SharedMergeTree テーブルエンジン
SharedMergeTree テーブルエンジンファミリーは、共有ストレージ (例: Amazon S3、Google Cloud Storage、MinIO、Azure Blob Storage) 上で動作するよう最適化された、クラウドネイティブな ReplicatedMergeTree エンジンの置き換えです。各 MergeTree エンジンタイプにはそれぞれ対応する SharedMergeTree があり、たとえば SharedReplacingMergeTree は ReplicatedReplacingMergeTree を置き換えます。
SharedMergeTree テーブルエンジンファミリーは ClickHouse Cloud を支えています。エンドユーザーにとっては、ReplicatedMergeTree ベースのエンジンの代わりに SharedMergeTree エンジンファミリーを使い始めるにあたって、何も変更する必要はありません。さらに、次のような利点があります:
- より高い挿入スループット
- バックグラウンドマージのスループット向上
- ミューテーションのスループット向上
- スケールアップおよびスケールダウン操作の高速化
- select クエリに対する、より軽量な強い一貫性
SharedMergeTree がもたらす大きな改善点の 1 つは、ReplicatedMergeTree と比べて、コンピュートとストレージをより深く分離していることです。以下では、ReplicatedMergeTree がどのようにコンピュートとストレージを分離しているかを確認できます:
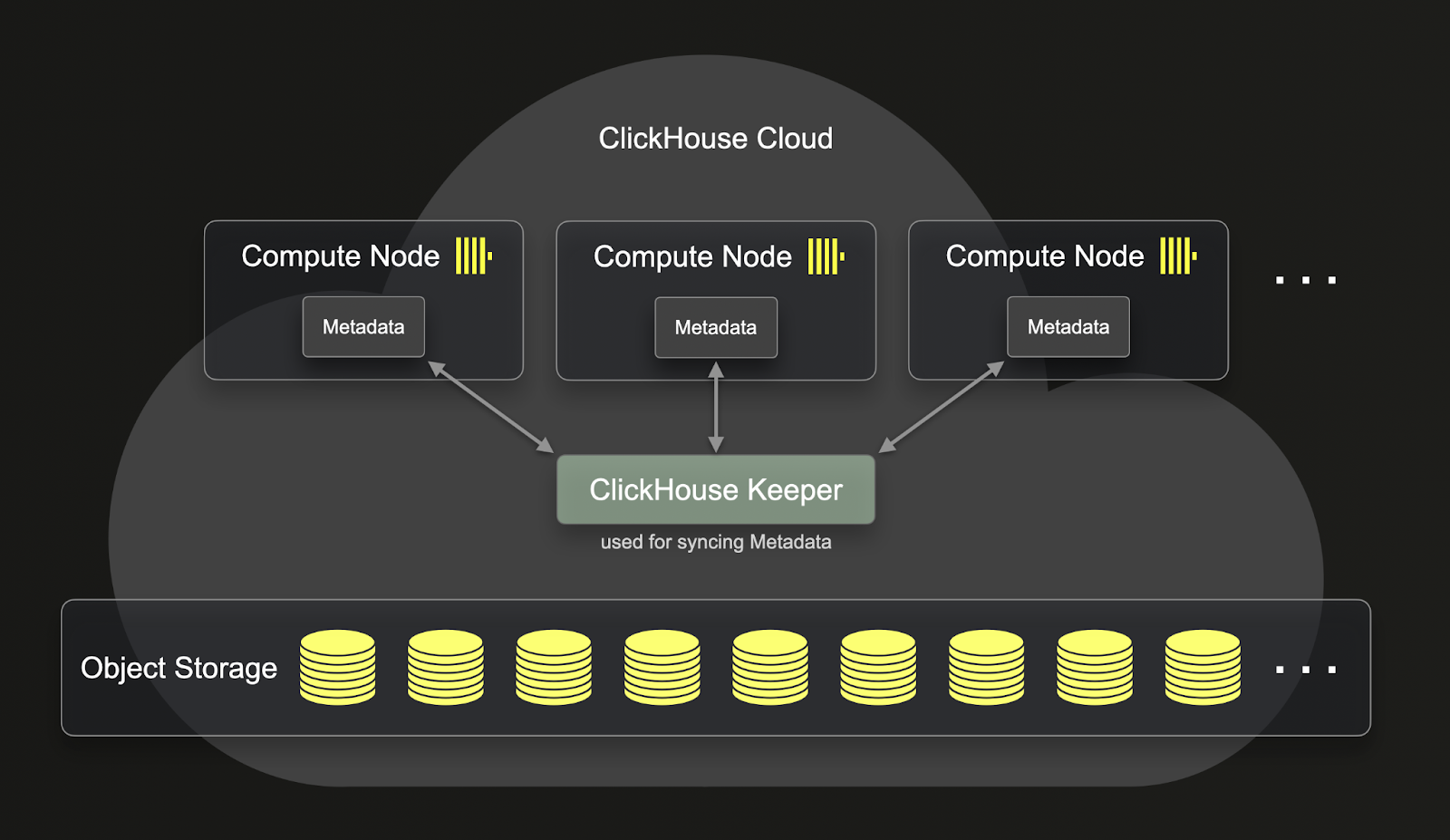
ご覧のとおり、ReplicatedMergeTree に保存されるデータはオブジェクトストレージ上にあるものの、メタデータは依然として各 clickhouse-server 上に存在しています。これは、レプリケートされるすべての操作において、メタデータもすべてのレプリカに複製する必要があることを意味します。
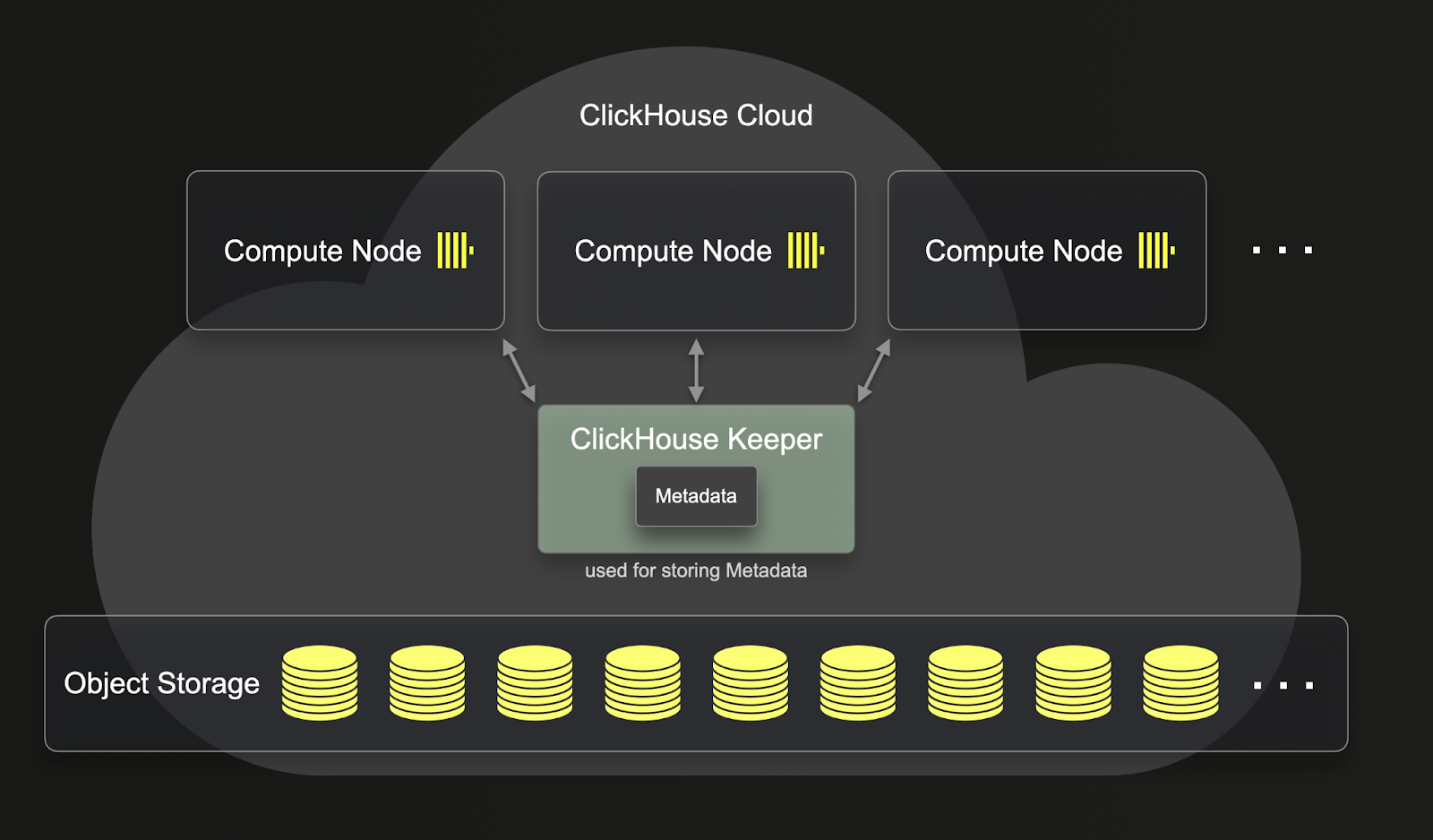
ReplicatedMergeTree とは異なり、SharedMergeTree ではレプリカ同士が相互に通信する必要はありません。代わりに、すべての通信は共有ストレージと clickhouse-keeper を通じて行われます。SharedMergeTree は非同期のリーダーレスレプリケーションを実装しており、調整とメタデータ保存のために clickhouse-keeper を使用します。つまり、サービスのスケールアップやスケールダウンに応じてメタデータを複製する必要がありません。その結果、レプリケーション、ミューテーション、マージ、スケールアップ操作がより高速になります。SharedMergeTree では各テーブルで数百のレプリカを利用できるため、シャードなしで動的にスケールすることが可能です。ClickHouse Cloud では、1 つのクエリにより多くのコンピュートリソースを活用するために、分散クエリ実行アプローチが使用されています。
内部情報の確認
ReplicatedMergeTree の内部情報確認に利用されるほとんどの system テーブルは SharedMergeTree にも存在しますが、データおよびメタデータのレプリケーションが行われないため、system.replication_queue と system.replicated_fetches は存在しません。ただし、SharedMergeTree にはこれら 2 つのテーブルに対応する代替テーブルが用意されています。
system.virtual_parts
このテーブルは、SharedMergeTree における system.replication_queue の代替として機能します。最新の現在のパーツ集合に関する情報に加え、マージやミューテーション、ドロップされたパーティションなど、進行中の処理で生成される将来のパーツに関する情報も保持します。
system.shared_merge_tree_fetches
このテーブルは、SharedMergeTree における system.replicated_fetches の代替です。プライマリキーおよびチェックサムをメモリにフェッチしている、進行中の取得処理に関する情報を保持します。
SharedMergeTree の有効化
SharedMergeTree はデフォルトで有効になっています。
SharedMergeTree テーブルエンジンをサポートするサービスでは、手動で何かを有効にする必要はありません。これまでと同じ方法でテーブルを作成すれば、CREATE TABLE クエリで指定したエンジンに対応する SharedMergeTree ベースのテーブルエンジンが自動的に使用されます。
これにより、SharedMergeTree テーブルエンジンを使用してテーブル my_table が作成されます。
ClickHouse Cloud では、default_table_engine=MergeTree が設定されているため、ENGINE=MergeTree を指定する必要はありません。次のクエリは上記のクエリと同じです。
Replacing、Collapsing、Aggregating、Summing、VersionedCollapsing、Graphite の各 MergeTree テーブルを使用している場合、それらは自動的に対応する SharedMergeTree ベースのテーブルエンジンに変換されます。
特定のテーブルについて、SHOW CREATE TABLE を実行して CREATE TABLE ステートメントを確認することで、どのテーブルエンジンが使用されているかを確認できます。
設定
一部の設定の挙動が大きく変更されています。
insert_quorum-- SharedMergeTree へのすべての挿入はクォーラム挿入(共有ストレージへの書き込み)となるため、SharedMergeTree テーブルエンジンを使用する場合、この設定は不要です。insert_quorum_parallel-- SharedMergeTree へのすべての挿入はクォーラム挿入(共有ストレージへの書き込み)となるため、SharedMergeTree テーブルエンジンを使用する場合、この設定は不要です。select_sequential_consistency-- クォーラム挿入を必要とせず、SELECTクエリ実行時に clickhouse-keeper への追加負荷を発生させます。
一貫性
SharedMergeTree は、ReplicatedMergeTree よりも軽量な一貫性モデルを提供します。SharedMergeTree に対して挿入を行う場合、insert_quorum や insert_quorum_parallel のような設定を指定する必要はありません。挿入はクォーラム挿入となり、メタデータは ClickHouse-Keeper に保存され、そのメタデータは少なくともクォーラムを満たす数の ClickHouse-Keeper ノードにレプリケートされます。クラスタ内の各レプリカは、ClickHouse-Keeper から新しい情報を非同期に取得します。
ほとんどの場合、select_sequential_consistency や SYSTEM SYNC REPLICA LIGHTWEIGHT を使用する必要はありません。非同期レプリケーションでほとんどのシナリオをカバーでき、レイテンシも非常に低く抑えられます。古いデータを読み取ってしまうことをどうしても防ぐ必要があるまれなケースでは、優先度順に次の推奨事項に従ってください。
-
同じセッション、または同じノードで読み取りと書き込みのクエリを実行している場合、
select_sequential_consistencyを使用する必要はありません。レプリカはすでに最新のメタデータを保持しているためです。 -
あるレプリカに書き込み、別のレプリカから読み取る場合は、
SYSTEM SYNC REPLICA LIGHTWEIGHTを使用して、そのレプリカに ClickHouse-Keeper からメタデータを取得させることができます。 -
クエリの設定として
select_sequential_consistencyを指定します。
