スケーリング
Managed Postgres は、ワークロード要件に合わせて柔軟なスケーリングオプションを提供します。50 以上の NVMe 搭載インスタンスタイプから選択でき、CPU、メモリ、ストレージをそれぞれ独立してスケールすることで、特定のユースケースに合わせてパフォーマンスとコストを最適化できます。
インスタンスタイプと柔軟性
Managed Postgres では、さまざまなワークロード特性に最適化された、幅広いインスタンスタイプを利用できます。
- コンピュート、メモリ、ストレージ最適化構成を含む 50 種類以上のインスタンスタイプ
- すべてのインスタンスタイプで一貫した高パフォーマンスなディスク I/O を実現する NVMe ベースのストレージ
- リソースを個別にスケーリング可能:ワークロードに応じて CPU、メモリ、ストレージの最適なバランスを選択可能
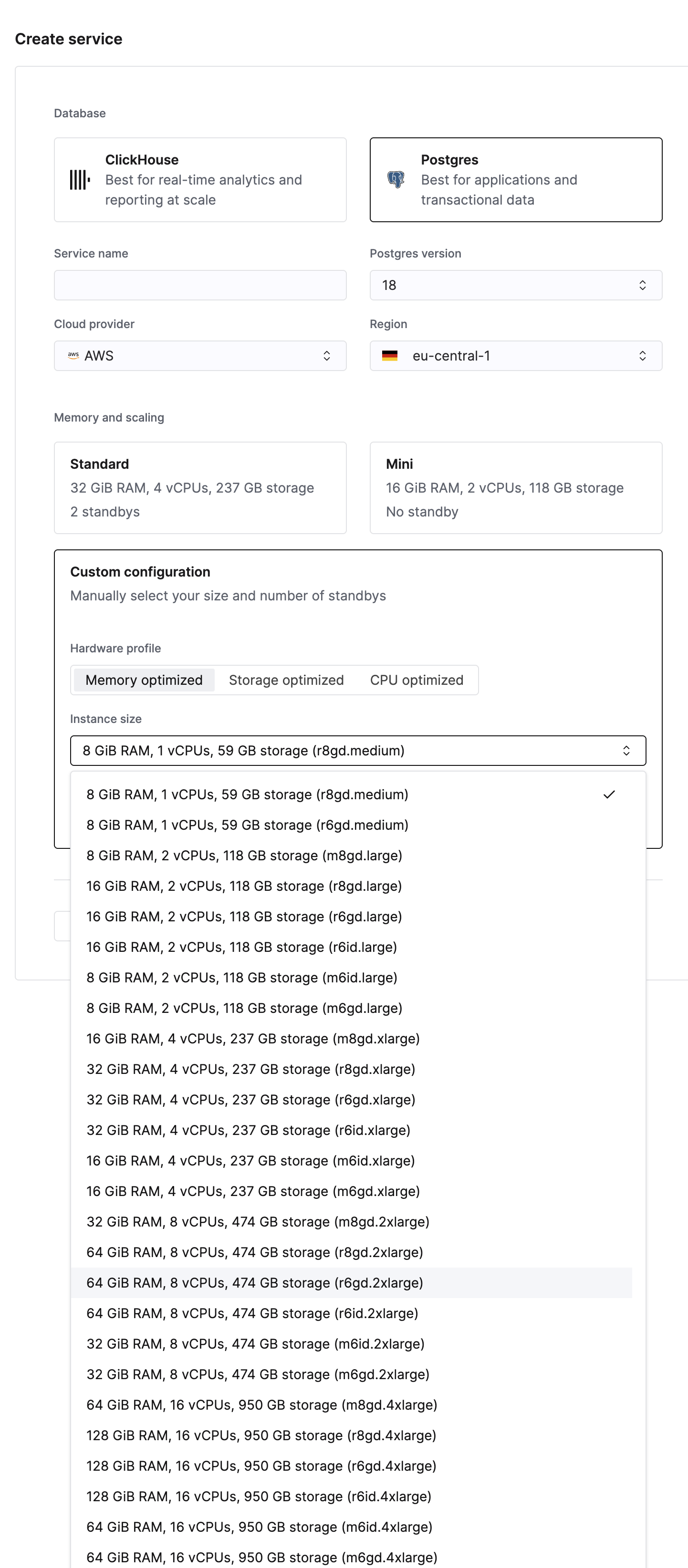
適切なインスタンスタイプの選択
ワークロードによって適したリソース構成は異なります。
| ワークロードの種類 | CPU | メモリ | ストレージ | 推奨インスタンス |
|---|---|---|---|---|
| コンピュート最適化 | 高 | 中 | 中 | コンピュート最適化 (高い vCPU 数) |
| メモリ最適化 (大きなワーキングセット) | 中 | 高 | 中 | メモリ最適化 (高いメモリ対CPU比) |
| ストレージ最適化 (大規模データセット・大量 I/O) | 中 | 中 | 高 | ストレージ最適化 (高い NVMe 容量) |
安全上の理由から、現在使用しているストレージ容量に近いストレージ容量のインスタンスタイプには切り替えられない場合があります。問題を避けるため、現在の使用容量に対して十分な余裕のあるインスタンスタイプを常に選択してください。
スケーリングの仕組み
インスタンスタイプを変更すると、Managed Postgresは垂直スケーリングを実行し、新しいインフラストラクチャをプロビジョニングして、ダウンタイムを最小限に抑えながらデータベースを移行します。
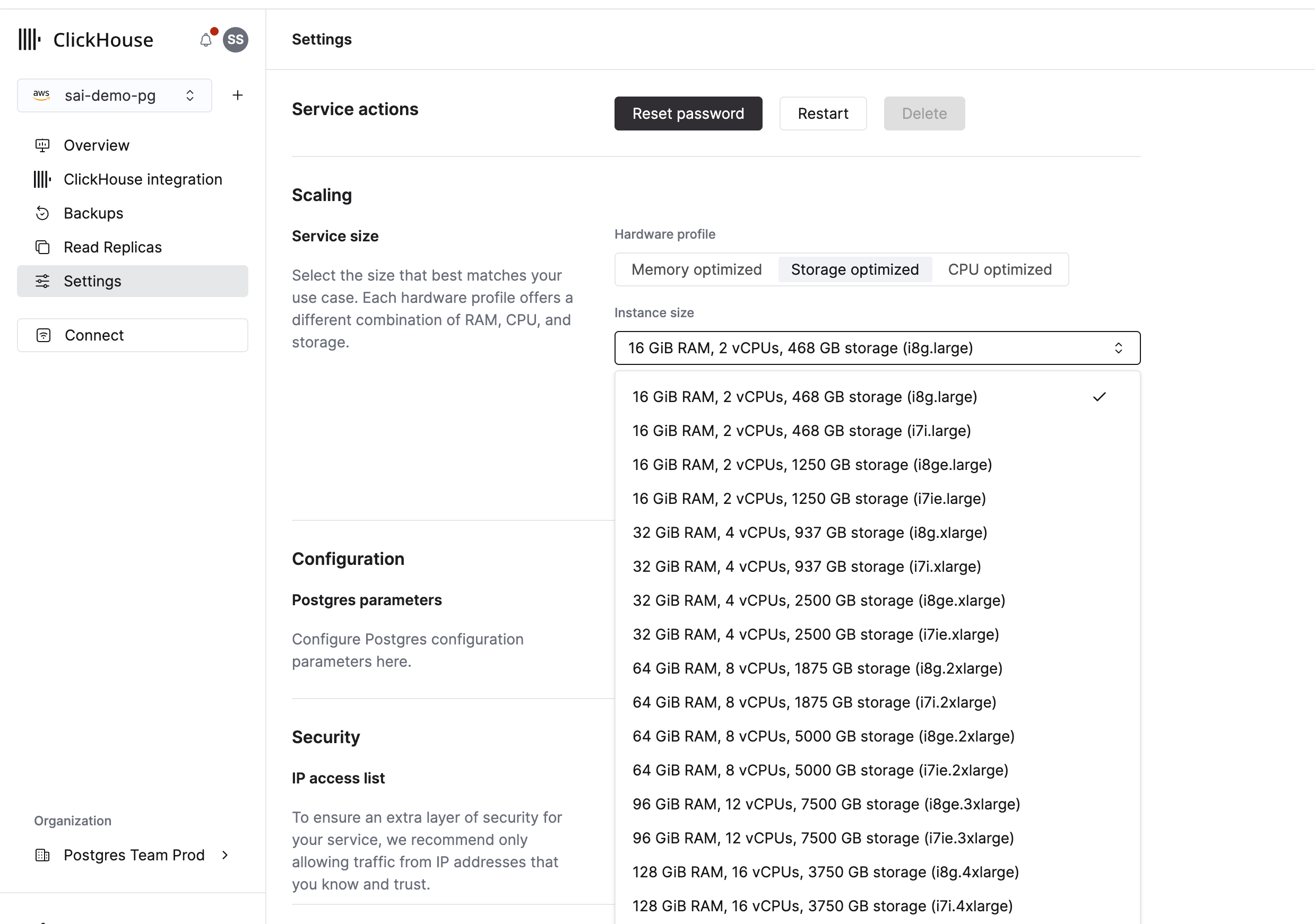
スケーリングプロセス
スケーリングのワークフローでは、バックアップから新しいスタンバイを起動し、制御されたフェイルオーバーを実行します。
-
スタンバイのプロビジョニング: 目的のインスタンスタイプ(CPU、メモリ、ストレージ構成)で新しいスタンバイインスタンスを作成します
-
S3 バックアップからのリストア: S3 に保存された最新のバックアップからリストアすることで、スタンバイを初期化します
-
並列 WAL リプレイ: スタンバイは、WAL-G による並列リストア機構を用いて、バックアップ以降のすべての Write-Ahead Log (WAL) の変更を適用します
- WAL-G により、高速かつ並列化されたリストア処理が可能になります
- WAL-G の作者は、当社が提携している Ubicloud チームに所属しており、高度な専門知識と最適化が担保されています
-
レプリケーションの追従: スタンバイは、WAL の継続的な変更をストリーミングして適用することで、プライマリに追いつきます
-
フェイルオーバー: スタンバイが完全に同期されたら、制御されたフェイルオーバーによりスタンバイが新しいプライマリに昇格します
- ダウンタイムが発生するのはこのステップのみです(約 30 秒)
- フェイルオーバー中は、すべてのアクティブな接続が中断されます
- クライアントはフェイルオーバー完了後に再接続する必要があります
-
旧インスタンスの廃止: フェイルオーバー完了後、元のインスタンスは廃止されます
スケーリングにかかる時間
スケーリングに必要な合計時間は、主にデータベースのサイズと、バックアップからリプレイする必要がある WAL データ量によって決まります。
- バックアップリストア: 最新のフルバックアップを S3 から新しいインスタンスへリストアする時間
- WAL リプレイ: 直近のフルバックアップ以降の増分 WAL 変更をリプレイする時間
- 並列リストア: WAL-G の並列リストア機構は処理を大幅に高速化します
リストア時間は数分から数時間まで変動しますが、メンテナンス時間/ダウンタイムは非常に短く(約 30 秒のみ)抑えられます。
フェイルオーバー中、アプリケーションは約 30 秒のダウンタイムが発生しますが、これは全体のスケーリング処理時間に関係なく一定です。リストアおよび差分の追いつき処理はすべて、スタンバイインスタンス上でバックグラウンド実行されます。
WAL-G を用いた並列リストア
Managed Postgres では、スケーリング処理中のバックアップのリストアを高速化するために WAL-G を利用しています。特筆すべき点として、WAL-G の開発者は Ubicloud チームの一員であり、当社は同チームと提携することで、リストア処理に関する高度な専門知識を取り込んでいます。
WAL-G は次の機能を提供します:
- 並列ダウンロードおよび解凍: 複数のバックアップセグメントを S3 から取得し、同時に解凍します
- 効率的な WAL リプレイ: 可能な箇所では増分 WAL 変更を並列に適用します
- 最適化されたストリーミング: 中間コピーを行わずに S3 ストレージから直接ストリーミングします
- 高速なリストア: 総所要時間はデータサイズに依存しますが、並列化されたアプローチにより処理を非常に高速に行えます
これらの最適化により、新しいスタンバイインスタンスの立ち上げに必要な時間が大幅に短縮されます。さらに重要なのは、リストア処理が完全にバックグラウンドで実行される点であり、アプリケーションが経験するダウンタイムは、およそ 30 秒程度の短いフェイルオーバー時間のみとなることです。
スケーリング操作の開始
Managed Postgres インスタンスをスケールするには、次の手順を実行します。
- インスタンスの Settings タブに移動します
- Scaling セクションで Service size までスクロールします
- 対象のインスタンスタイプを選択します
- 変更内容を確認し、「Apply changes」をクリックします
スケーリング戦略
垂直スケーリング
垂直スケーリング(インスタンスタイプの変更)は、Managed Postgres におけるリソース調整の主要な手段です。このアプローチにより、次のことが可能になります。
- きめ細かな制御: 50種類以上のインスタンスタイプから選択し、CPU・メモリ・ストレージを細かく調整
- ワークロード最適化: 特定のワークロード(コンピュート集約型、メモリ集約型、ストレージ集約型)に最適化された構成を選択
- コスト効率: 過剰なプロビジョニングを行わず、必要なリソース分に対してのみ支払う
水平スケーリングのためのリードレプリカ
読み取り負荷の高いワークロードでは、読み取りキャパシティを水平方向にスケールするために read replicas の利用を検討してください。
- 読み取りクエリを専用のリードレプリカインスタンスにオフロードします
- 各リードレプリカは、それぞれ専用のコンピュートリソースとメモリを持つ、完全に独立した Postgres インスタンスです
- リードレプリカは、効率的なレプリケーションのために、オブジェクトストレージから WAL の変更をストリーミングします
このアプローチは、レポートダッシュボード、分析クエリ、読み取り負荷の高い API エンドポイントなど、読み取り比率が高いアプリケーションに最適です。
ClickHouse 連携向け CDC のスケーリング
ClickPipes を使用して ClickHouse にデータをレプリケートしている場合、CDC(変更データキャプチャ)パイプラインを個別にスケールできます。
- CDC ワーカーを 1〜24 CPU コアの範囲でスケール
- メモリは CPU コア数の 4 倍まで自動的にスケール
- スケーリングの調整は ClickPipes OpenAPI 経由で実施
これにより、Postgres インスタンスのリソースとは独立してレプリケーションのスループットを最適化できます。
オートスケーリング
ディスク使用率が90%に達すると、インスタンスタイプはより大きなものに自動的に変更されます。
