列指向データベースとは何ですか?
列指向データベースは、各列のデータを独立して格納します。これにより、任意のクエリで実際に使用されるカラムだけをディスクから読み取ることができます。その代償として、行全体に対して行う処理は、相対的に高コストになります。列指向データベースは、カラム指向データベース管理システムと呼ばれることもあります。ClickHouse はその典型的な例です。
列指向データベースの主な利点は次のとおりです。
- 多数のカラムのうち、ごく一部のカラムだけを使用するクエリ。
- 大量データに対する集計クエリ。
- 列単位でのデータ圧縮。
レポート作成時における、従来の行指向システムと列指向データベースの違いを図で示します。
従来の行指向
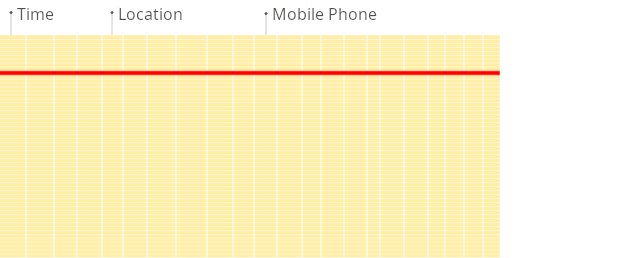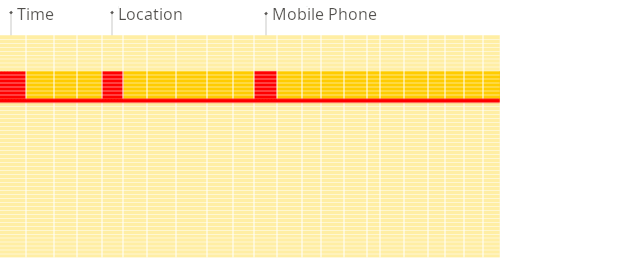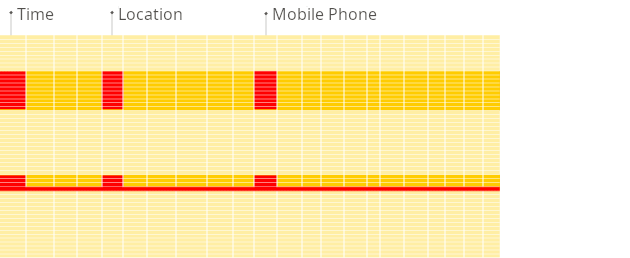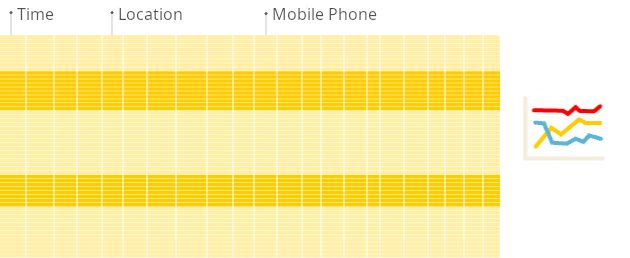
列指向
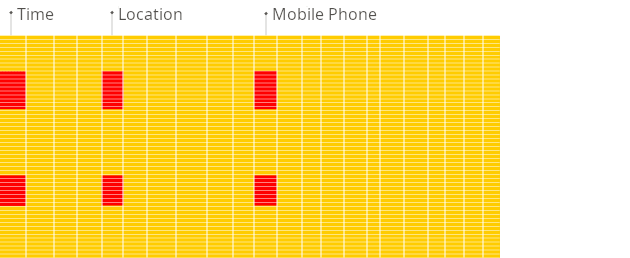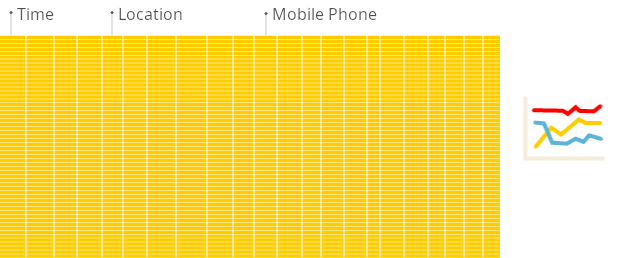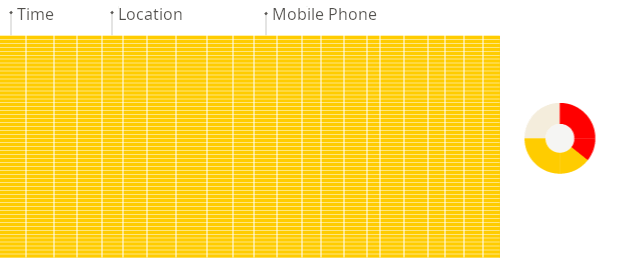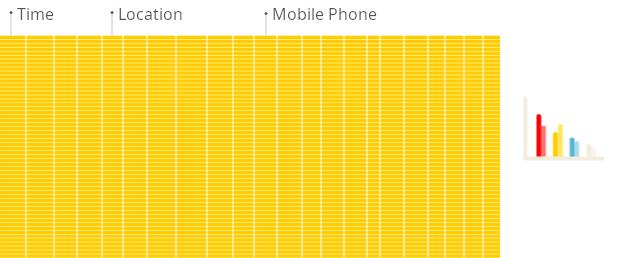
列指向データベースは分析アプリケーションに最適です。テーブルに多くのカラムを「念のため」に定義しておくことができる一方で、読み取りクエリの実行時に未使用のカラムのコストを支払わずに済むためです (従来の OLTP データベースは、データがカラムではなく行として格納されているため、クエリ時にすべてのデータを読み取ります) 。列指向データベースはビッグデータ処理やデータウェアハウジング向けに設計されており、スループットを高めるために、低コストなハードウェアからなる分散クラスターを用いてネイティブにスケールアウトすることがよくあります。ClickHouse はこれを、distributed テーブルと replicated テーブルの組み合わせで実現します。
列指向データベースの歴史、行指向データベースとの違い、列指向データベースのユースケースについて詳しく知りたい場合は、列指向データベースに関するガイドを参照してください。
