環境センサーデータ
Sensor.Community は、オープンな環境データを生成する、貢献者主導のグローバルなセンサーネットワークです。データは世界中のセンサーから収集されています。誰でもセンサーを購入して、好きな場所に設置できます。データをダウンロードするための API は GitHub に公開されており、データは Database Contents License (DbCL) に基づいて自由に利用できます。
情報
このデータセットには 200 億件を超えるレコードがあるため、下記のコマンドをそのままコピー&ペーストする場合は、この規模のデータ量を処理できるリソースがあることを確認してください。以下のコマンドは、ClickHouse Cloud の Production インスタンス上で実行されました。
- データは S3 にあるため、
s3テーブル関数を使用してファイルからテーブルを作成できます。また、データをその場でクエリすることも可能です。ClickHouse への挿入を行う前に、いくつかの行を確認してみましょう。
データは CSV ファイルですが、区切り文字にはセミコロンが使われています。行は次のような形式です:
- ClickHouse にデータを保存するために、次の
MergeTreeテーブルを使用します。
- ClickHouse Cloud のサービスには
defaultという名前のクラスタがあり、クラスタ内のノードから並列に S3 ファイルを読み取るs3Clusterテーブル関数を使用します。(クラスタがない場合は、s3関数のみを使用し、クラスタ名の指定は行わないでください。)
このクエリの実行にはしばらく時間がかかります。非圧縮のデータ量は約 1.67T あります。
こちらがレスポンスで、行数と処理速度が表示されています。1 秒あたり 600 万行以上のレートでデータが取り込まれています!
sensorsテーブルに必要なディスク容量がどれくらいか確認します。
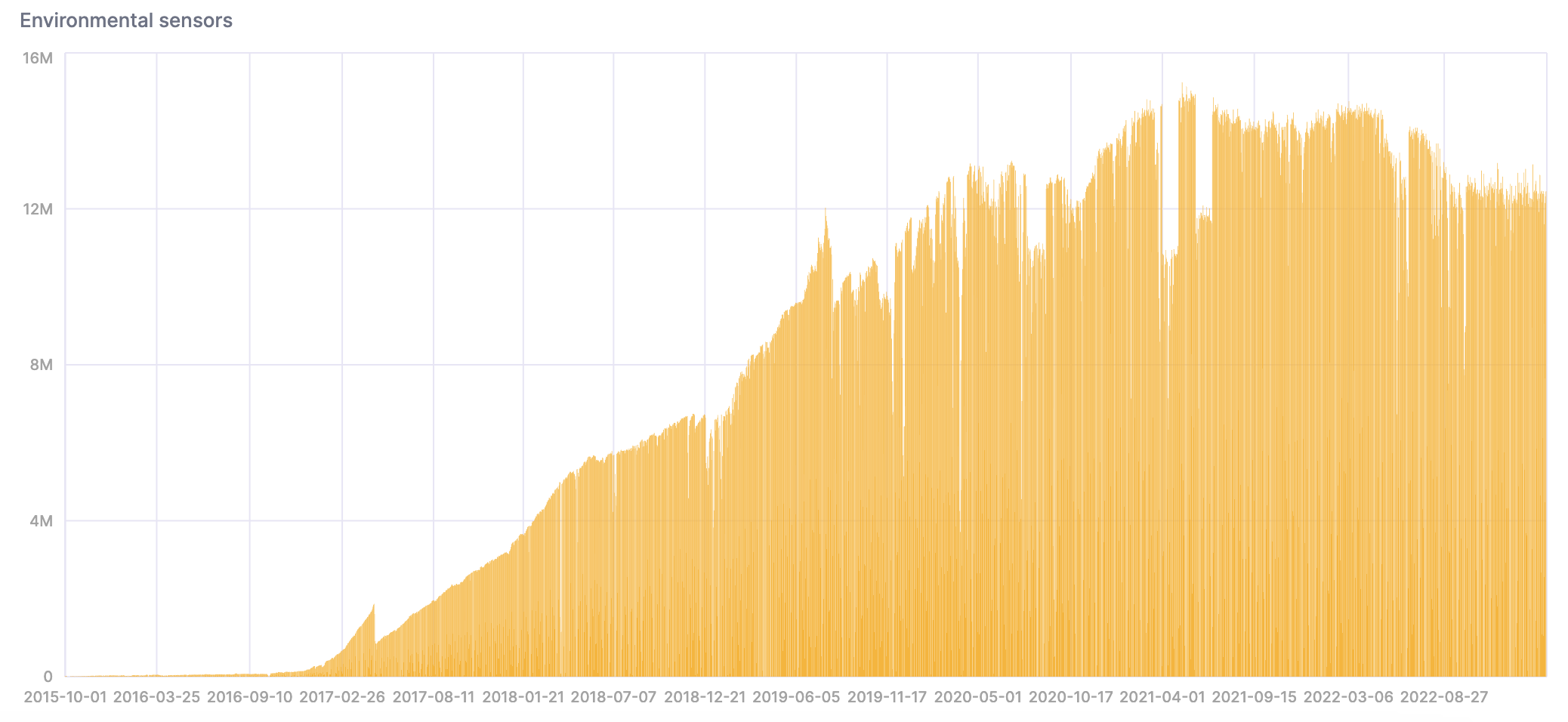
1.67T のデータは 310 GiB にまで圧縮され、総行数は 206.9 億行です。
- データが ClickHouse に取り込まれたので、これから分析してみましょう。センサーの設置数が増えるにつれて、時間の経過とともにデータ量が増加していることに注目してください。
SQL コンソールでチャートを作成して、結果を可視化できます。
- このクエリは、非常に暑く蒸し暑い日の数を集計します。
結果を可視化したものがこちらです。