ClickHouse のシステムデータベースをクエリする
すべての ClickHouse インスタンスには、system データベース内に システムテーブル のセットが含まれており、次の情報を確認できます。
- サーバーの状態、プロセス、環境。
- サーバー内部のプロセス。
- ClickHouse バイナリのビルド時に使用されたオプション。
これらのテーブルを直接クエリすると、特に詳細な内部診断やデバッグを行う際に、ClickHouse デプロイメントの監視に役立ちます。
ClickHouse Cloud コンソールを使用する
ClickHouse Cloud コンソールには、システムテーブルのクエリに使用できる SQL コンソール と ダッシュボードツール が用意されています。たとえば、以下のクエリでは、過去 2 時間に新しいパーツがいくつ、またどのくらいの頻度で作成されたかを確認できます。
組み込みの高度なオブザーバビリティダッシュボード
ClickHouse には組み込みの高度なオブザーバビリティダッシュボード機能があり、system.dashboards に含まれる Cloud Overview metrics を表示するために $HOST:$PORT/dashboard からアクセスできます(ユーザー名とパスワードが必要です)。
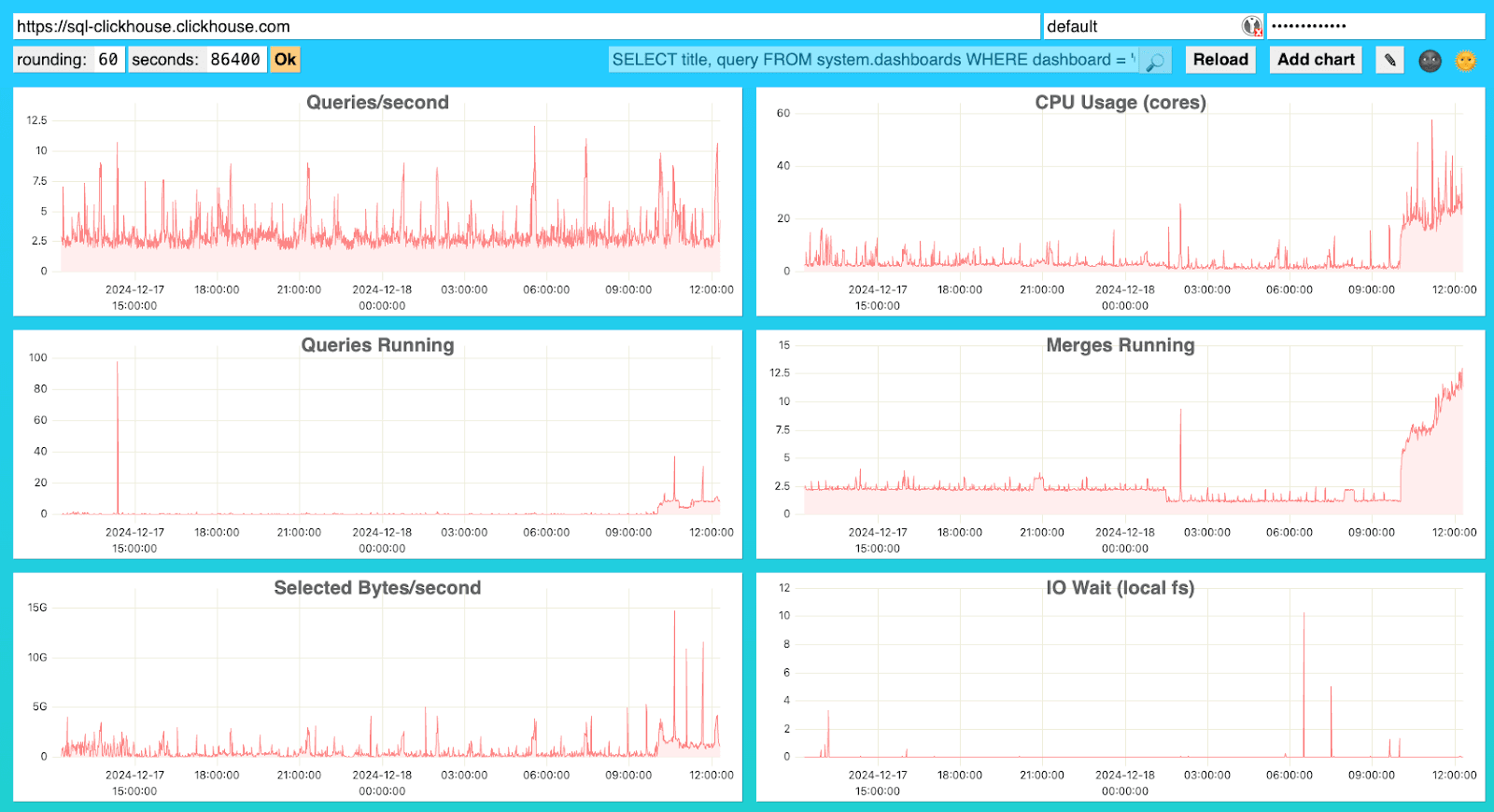
このダッシュボードでは ClickHouse インスタンスへの直接認証が必要であり、追加の認証なしで Cloud コンソール UI からアクセスできる Cloud Console Advanced Dashboard とは別のものです。
利用可能なビジュアライゼーションと、それらをトラブルシューティングに活用する方法の詳細については、高度なダッシュボードのドキュメント を参照してください。
ノードやバージョンをまたいだクエリ
クラスタ全体を包括的に把握するには、clusterAllReplicas 関数を merge 関数と組み合わせて使用します。clusterAllReplicas 関数を使用すると、"default" クラスタ内のすべてのレプリカにまたがってシステムテーブルをクエリでき、ノード固有のデータを単一の結果に集約できます。merge 関数と組み合わせることで、クラスタ内の特定のテーブルに対応するすべてのシステムデータを対象にできます。
たとえば、直近 1 時間で、すべてのレプリカにまたがって最も長時間実行されている上位 5 件のクエリを見つけるには:
このアプローチは、クラスタ全体にわたる運用のモニタリングとデバッグにおいて特に有用であり、ユーザーが ClickHouse Cloud のデプロイ環境の健全性とパフォーマンスを効果的に分析できるようにします。
詳細については、ノードをまたいだクエリを参照してください。
システム上の考慮事項
システムテーブルに直接クエリを実行すると、本番サービスにクエリ負荷がかかるほか、ClickHouse Cloud インスタンスがアイドル状態に移行できなくなり(コストに影響する可能性があります)、モニタリングの可用性が本番システムの健全性に依存することになります。本番システムに障害が発生した場合、モニタリングも影響を受ける可能性があります。
運用上の分離を保ちながら本番環境をリアルタイムでモニタリングするには、Prometheus-compatible metrics endpoint または Cloud Console dashboards の使用を検討してください。これらはいずれも事前にスクレイプされた metrics を使用し、基盤となるサービスに対してクエリを発行しません。
関連ページ
- System tables reference — 利用可能なすべてのシステムテーブルの完全なリファレンス
- Cloud Console monitoring — セットアップ不要で、サービスのパフォーマンスに影響しないダッシュボード
- Prometheus endpoint — metrics を外部のモニタリングツールにエクスポート
- Advanced dashboard — ダッシュボードのビジュアライゼーションに関する詳細なリファレンス
