ClickHouse Cloud の Cloud コンソールでの監視
ClickHouse Cloud のサービスには、ダッシュボードや通知を提供する、すぐに利用可能な監視機能が標準で備わっています。デフォルトでは、Cloud コンソールのすべてのユーザーがこれらのダッシュボードにアクセスできます。
ダッシュボード
サービスの健全性
Service Health ダッシュボードは、サービスの全体的な健全性を監視するために使用できます。このダッシュボードに表示されるメトリクスは、サービスがアイドル状態のときでも確認できるよう、ClickHouse Cloud がシステムテーブルから収集して保存しています。
リソース使用率
Infrastructure ダッシュボードでは、ClickHouse プロセスが使用しているリソースの詳細を確認できます。ClickHouse Cloud は、このダッシュボードに表示されるメトリクスをシステムテーブルからスクレイプして保存することで、サービスがアイドル状態のときでも表示できるようにしています。
メモリと CPU
Allocated CPU と Allocated Memory のグラフには、サービス内の各レプリカで利用可能なコンピュートリソースの合計が表示されます。これらの割り当ては、ClickHouse Cloud のスケーリング機能を使用して変更できます。
Memory Usage と CPU Usage のグラフは、各レプリカ内の ClickHouse プロセスによって実際に使用されている CPU とメモリの量を推定して表示します。これには、クエリに加えて、マージなどのバックグラウンドプロセスも含まれます。
メモリまたは CPU の使用率が割り当て済みのメモリまたは CPU に近づくと、パフォーマンスが低下し始める可能性があります。対処方法として、以下を推奨します。
- クエリを最適化する
- テーブルエンジンのパーティション設定を変更する
- スケーリングを使用して、サービスにコンピュートリソースを追加する
以下は、これらのグラフに表示される対応するシステムテーブルのメトリクスです。
| グラフ | 対応するメトリクス名 | 集計 | 注記 |
|---|---|---|---|
| 割り当て済みメモリ | CGroupMemoryTotal | 最大 | |
| 割り当て済み CPU | CGroupMaxCPU | 最大 | |
| 使用メモリ | MemoryResident | 最大 | |
| 使用 CPU | システム CPU メトリクス | 最大 | Prometheus エンドポイント 経由の ClickHouseServer_UsageCores |
データ転送
グラフには、ClickHouse Cloud とのデータの送受信が表示されます。詳細については、ネットワークデータ転送を参照してください。
高度なダッシュボード
このダッシュボードは、組み込みの高度なオブザーバビリティダッシュボード を改変したバージョンで、各系列がレプリカごとのメトリクスを表します。このダッシュボードは、ClickHouse 固有の問題のモニタリングやトラブルシューティングに役立ちます。
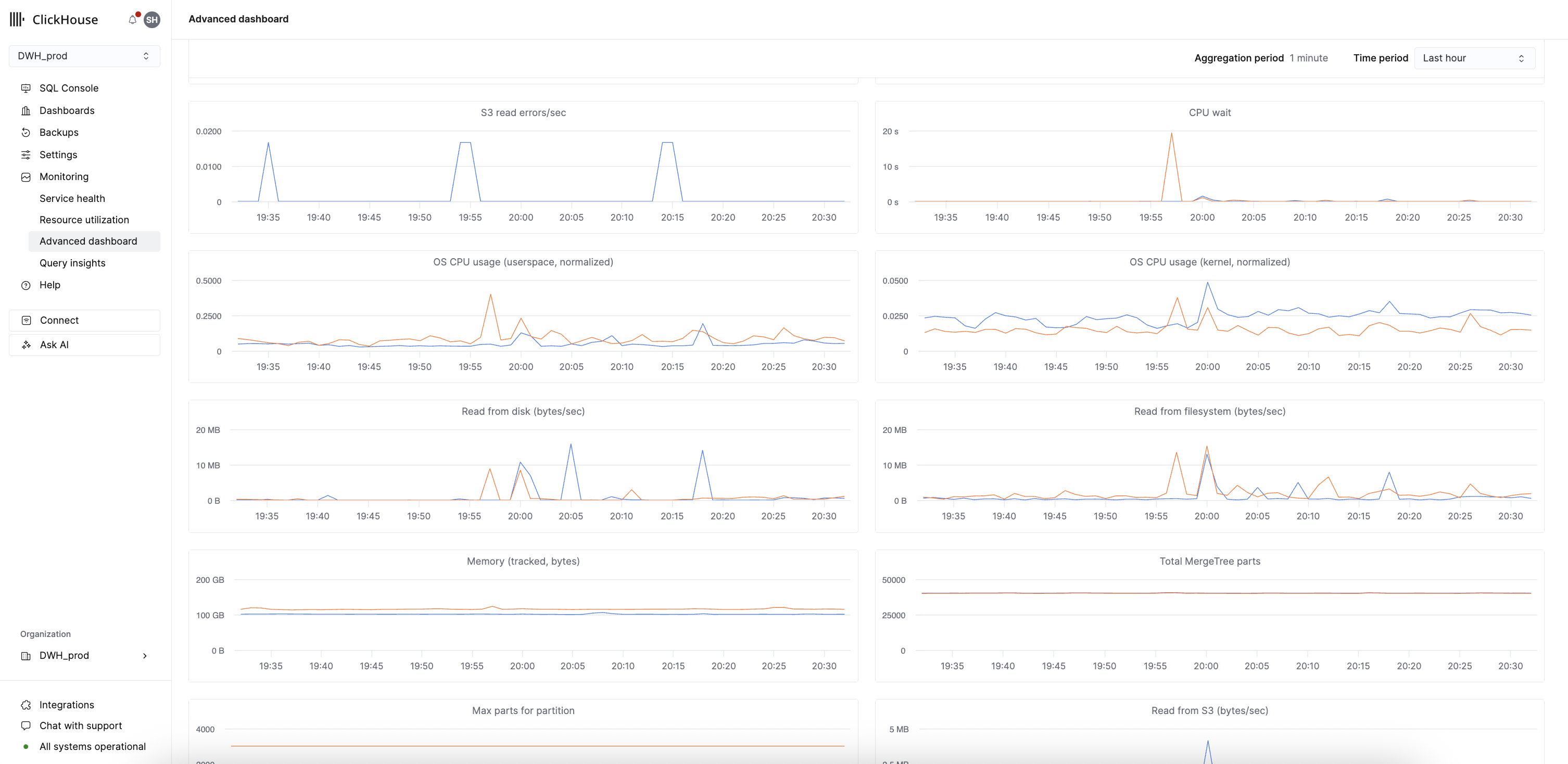
ClickHouse Cloud は、このダッシュボードに表示されるメトリクスをシステムテーブルからスクレイプして保存しているため、サービスがアイドル状態でも参照できます。これらのメトリクスにアクセスしても、基盤となるサービスに対してクエリは発行されず、アイドル状態のサービスが再開されることもありません。
以下のテーブルは、高度なダッシュボードの各グラフと、対応する ClickHouse メトリクス、システムテーブルのソース、および集計タイプの対応関係を示しています。
| グラフ | 対応する ClickHouse メトリクス名 | システムテーブル | 集計タイプ |
|---|---|---|---|
| クエリ数/秒 | ProfileEvent_Query | metric_log | Sum / bucketSizeSeconds |
| 実行中のクエリ | CurrentMetric_Query | metric_log | Avg |
| 実行中のマージ | CurrentMetric_Merge | metric_log | Avg |
| 選択バイト数/秒 | ProfileEvent_SelectedBytes | metric_log | Sum / bucketSizeSeconds |
| I/O 待機 | ProfileEvent_OSIOWaitMicroseconds | metric_log | Sum / bucketSizeSeconds |
| S3 読み取り待機 | ProfileEvent_ReadBufferFromS3Microseconds | metric_log | Sum / bucketSizeSeconds |
| S3 読み取りエラー数/秒 | ProfileEvent_ReadBufferFromS3RequestsErrors | metric_log | Sum / bucketSizeSeconds |
| CPU 待機 | ProfileEvent_OSCPUWaitMicroseconds | metric_log | Sum / bucketSizeSeconds |
| OS CPU 使用率 (ユーザー空間、正規化済み) | OSUserTimeNormalized | asynchronous_metric_log | |
| OS CPU 使用率 (カーネル、正規化済み) | OSSystemTimeNormalized | asynchronous_metric_log | |
| ディスクからの読み取り | ProfileEvent_OSReadBytes | metric_log | Sum / bucketSizeSeconds |
| ファイルシステムからの読み取り | ProfileEvent_OSReadChars | metric_log | Sum / bucketSizeSeconds |
| メモリ (追跡対象、バイト) | CurrentMetric_MemoryTracking | metric_log | |
| MergeTree パーツ総数 | TotalPartsOfMergeTreeTables | asynchronous_metric_log | |
| パーティションあたりの最大パーツ数 | MaxPartCountForPartition | asynchronous_metric_log | |
| S3 からの読み取り | ProfileEvent_ReadBufferFromS3Bytes | metric_log | Sum / bucketSizeSeconds |
| ファイルシステムキャッシュサイズ | CurrentMetric_FilesystemCacheSize | metric_log | |
| Disk S3 書き込みリクエスト数/秒 | ProfileEvent_DiskS3PutObject + ProfileEvent_DiskS3UploadPart + ProfileEvent_DiskS3CreateMultipartUpload + ProfileEvent_DiskS3CompleteMultipartUpload | metric_log | Sum / bucketSizeSeconds |
| Disk S3 読み取りリクエスト数/秒 | ProfileEvent_DiskS3GetObject + ProfileEvent_DiskS3HeadObject + ProfileEvent_DiskS3ListObjects | metric_log | Sum / bucketSizeSeconds |
| FS キャッシュヒット率 | sum(ProfileEvent_CachedReadBufferReadFromCacheBytes) / (sum(ProfileEvent_CachedReadBufferReadFromCacheBytes) + sum(ProfileEvent_CachedReadBufferReadFromSourceBytes)) | metric_log | |
| ページキャッシュヒット率 | greatest(0, (sum(ProfileEvent_OSReadChars) - sum(ProfileEvent_OSReadBytes)) / (sum(ProfileEvent_OSReadChars) + sum(ProfileEvent_ReadBufferFromS3Bytes))) | metric_log | |
| ネットワーク受信バイト数/秒 | NetworkReceiveBytes | asynchronous_metric_log | Sum / bucketSizeSeconds |
| ネットワーク送信バイト数/秒 | NetworkSendBytes | asynchronous_metric_log | Sum / bucketSizeSeconds |
| 同時 TCP 接続数 | CurrentMetric_TCPConnection | metric_log | |
| 同時 MySQL 接続数 | CurrentMetric_MySQLConnection | metric_log | |
| 同時 HTTP 接続数 | CurrentMetric_HTTPConnection | metric_log |
各ビジュアライゼーションの詳細と、それらをトラブルシューティングに活用する方法については、高度なダッシュボードのドキュメント を参照してください。
クエリインサイト
クエリインサイト 機能を使うと、ClickHouse に組み込まれたクエリログを、さまざまなビジュアライゼーションやテーブルを通じてより簡単に活用できます。ClickHouse の system.query_log テーブルは、クエリの最適化、デバッグ、そしてクラスタ全体の健全性とパフォーマンスのモニタリングにおける重要な情報源です。
サービスを選択すると、左側のサイドバーにある Monitoring ナビゲーション項目が展開され、クエリインサイト サブ項目が表示されます。
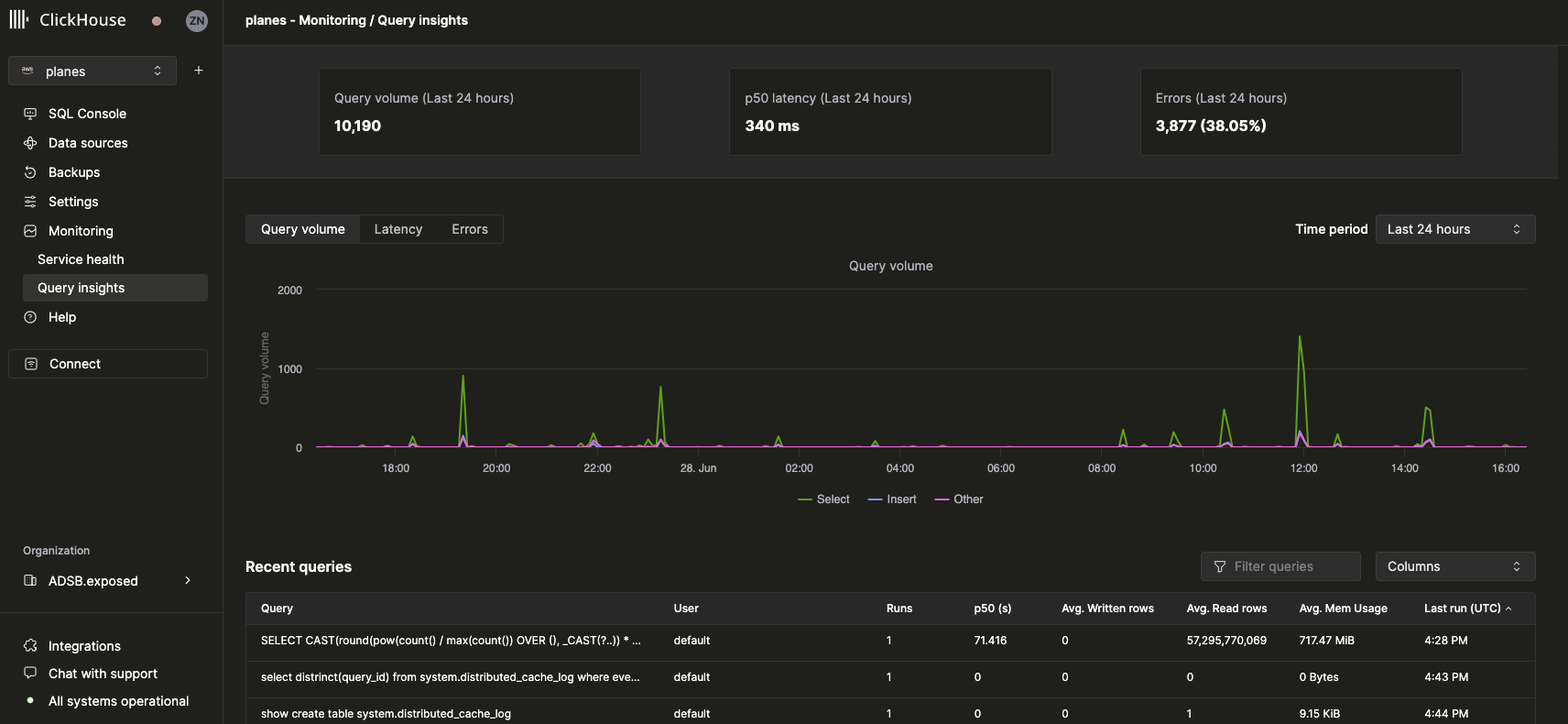
トップレベルのメトリクス
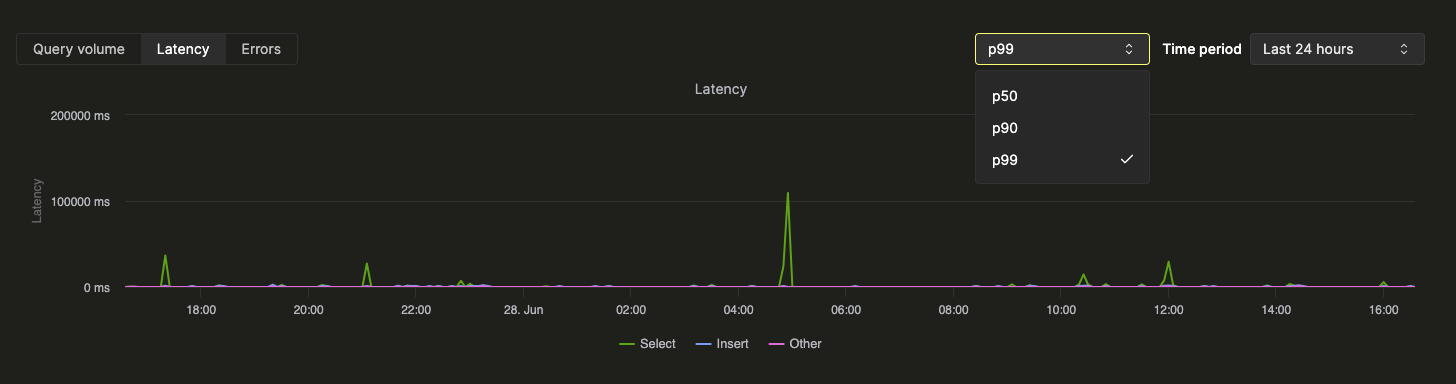
上部の統計ボックスには、選択した期間における基本的なクエリメトリクスが表示されます。その下の時系列チャートには、クエリ数、レイテンシ、エラー率がクエリ種別 (select、insert、other) 別に表示されます。レイテンシのチャートは、p50、p90、p99 のレイテンシを表示するように切り替えられます。
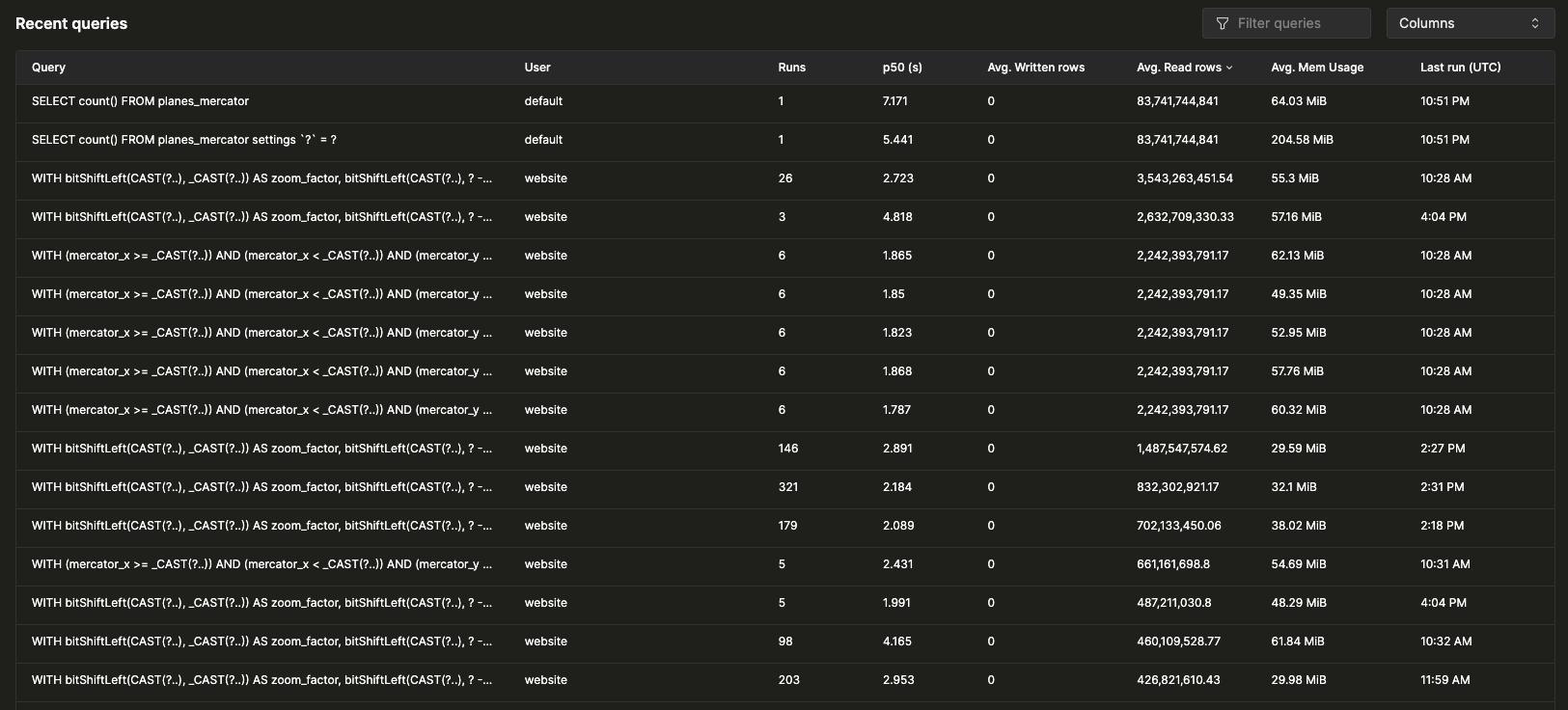
最近のクエリ
テーブルには、選択した時間範囲におけるクエリログエントリが、正規化されたクエリハッシュとユーザーごとにグループ化されて表示されます。最近のクエリは、利用可能な任意のフィールドでフィルタリングや並べ替えが可能です。また、テーブルではテーブル、p90、p99 レイテンシなどの追加フィールドの表示/非表示を設定できます。
クエリのドリルダウン
最近のクエリテーブルからクエリを選択すると、選択したクエリに固有のメトリクスや情報を含むフライアウトが開きます。
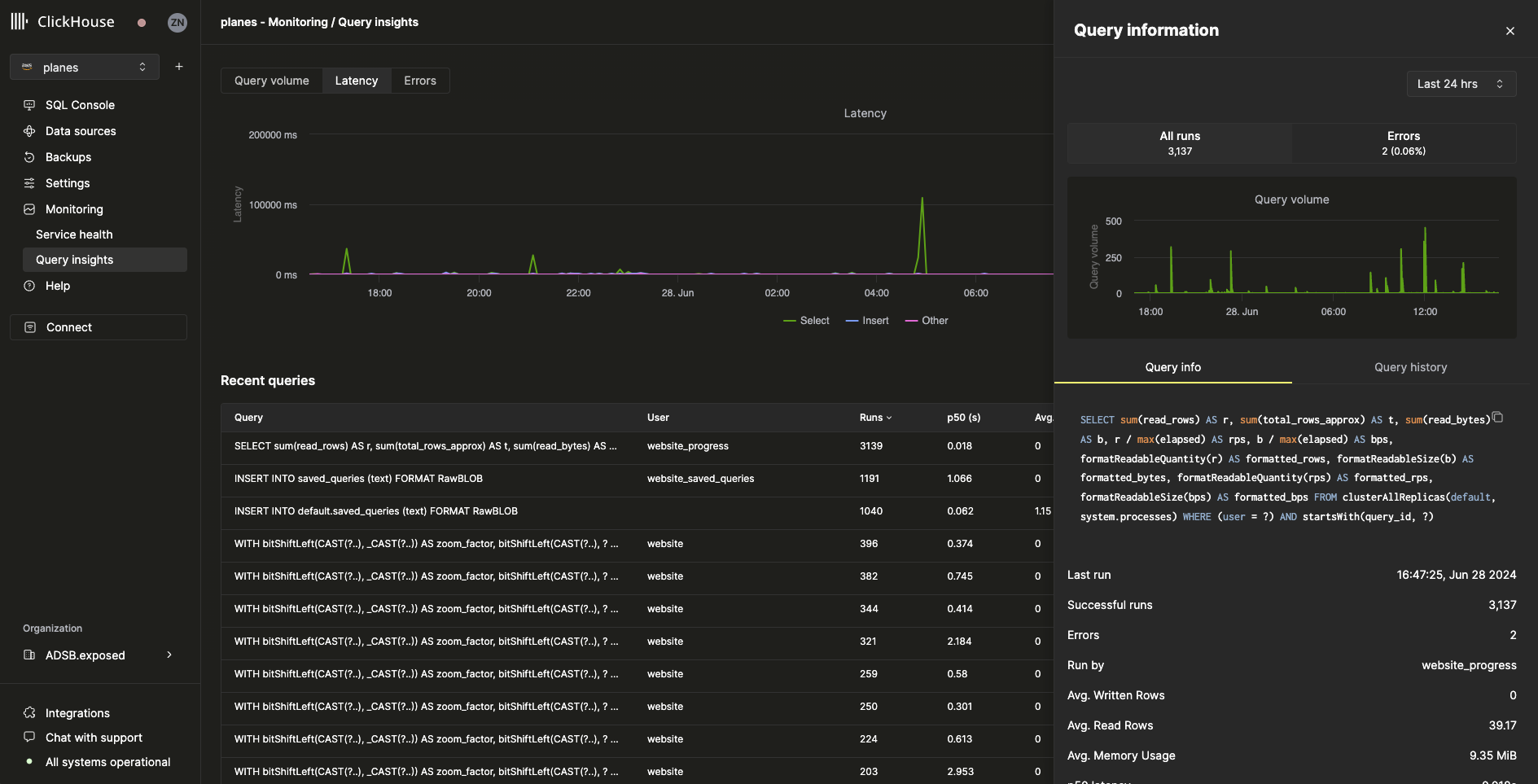
Query info タブ内のすべてのメトリクスは集計されたメトリクスですが、Query history タブを選択すると、個々の実行のメトリクスも確認できます。
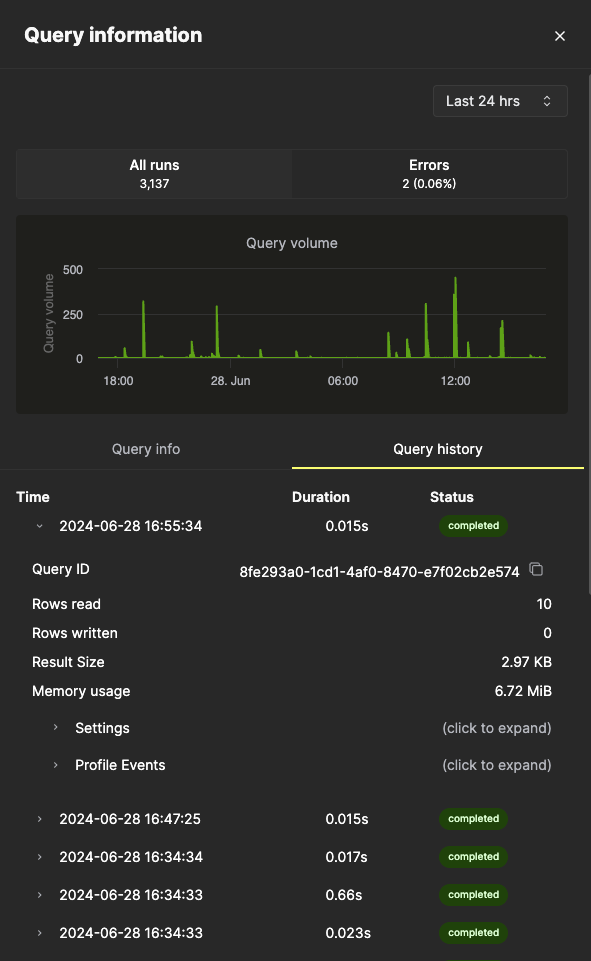
このペインでは、各クエリ実行の Settings および Profile Events 項目を展開して、追加情報を表示できます。
関連ページ
- Notifications — スケーリングイベント、エラー、請求に関するアラートを設定
- Advanced dashboard — 各ダッシュボードのビジュアライゼーションに関する詳細なリファレンス
- Querying system tables — 詳細な内部分析のために、システムテーブルに対してカスタム SQL クエリを実行
- Prometheus endpoint — メトリクスを Grafana、Datadog、またはその他の Prometheus 互換ツールにエクスポート
