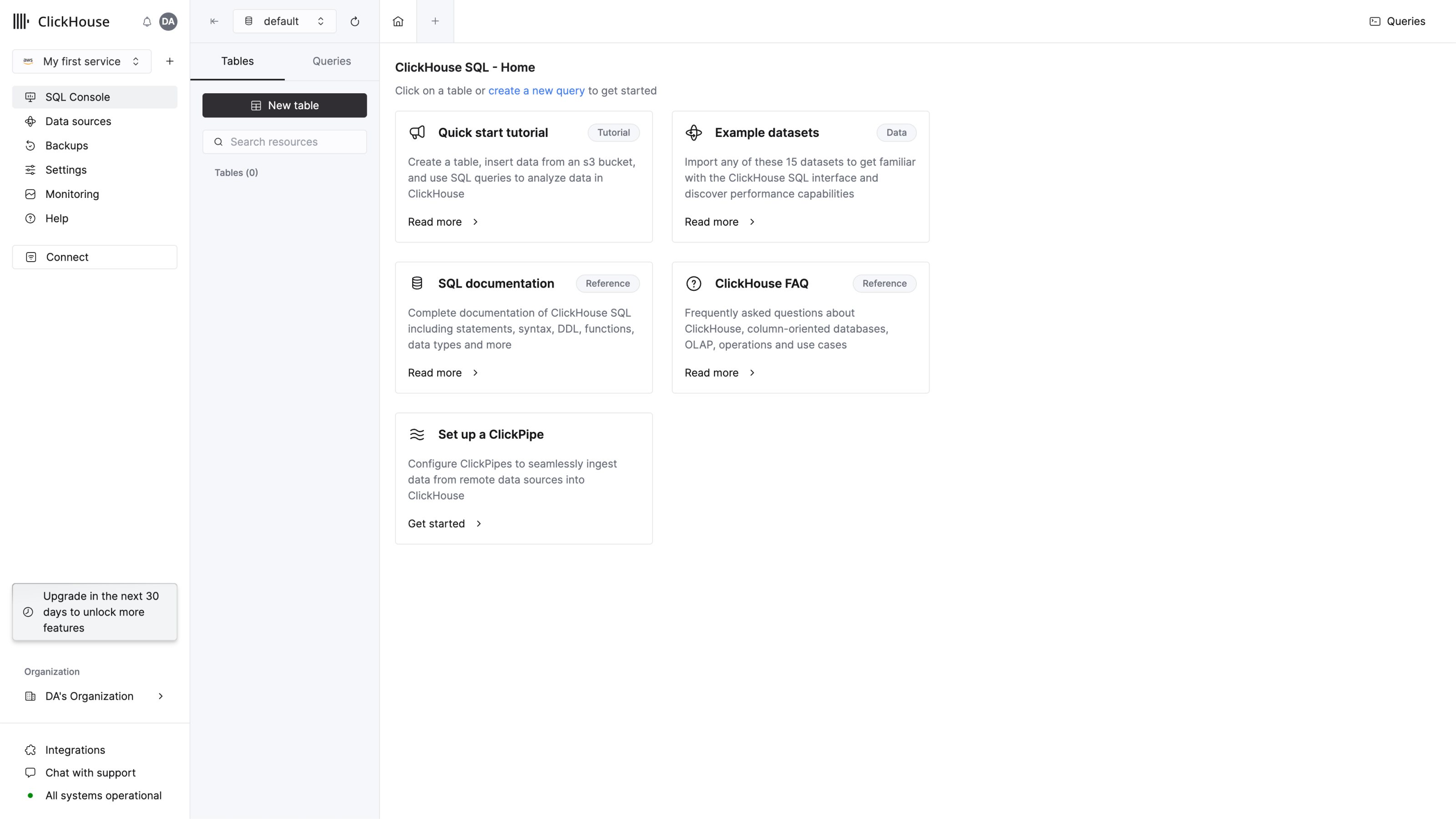
クエリタブを作成し、簡単なクエリを入力して接続が機能していることを確認します:
リストには4つのデータベースと、追加したデータベースがあればそれらも表示されます。
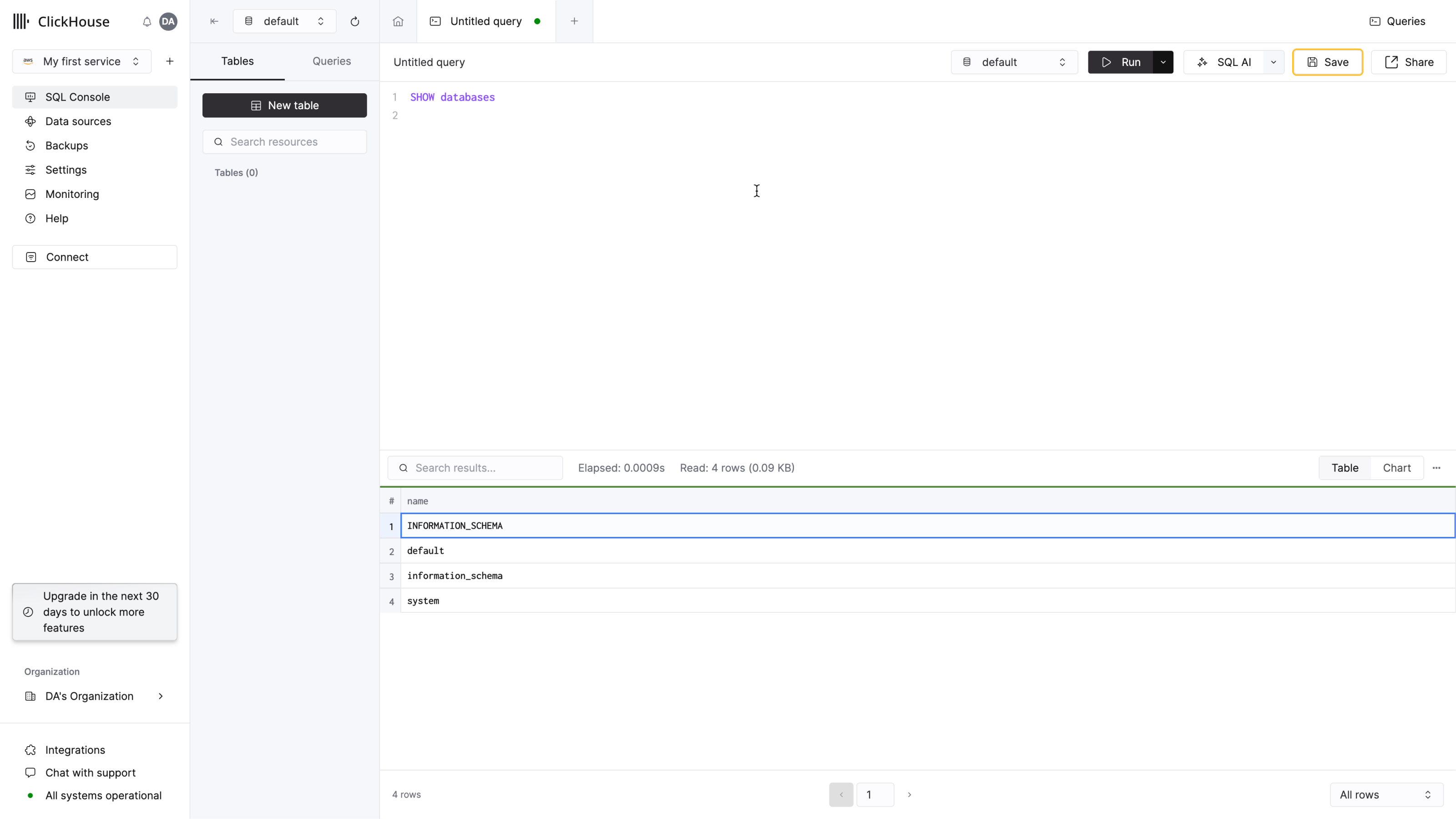
以上で完了です。新しいClickHouseサービスの使用を開始できます。
アプリケーションへの接続
ナビゲーションメニューから接続ボタンをクリックします。モーダルが開き、サービスの認証情報と、使用するインターフェースまたは言語クライアントでの接続手順が表示されます。
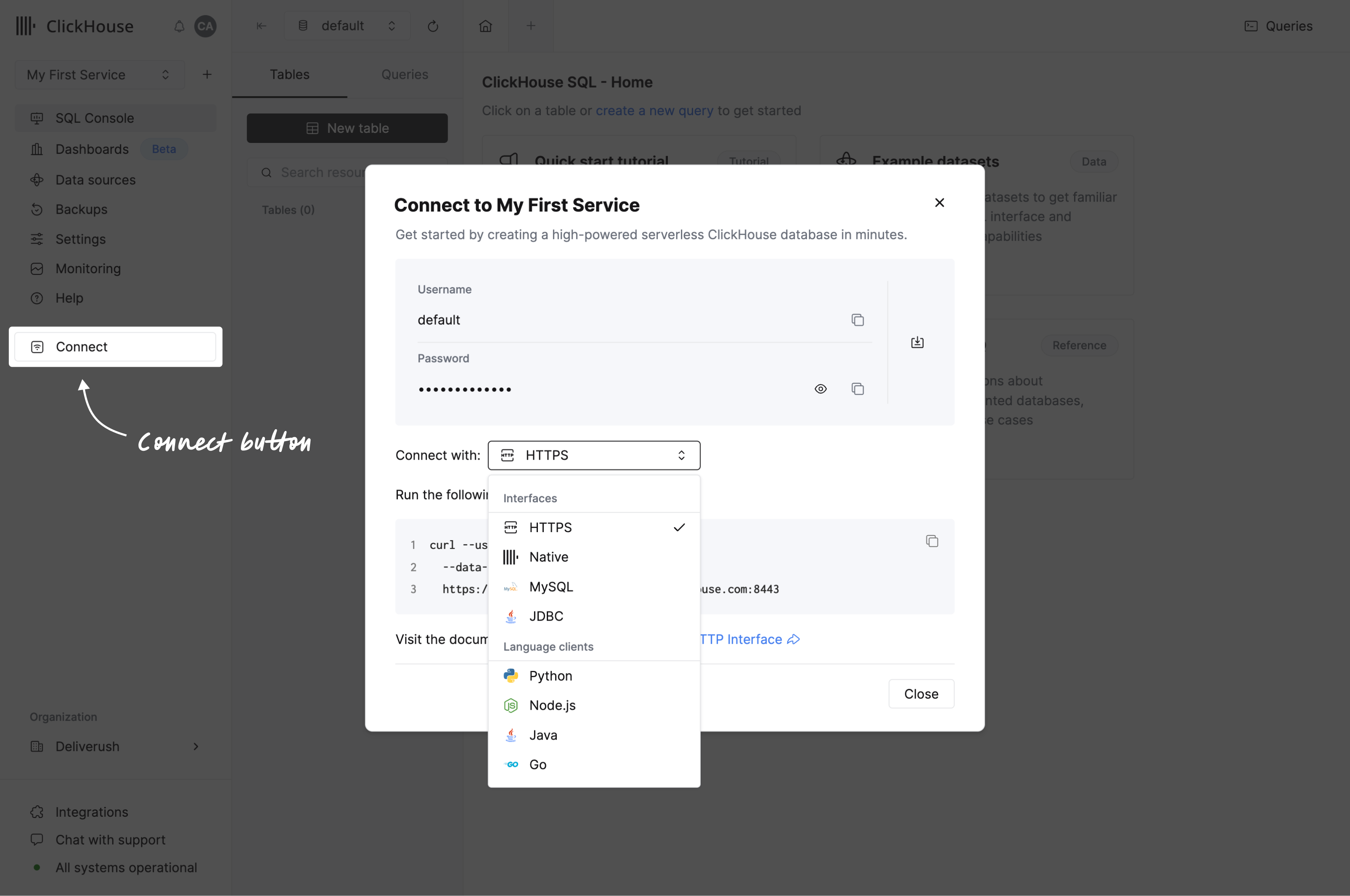
ご使用の言語クライアントが表示されない場合は、インテグレーションの一覧を確認してください。
データを追加する
ClickHouseはデータを取り込むことで真価を発揮します。データを追加する方法は複数あり、そのほとんどはナビゲーションメニューからアクセス可能なData Sourcesページで利用できます。
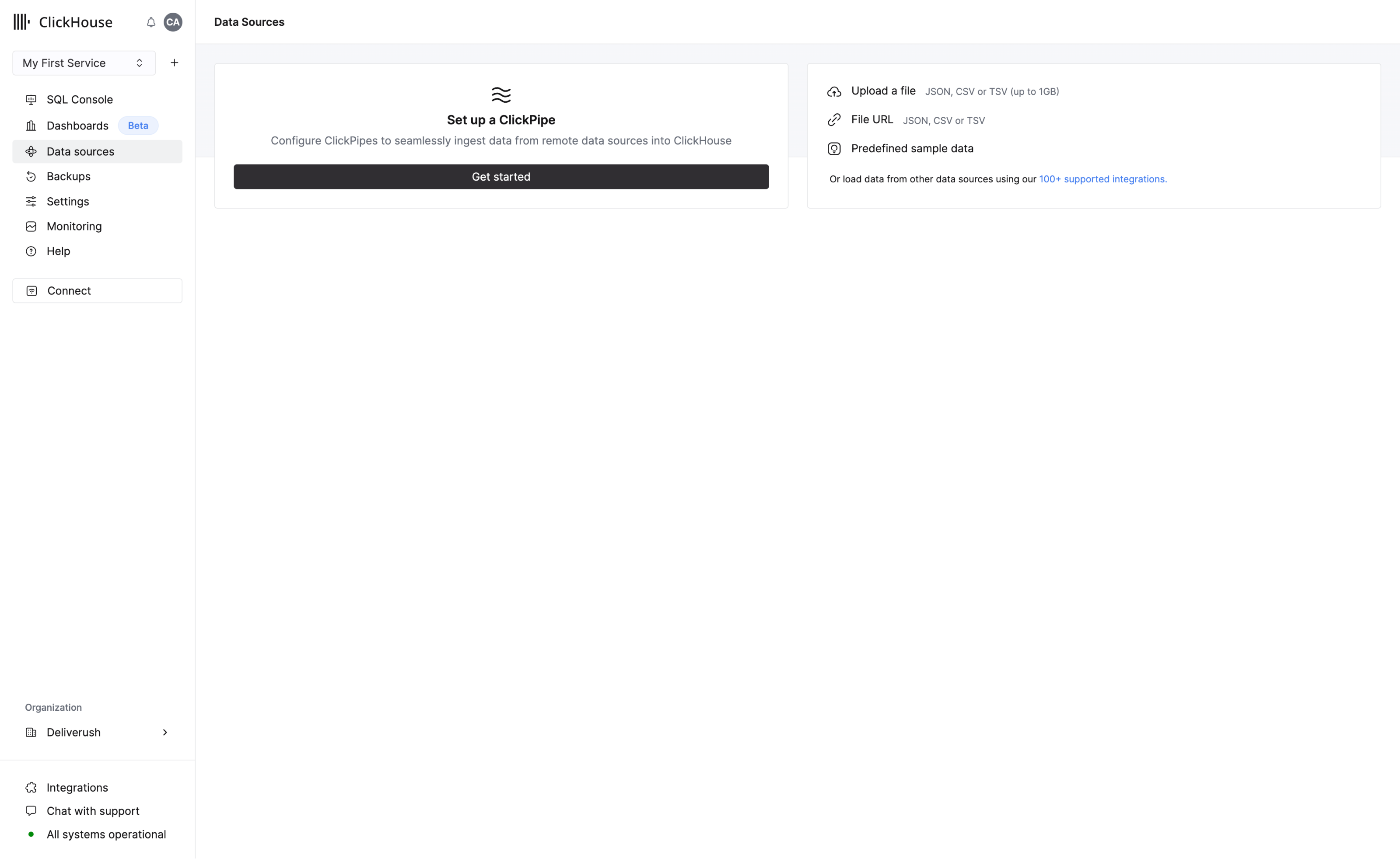
以下の方法でデータをアップロードできます:
- S3、Postgres、Kafka、GCS などのデータソースからデータを取り込み始めるために、ClickPipe を設定する
- SQLコンソールを使用する
- ClickHouse クライアントを使用する
- ファイルをアップロード - JSON、CSV、TSV 形式に対応しています
- ファイルの URL からデータをアップロードする
ClickPipes
ClickPipesは、多様なソースからのデータ取り込みを数クリックで実現するマネージド統合プラットフォームです。最も要求の厳しいワークロードに対応するよう設計されたClickPipesの堅牢でスケーラブルなアーキテクチャは、一貫したパフォーマンスと信頼性を保証します。ClickPipesは、長期的なストリーミングニーズや一回限りのデータロードジョブに使用できます。
SQLコンソールを使用したデータの追加
多くのデータベース管理システムと同様に、ClickHouseはテーブルを論理的にデータベースにグループ化します。ClickHouseで新しいデータベースを作成するには、CREATE DATABASEコマンドを使用します:
以下のコマンドを実行して、helloworldデータベースにmy_first_tableという名前のテーブルを作成します:
上記の例では、my_first_tableは4つのカラムを持つMergeTreeテーブルです:
user_id: 32ビット符号なし整数 (UInt32)message: 他のデータベースシステムにおけるVARCHAR、BLOB、CLOBなどの型に代わる String データ型timestamp: ある瞬間を表す DateTime 値metric: 32ビット浮動小数点数 (Float32)
テーブルエンジンは以下を決定します:
- データの保存場所と方法
- サポートされているクエリ
- データがレプリケートされているかどうか
選択可能なテーブルエンジンは多数ありますが、単一ノードのClickHouseサーバー上のシンプルなテーブルには、MergeTreeが最適な選択となるでしょう。
主キーの概要
先に進む前に、ClickHouse におけるプライマリキーの仕組みを理解しておくことが重要です (プライマリキーの実装は、少し意外に感じられるかもしれません) :
- ClickHouse の主キーは、テーブル内の各行に対して一意ではありません
ClickHouseテーブルの主キーは、ディスクへの書き込み時にデータがどのようにソートされるかを決定します。8,192行または10MBごとのデータ(インデックス粒度と呼ばれます)が、主キーインデックスファイルにエントリを作成します。この粒度の概念により、メモリに容易に収まるスパース索引が作成されます。各粒度は、SELECTクエリの実行時に処理される最小単位のカラムデータのストライプを表します。
主キーは PRIMARY KEY パラメータを使用して定義できます。PRIMARY KEY を指定せずにテーブルを定義した場合、キーは ORDER BY 句で指定されたタプルになります。PRIMARY KEY と ORDER BY の両方を指定した場合、主キーはソート順を構成する列のサブセットである必要があります。
プライマリキーはソートキーでもあり、(user_id, timestamp)のタプルです。したがって、各カラムファイルに格納されるデータは、user_id、次にtimestampの順でソートされます。
ClickHouseの中核概念について詳しく知るには、"コア概念"を参照してください。
テーブルにデータを挿入する
ClickHouseでは、おなじみのINSERT INTO TABLEコマンドを使用できますが、MergeTreeテーブルへの各挿入により、ストレージ内にパートが作成されることを理解しておく必要があります。
バッチごとに、数万行から数百万行といった大量の行をまとめて挿入してください。心配はいりません。ClickHouseはこの程度のボリュームであれば容易に処理でき、サービスへの書き込みリクエスト数を減らすことでコストを削減できます。
簡単な例でも、一度に複数行を挿入してみましょう:
動作したか確認してみましょう:
ClickHouseクライアントを使用したデータの追加
clickhouse clientというコマンドラインツールを使用して、ClickHouse Cloud サービスに接続することもできます。左側のメニューでConnectをクリックしてこれらの詳細にアクセスします。ダイアログのドロップダウンからNativeを選択します:
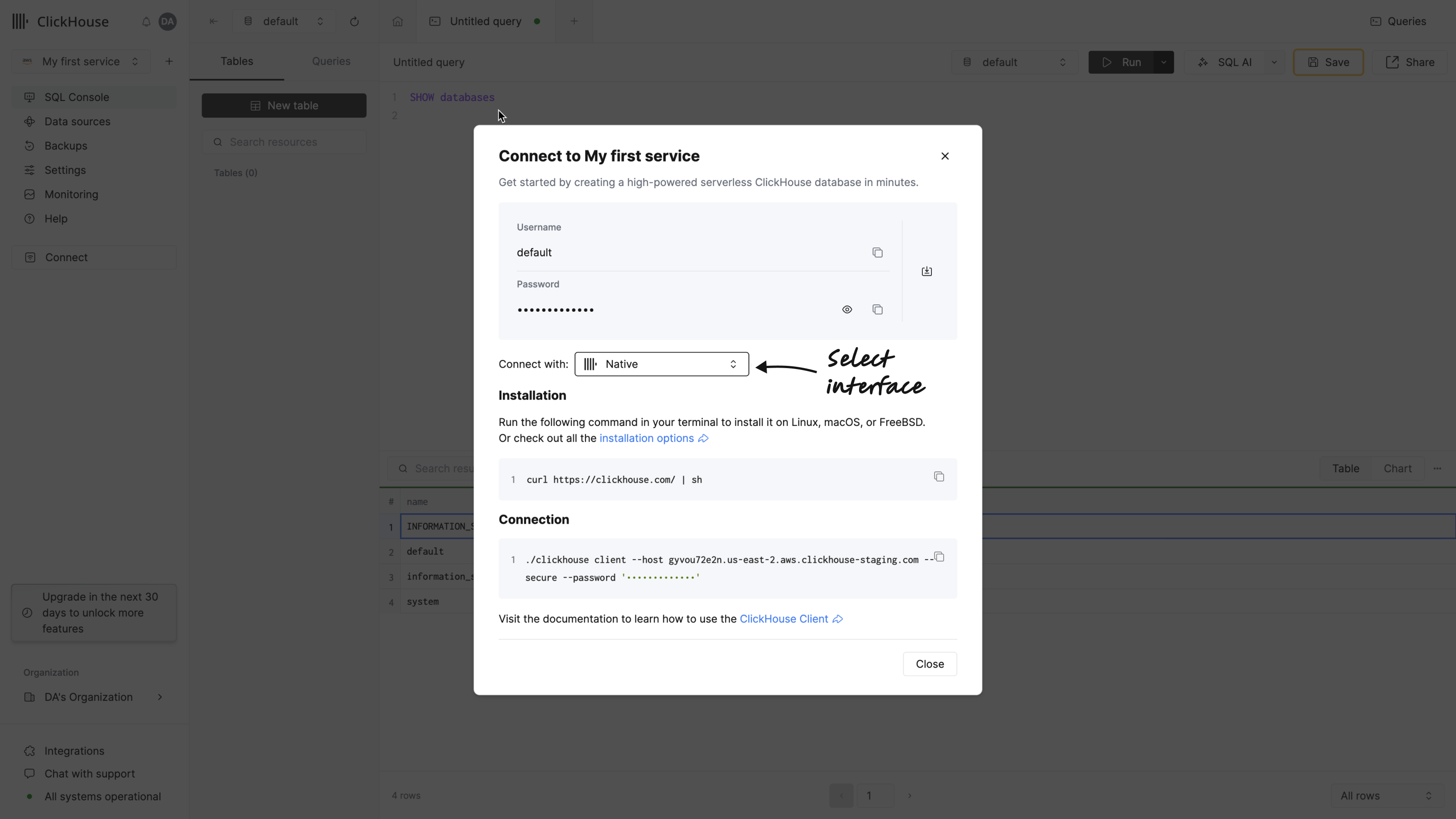
-
ClickHouse をインストールします。
-
ホスト名、ユーザー名、パスワードをご自身の環境に合わせた値に置き換えて、コマンドを実行します。
スマイリーフェイスのプロンプトが表示されたら、クエリを実行できます。
- 次のクエリを実行してみましょう:
レスポンスが見やすいテーブル形式で返ってくることに注目してください:
FORMAT句を追加して、ClickHouse がサポートする多様な出力フォーマットのいずれかを指定します。
上記のクエリでは、出力は次のようにタブ区切りで返されます:
clickhouse clientを終了するには、exit と入力します。
ファイルのアップロード
データベースを使い始めるときによく行う作業の一つは、すでにファイルにあるデータを挿入することです。クリックストリームデータを表すサンプルデータをオンラインで提供しており、これを挿入できます。このデータにはユーザーID、訪問したURL、そしてイベントのタイムスタンプが含まれます。
data.csvという名前のCSVファイルに以下のテキストが含まれているとします:
- 次のコマンドでデータを
my_first_tableに挿入します。
- SQLコンソールからクエリを実行すると、テーブルに新しい行が表示されていることを確認できます:
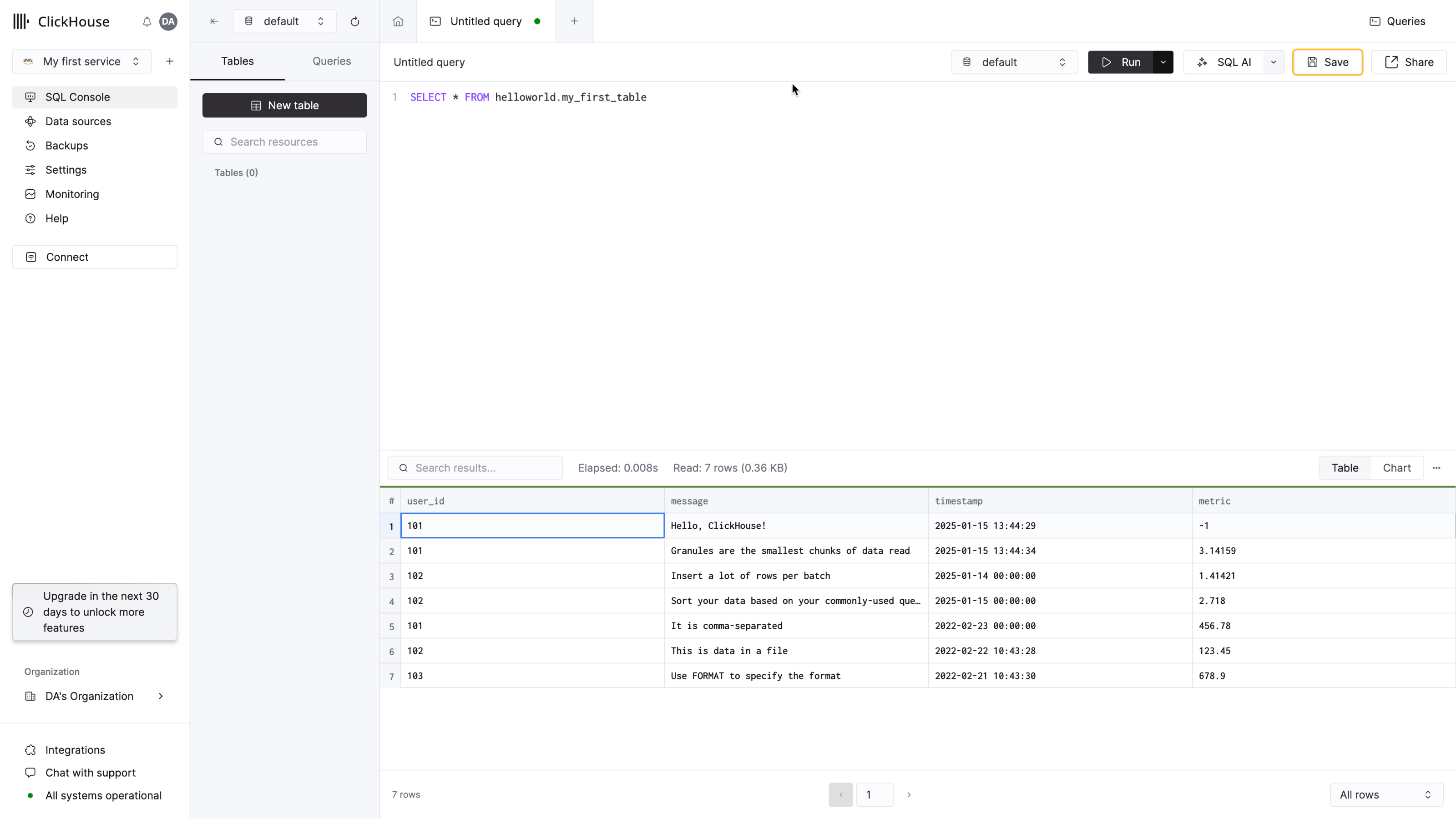
次に進む前に、IP アクセスリストフィルタリングを設定しておくことを推奨します。 詳細は「IP フィルタの設定」を参照してください。
次のステップは?
- チュートリアル では、テーブルに 200 万行を挿入し、いくつかの分析クエリを実行します
- サンプルデータセット の一覧と、それらを挿入する手順を用意しています
- Getting Started with ClickHouse の 12 分間の動画をご覧ください
- データを外部ソースから取り込む場合は、メッセージキュー、データベース、パイプラインなどへの接続方法を説明した インテグレーションガイド集 を参照してください
- UI/BI の可視化ツールを使用している場合は、UI を ClickHouse に接続するためのユーザーガイド を参照してください
- プライマリキー に関するユーザーガイドには、プライマリキーについて知っておくべきことと、その定義方法に関する情報がすべてまとまっています
