並列レプリカ
はじめに
ClickHouse はクエリを非常に高速に処理しますが、これらのクエリはどのようにして 複数のサーバーに分散され、並列実行されているのでしょうか。
このガイドではまず、ClickHouse が分散テーブルを用いてクエリを複数のシャードにどのように分散するかを説明し、その後、クエリの実行に複数のレプリカをどのように活用できるかを解説します。
Sharded architecture
シェアードナッシング (shared-nothing) アーキテクチャでは、クラスタは一般的に複数のシャードに分割され、各シャードには全体のデータのサブセットが含まれます。その上位に分散テーブルが配置され、全データの一貫したビューを提供します。
読み取りはローカルテーブルに送ることもできます。この場合、クエリ実行は指定したシャード上でのみ行われます。または分散テーブルに送ることもでき、その場合は各シャードが指定されたクエリを実行します。分散テーブルに対してクエリが発行されたサーバーがデータを集約し、クライアントに応答します。
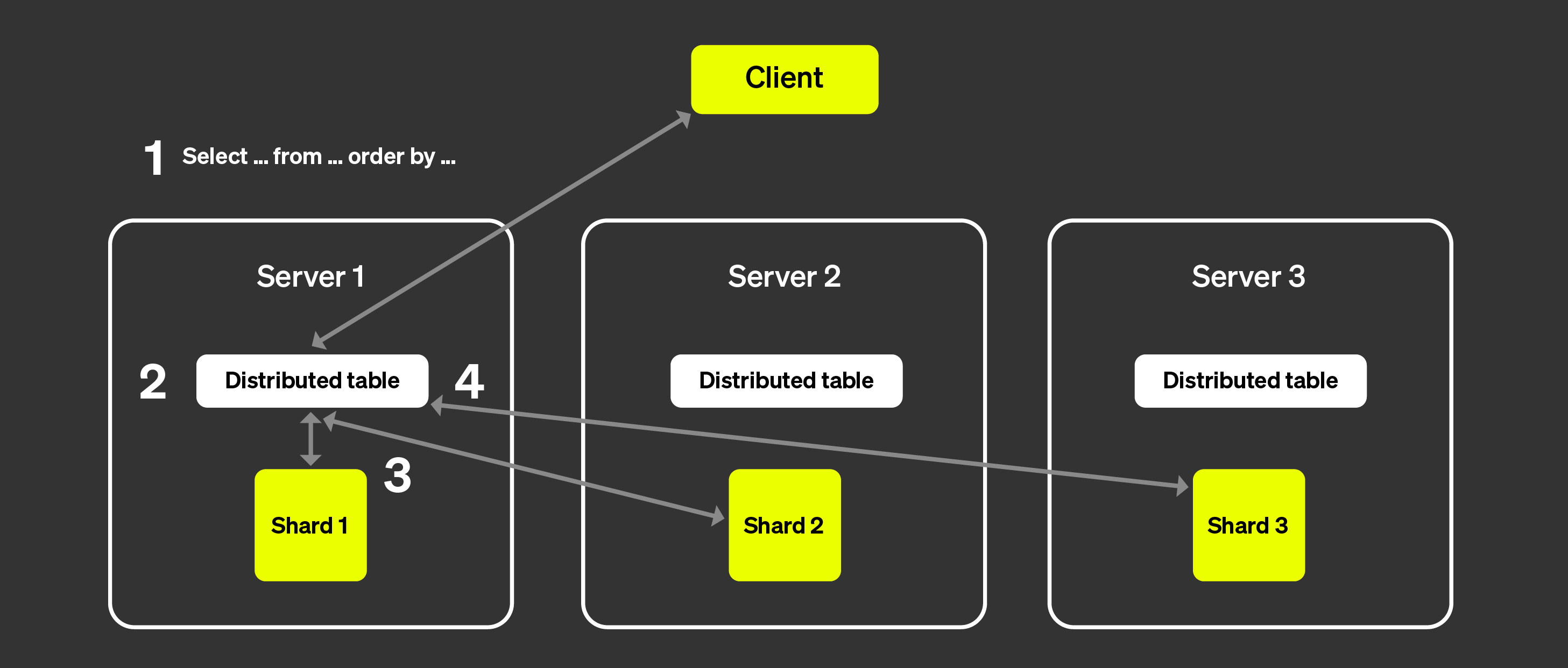
上図は、クライアントが分散テーブルにクエリを実行したときに何が起こるかを示しています。
SELECT クエリは、任意のノード上の分散テーブルに送信されます (ラウンドロビン戦略で選択されたノード、またはロードバランサーによって 特定のサーバーにルーティングされたノードなど) 。このノードが コーディネータとして動作します。
ノードは、分散テーブルに指定された情報を用いて、クエリを実行する必要がある 各シャードを特定し、クエリをそれぞれのシャードに送信します。
各シャードはローカルでデータを読み取り、フィルタおよび集約したうえで、 マージ可能な状態をコーディネータに返します。
コーディネータノードがデータをマージし、その結果をクライアントに 応答として返します。
レプリカを追加した場合もプロセスはほぼ同様で、唯一の違いは、各シャードからは単一のレプリカのみがクエリを実行する点です。これにより、より多くのクエリを並列に処理できるようになります。
非シャーディングアーキテクチャ
ClickHouse Cloud は、前述のアーキテクチャとは大きく異なるアーキテクチャを採用しています。 (詳細については、"ClickHouse Cloud Architecture" を参照してください) 。コンピュートとストレージが分離され、事実上無制限のストレージ容量が 利用できるため、シャードの必要性はそれほど重要ではなくなります。
次の図は ClickHouse Cloud のアーキテクチャを示しています。
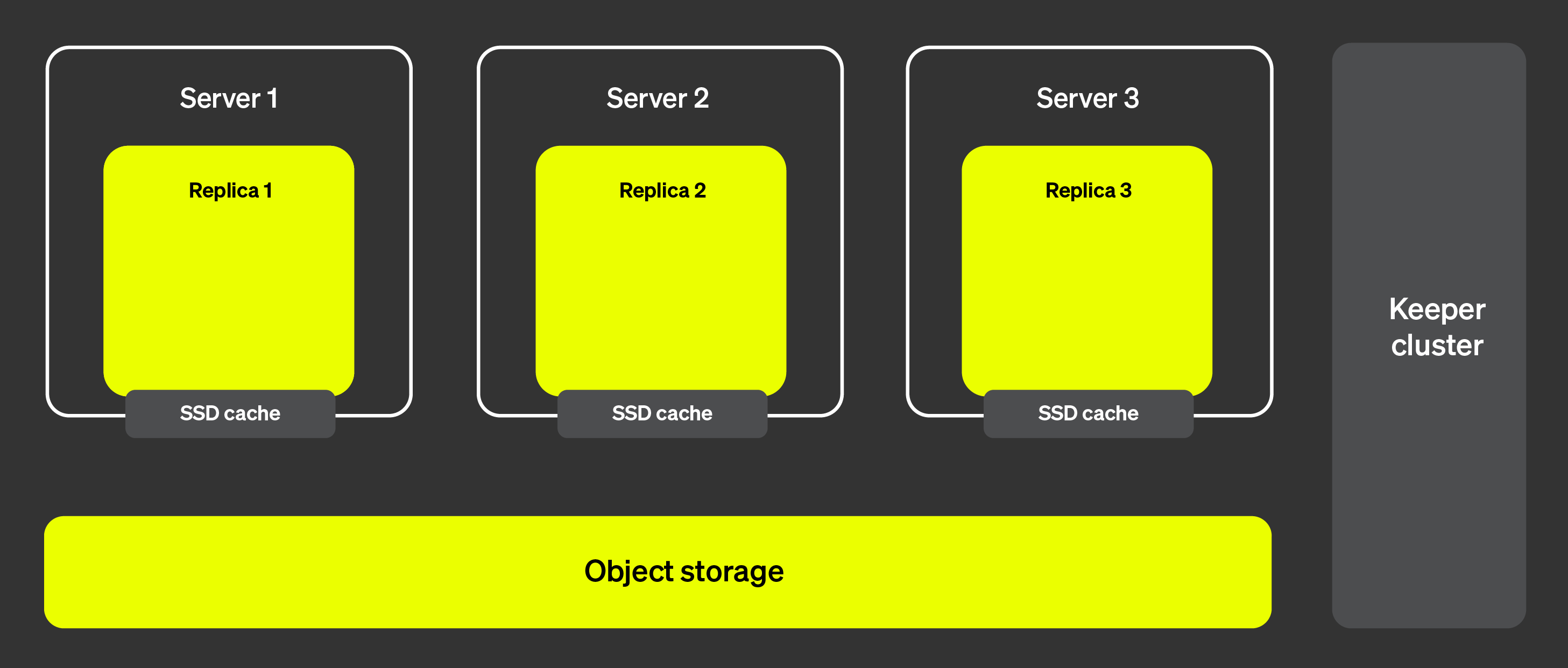
このアーキテクチャにより、レプリカをほぼ瞬時に追加・削除できるようになり、クラスタの スケーラビリティを非常に高いレベルで確保できます。右側に示されている ClickHouse Keeper クラスタは、メタデータに関する単一の信頼できる情報源 (single source of truth) として機能します。レプリカは ClickHouse Keeper クラスタからメタデータを取得し、すべて同じデータを保持します。データ本体は オブジェクトストレージに保存され、SSD キャッシュによってクエリを高速化します。
では、どのようにしてクエリ実行を複数のサーバーに分散させればよいのでしょうか。 シャーディングされたアーキテクチャでは、各シャードがデータのサブセットに対して クエリを実行できるため、その方法は比較的明確でした。では、シャーディングがない場合には どのように実現しているのでしょうか。
並列レプリカの概要
複数のサーバーでクエリ実行を並列化するには、まずサーバーの 1 つを コーディネーターとして割り当てられるようにする必要があります。コーディネーターは、 実行すべきタスクの一覧を作成し、それらがすべて実行・集約され、結果がクライアントに 返されることを保証する役割を担います。多くの分散システムと同様に、この役割は 最初のクエリを受け取るノードが担当します。また、作業単位も定義する必要があります。 シャーディングアーキテクチャでは、作業単位はデータの部分集合であるシャードです。 並列レプリカでは、作業単位として、テーブルの一部である granules と呼ばれる小さな単位を使用します。
では、以下の図を用いて、実際にどのように動作するかを見ていきましょう。
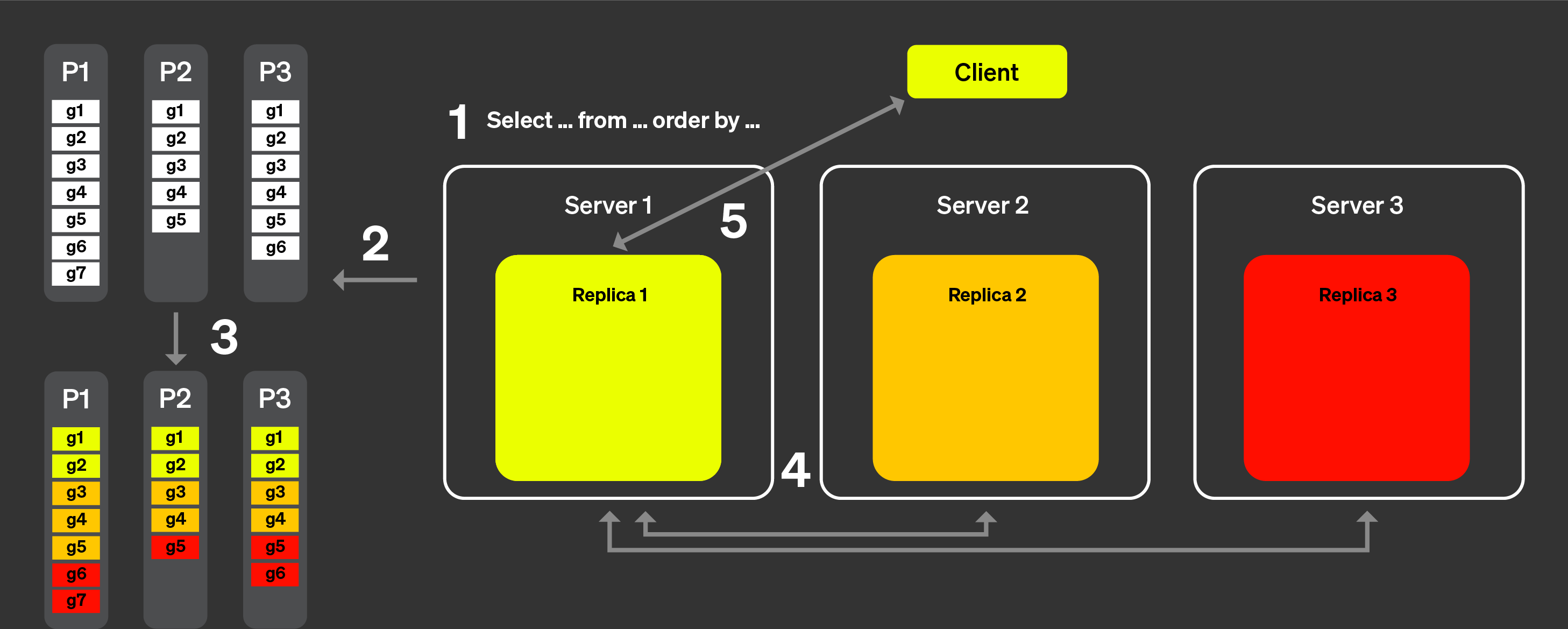
並列レプリカでは、次のようになります。
クライアントからのクエリはロードバランサーを通過した後、1 つのノードに 送信されます。このノードがこのクエリのコーディネーターになります。
ノードは各パーツのインデックスを解析し、処理すべき適切なパーツと granule を選択します。
コーディネーターは、ワークロードを複数の granule の集合に分割し、 それぞれを異なるレプリカに割り当てられるようにします。
各 granule の集合は対応するレプリカによって処理され、完了後、 マージ可能な状態がコーディネーターに送信されます。
最後に、コーディネーターがレプリカからのすべての結果をマージし、 レスポンスをクライアントに返します。
上記のステップは、並列レプリカが理論上どのように動作するかを説明したものです。 しかし、実際には、このようなロジックが完全には機能しない要因が多数存在します。
一部のレプリカが利用不能になっている場合があります。
ClickHouse におけるレプリケーションは非同期であるため、ある時点では 一部のレプリカが同じパーツを保持していない可能性があります。
レプリカ間のテールレイテンシを何らかの方法で扱う必要があります。
ファイルシステムキャッシュは各レプリカ上のアクティビティに応じて レプリカごとに異なるため、タスクをランダムに割り当てると、 キャッシュの局所性を考慮した場合に最適とは言えない性能につながることがあります。
これらの要因をどのように克服するかについては、次のセクションで説明します。
アナウンスメント
上記のリストの (1) と (2) に対応するために、「アナウンスメント」という概念を導入しました。以下の図を使って、その仕組みを確認してみましょう。
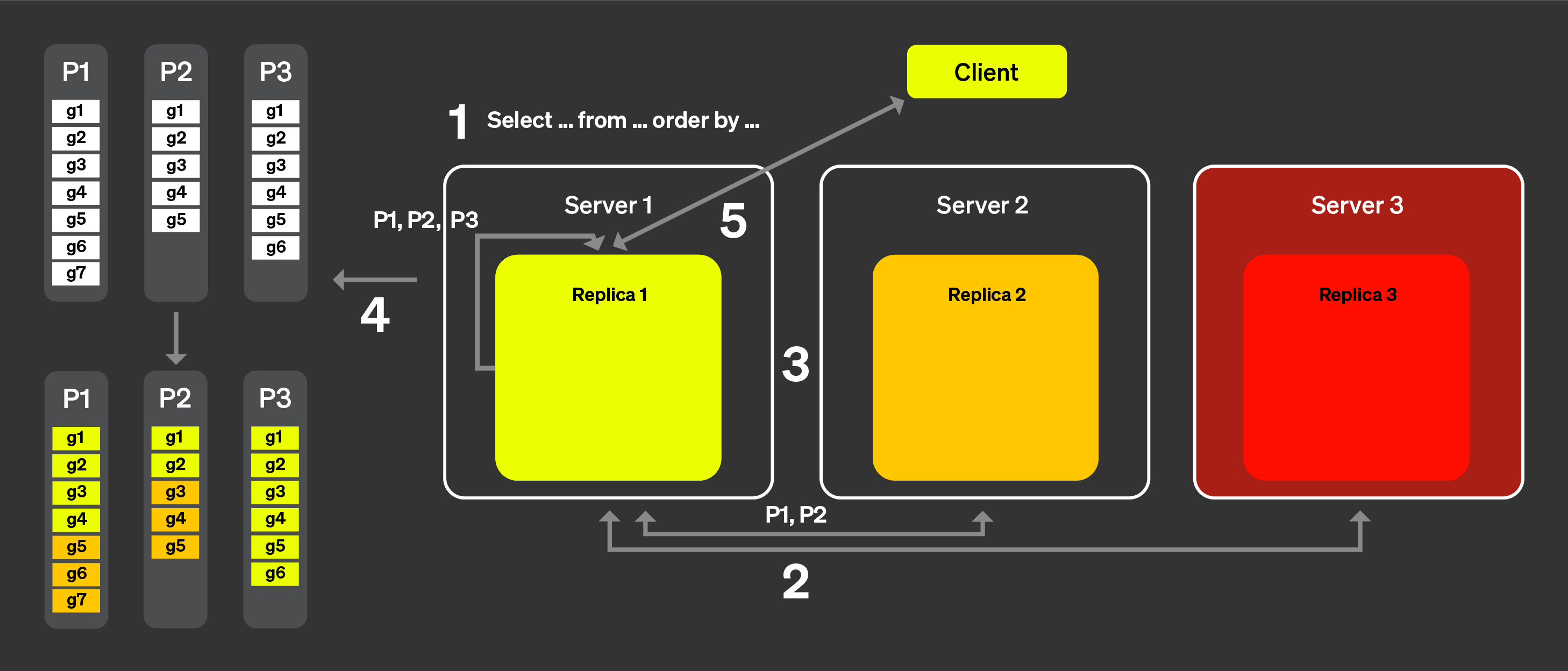
クライアントからのクエリはロードバランサーを経由して 1 つのノードに送信されます。このノードがこのクエリのコーディネーターになります。
コーディネーターノードは、クラスター内のすべてのレプリカからアナウンスメントを取得するリクエストを送信します。レプリカは、テーブルの現在のパーツ集合について、わずかに異なる見え方をしている場合があります。そのため、誤ったスケジューリング判断を避けるために、この情報を収集する必要があります。
その後、コーディネーターノードはアナウンスメントを使用して、異なるレプリカに割り当て可能なグラニュールの集合を定義します。たとえばここでは、レプリカ 2 は自分のアナウンスメントで part 3 を提示していないため、part 3 のグラニュールはレプリカ 2 には一切割り当てられていないことがわかります。また、レプリカ 3 はアナウンスメントを提供していないため、このレプリカにはタスクが割り当てられていない点にも注意してください。
各レプリカがそれぞれのグラニュールのサブセットに対してクエリ処理を行い、マージ可能な状態をコーディネーターに送り返した後、コーディネーターは結果をマージし、そのレスポンスをクライアントに送信します。
動的なコーディネーション
テールレイテンシの問題に対処するために、動的なコーディネーションを導入しました。これは、すべてのグラニュールを 1 回のリクエストでレプリカに送信するのではなく、各レプリカがコーディネータに対して新しいタスク (処理すべきグラニュールの集合) を要求できるようにする、ということを意味します。コーディネータは、受信したアナウンスに基づいて、そのレプリカに渡すグラニュールの集合を決定します。
すべてのレプリカが、すべてのパーツに関するアナウンスをすでに送信し終えている段階にあると仮定します。
以下の図は、動的なコーディネーションがどのように機能するかを示しています。
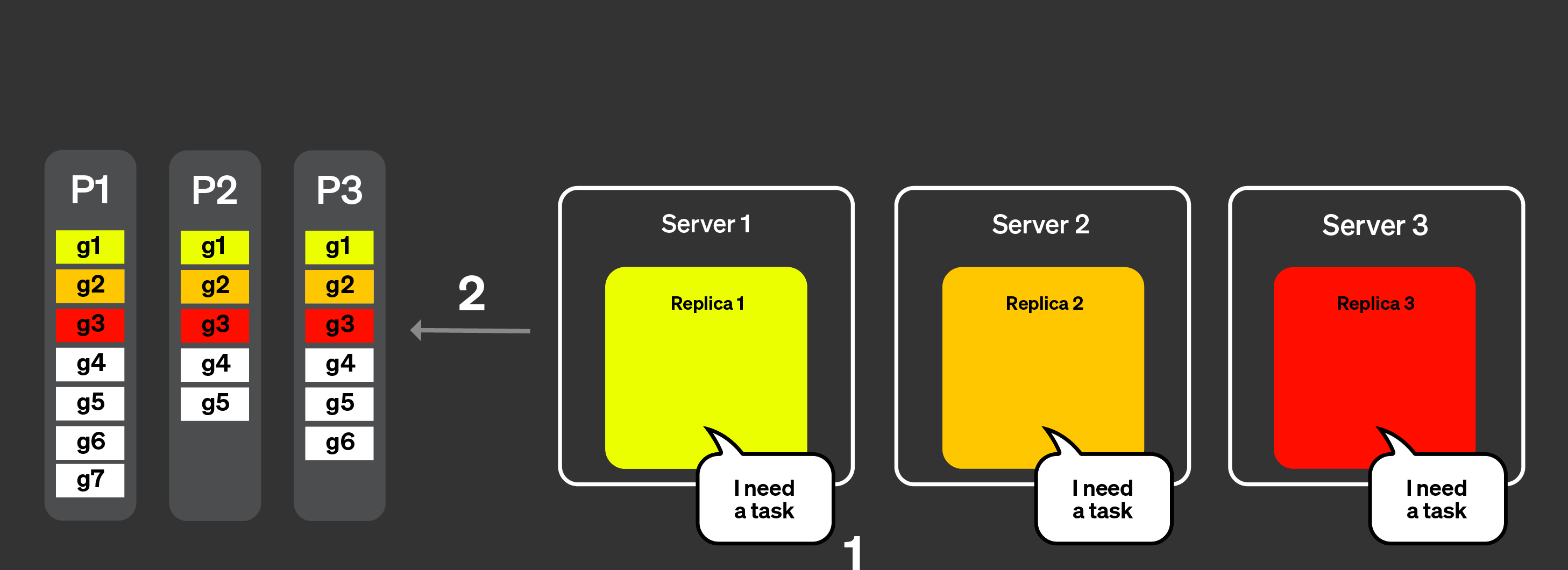
レプリカは、タスクを処理可能であること、またどの程度の作業量を処理可能かをコーディネータノードに通知します。
コーディネータは、レプリカにタスクを割り当てます。
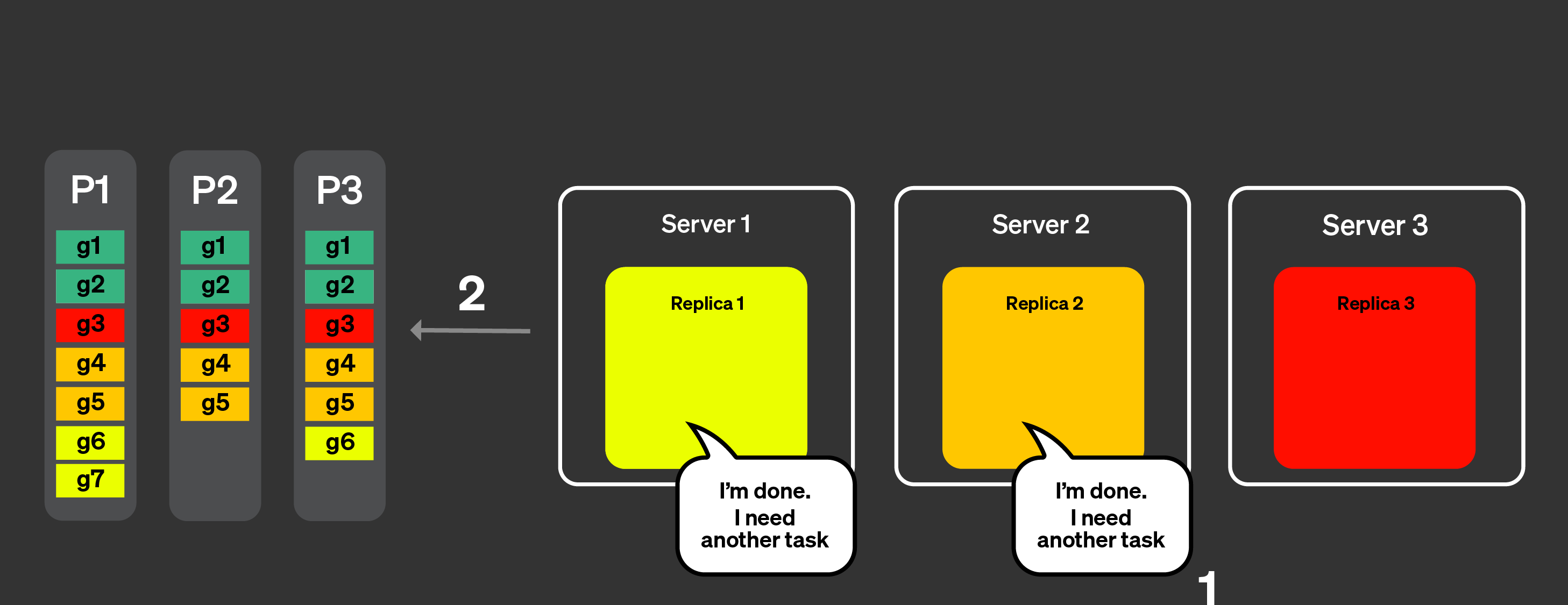
レプリカ 1 と 2 はタスクを非常に速く完了できます。そのため、コーディネータノードに別のタスクを要求します。
コーディネータは、新しいタスクをレプリカ 1 と 2 に割り当てます。
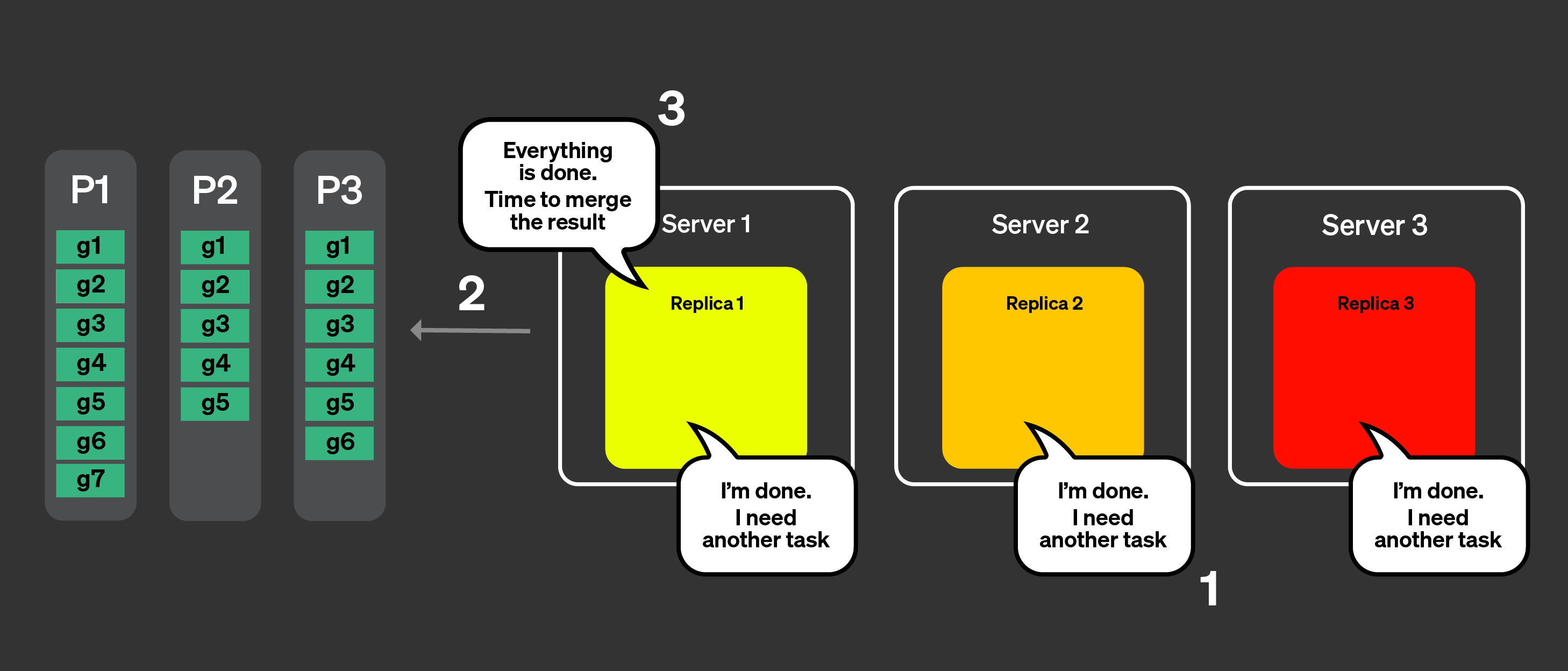
すべてのレプリカが、自身に割り当てられたタスクの処理を完了しました。そこで、さらにタスクを要求します。
コーディネータは、アナウンスを使って残っているタスクを確認しますが、もはや残りのタスクはありません。
コーディネータは、すべての処理が完了したことをレプリカに通知します。次に、マージ可能な状態をすべてマージし、クエリに応答します。
キャッシュローカリティの管理
最後に残る潜在的な問題は、キャッシュローカリティをどのように扱うかです。同じクエリが 複数回実行された場合、どのようにして同じタスクが同じレプリカにルーティングされるように 保証できるでしょうか。前の例では、次のようにタスクが割り当てられていました。
| レプリカ 1 | レプリカ 2 | レプリカ 3 | |
|---|---|---|---|
| パート 1 | g1, g6, g7 | g2, g4, g5 | g3 |
| パート 2 | g1 | g2, g4, g5 | g3 |
| パート 3 | g1, g6 | g2, g4, g5 | g3 |
同じタスクが同じレプリカに割り当てられ、キャッシュの恩恵を受けられるようにするために、 2 つのことが行われます。まず、パート + グラニュールの集合 (1 つのタスク) のハッシュが 計算されます。次に、タスク割り当てのためにレプリカ数に対するモジュロ演算が適用されます。
理論上はうまくいきそうですが、実際には、あるレプリカへの突発的な負荷や
ネットワーク品質の低下により、特定のタスクの実行に同じレプリカが継続的に使用されると、
テイルレイテンシが発生する可能性があります。max_parallel_replicas がレプリカ数より
小さい場合は、クエリ実行のためにレプリカがランダムに選択されます。
タスクスティーリング
あるレプリカが他のレプリカよりもタスクの処理が遅い場合、他のレプリカはテールレイテンシを低減するために、本来はハッシュに基づいてそのレプリカに割り当てられているタスクを「盗む」ことを試みます。
制約事項
この機能には既知の制約事項があり、その主なものを本セクションにまとめます。
以下で挙げている制約事項に当てはまらない問題を発見し、その原因が parallel replica であると疑われる場合は、GitHub で comp-parallel-replicas ラベルを付けて issue を作成してください。
| 制約事項 | 説明 |
|---|---|
| 複雑なクエリ | 現在、parallel replica は単純なクエリに対しては比較的良好に動作します。CTE、サブクエリ、JOIN、フラットでないクエリなどの複雑化要因は、クエリのパフォーマンスに悪影響を与える可能性があります。 |
| 小さいクエリ | 処理対象の行数が多くないクエリを実行している場合、複数のレプリカで実行してもパフォーマンス向上が得られないことがあります。これは、レプリカ間の調整に必要なネットワーク時間がクエリ実行に追加のオーバーヘッドをもたらす可能性があるためです。これらの問題は、設定 parallel_replicas_min_number_of_rows_per_replica を使用することで軽減できます。 |
| FINAL 使用時は parallel replicas が無効になる | |
| プロジェクションは parallel replicas と併用されない | |
| 高カーディナリティデータと複雑な集約 | 大量のデータ送信を伴う高カーディナリティの集約は、クエリを大幅に遅くする可能性があります。 |
| 新しいアナライザとの互換性 | 新しいアナライザは、特定のシナリオにおいてクエリ実行を大幅に遅くしたり速くしたりする可能性があります。 |
並列レプリカに関連する設定
| Setting | Description |
|---|---|
enable_parallel_replicas | 0: 無効1: 有効 2: 並列レプリカの使用を強制し、使用されない場合は例外をスローします。 |
cluster_for_parallel_replicas | 並列レプリケーションに使用するクラスタ名。ClickHouse Cloud を使用している場合は default を指定します。 |
max_parallel_replicas | 複数レプリカ上でクエリを実行する際に使用するレプリカの最大数。クラスタ内のレプリカ数より小さい値を指定した場合、ノードはランダムに選択されます。この値は水平方向のスケーリングを考慮してオーバーコミットとして設定することもできます。 |
parallel_replicas_min_number_of_rows_per_replica | 処理が必要な行数に基づいて使用するレプリカ数を制限するのに役立ちます。使用されるレプリカ数は次の式で決まります:estimated rows to read / min_number_of_rows_per_replica. |
enable_analyzer | 並列レプリカを用いたクエリ実行は、アナライザが有効化されている場合にのみサポートされます。 |
パラレルレプリカに関する問題の調査
各クエリでどの設定が使用されているかは、
system.query_log テーブルで確認できます。
また、サーバー上で発生したすべてのイベントは
system.events
テーブルで確認できます。さらに、
clusterAllReplicas テーブル関数を使用して、すべてのレプリカ上のテーブルを確認できます
(クラウドユーザーの場合は default を使用してください)。
レスポンス
system.text_log テーブルには、
並列レプリカを使用して実行されたクエリに関する情報も含まれています。
レスポンス
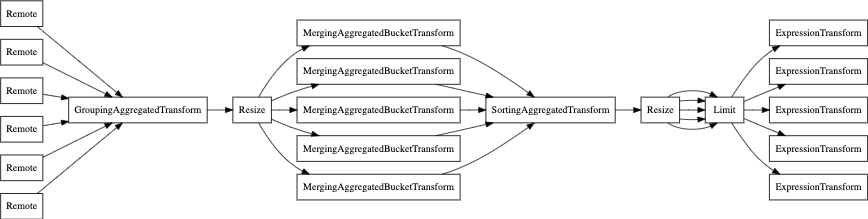
最後に、EXPLAIN PIPELINE も利用できます。これは、ClickHouse がクエリをどのように実行し、その実行にどのようなリソースを使用するかを示します。例として、次のクエリを見てみましょう。
並列レプリカなしの場合のクエリパイプラインを見てみましょう。

次は parallel_replica を使用した場合です: