データウェアハウジング
現代のデータウェアハウスでは、もはやストレージとコンピュートが密結合されていません。代わりに、ストレージ、ガバナンス、クエリ処理を担う、分離されつつ相互接続されたレイヤーによって、ワークフローに適したツールを柔軟に選択できます。
Cloud のオブジェクトストレージに、オープンなテーブル形式と ClickHouse のような高パフォーマンスのクエリエンジンを組み合わせることで、データレイクのオープン性を損なうことなく、データベース級の機能 — ACID 取引、スキーマの強制、そして高速な分析クエリ — を実現できます。この組み合わせにより、パフォーマンスと、相互運用性があり費用対効果の高いストレージを両立させ、従来の分析ワークロードから最新の AI/ML ワークロードまでサポートできます。
このアーキテクチャが提供するもの
オープンなオブジェクトストレージとテーブル形式を、ClickHouseをクエリエンジンとして組み合わせることで、次の利点が得られます。
| Benefit | Description |
|---|---|
| 一貫したテーブル更新 | テーブル状態へのアトミックコミットにより、同時書き込みでもデータの破損や部分的なデータの発生を防げます。これにより、生のデータレイクにおける最大の問題の1つを解決できます。 |
| スキーマ管理 | 検証の強制とスキーマ進化の追跡により、スキーマの不整合が原因でデータが使えなくなる「データスワンプ」の問題を防げます。 |
| クエリパフォーマンス | インデックス、統計情報、さらにデータスキッピングやクラスタリングなどのデータレイアウト最適化により、SQLクエリを専用データウェアハウスに匹敵する速度で実行できます。ClickHouseの列指向エンジンと組み合わせることで、これはオブジェクトストレージに保存されたデータでも当てはまります。 |
| ガバナンス | カタログとテーブル形式により、行レベルおよび列レベルでのきめ細かなアクセス制御と監査が可能になり、基本的なデータレイクで不足しがちなセキュリティ制御に対処できます。 |
| ストレージとコンピュートの分離 | ストレージとコンピュートは、プロプライエタリなウェアハウスストレージより大幅に低コストな汎用オブジェクトストレージ上で、それぞれ独立してスケールできます。この分離は最新のクラウドウェアハウスでは一般的ですが、オープン形式を使えば、データに合わせてどのコンピュートエンジンをスケールさせるかを選択できます。 |
ClickHouseがデータウェアハウスを支える仕組み
データは、ストリーミングプラットフォームや既存のウェアハウスからオブジェクトストレージを経由して ClickHouse に流れ込み、そこで変換・最適化されたうえで、BI/AI ツールに提供されます。
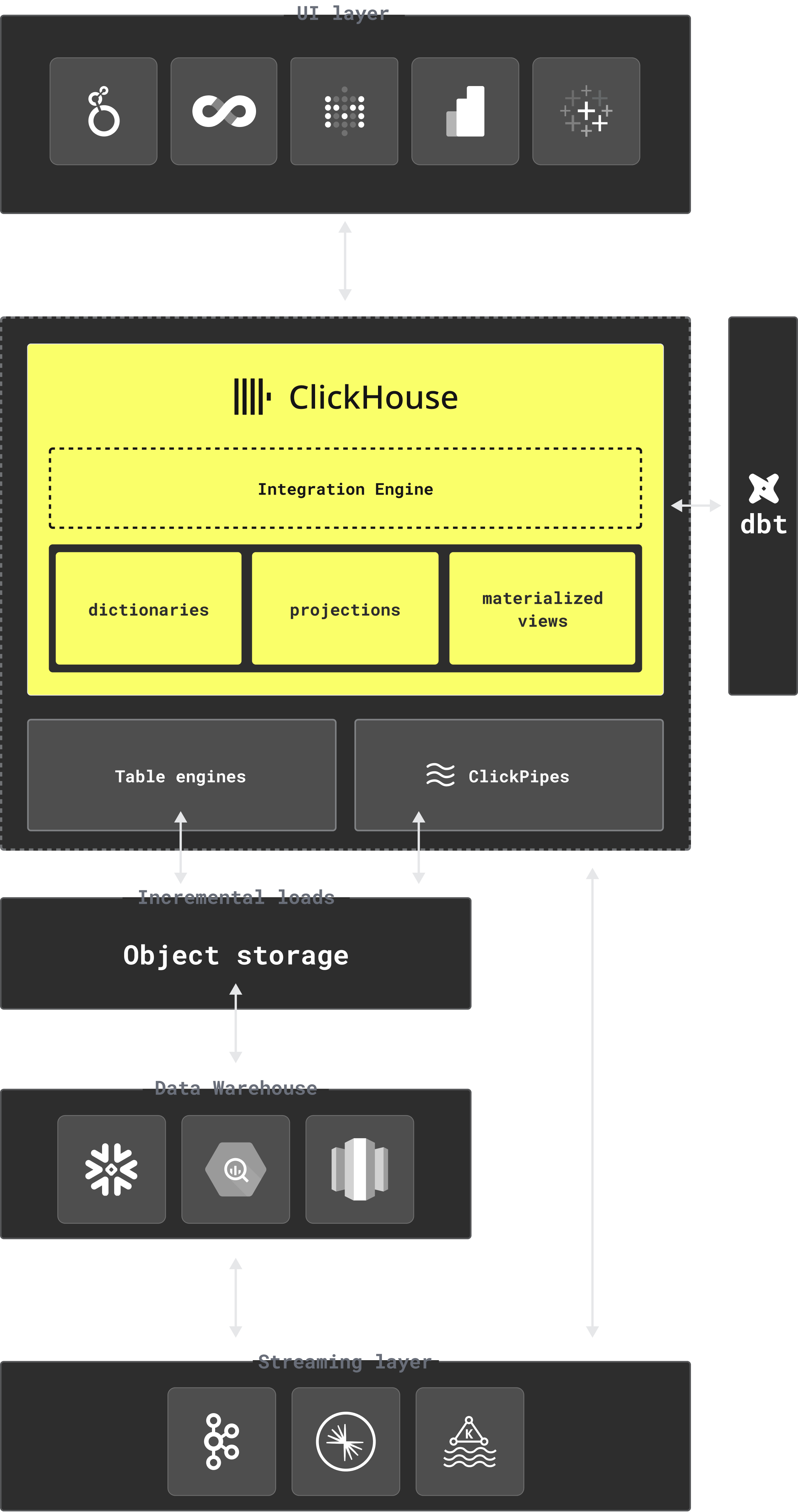
ClickHouse は、データウェアハウジングのワークフローにおける4つの重要な要素、つまりデータの取り込み、クエリ、変換、そしてチームがすでに利用しているツールとの接続を担います。
データインジェスト
大量データのロードでは、通常、S3 や GCS のようなオブジェクトストアを中継先として使用します。ClickHouse は Parquet の読み取りパフォーマンスに優れており、S3 テーブルエンジン を使って、毎秒数億行のデータをロードできます。リアルタイムストリーミングでは、ClickPipes が Kafka や Confluent のようなプラットフォームに直接接続します。
また、Snowflake、BigQuery、Databricks のような既存のデータウェアハウスから、オブジェクトストレージにエクスポートし、table engines 経由で ClickHouse にロードすることで移行することもできます。
クエリ
S3 や GCS のようなオブジェクトストア、または Iceberg、Delta Lake、Hudi のようなオープンなテーブル形式を使用するデータレイクから、データを直接クエリできます。これらの形式には、直接接続することも、AWS Glue Catalog、Unity Catalog、Iceberg REST のようなデータカタログを介して接続することもできます。
materialized views に対するクエリは高速です。要約済みの結果が専用テーブルに自動保存されるため、分析対象のデータ量にかかわらず、下流のクエリ応答性が向上します。他のデータベースベンダーでは、高速化機能が上位料金ティアや追加料金の対象になっていることがありますが、ClickHouse Cloud では、繰り返し実行されるクエリやレイテンシに敏感なクエリ向けに、query cache、sparse indexes、projections を標準で利用できます。
ClickHouse は 70 を超えるファイル形式と SQL 関数をサポートしており、日付、配列、JSON、地理空間データ、近似集計を大規模に扱えます。
データ変換
データ変換は、BI や分析ワークフローの中核となる要素です。ClickHouse の materialized views はこれを自動化します。これらの SQL ベースのビューは、新しいデータがソーステーブルに insert されるとトリガーされるため、個別の変換パイプラインを構築・管理しなくても、到着したデータをその場で抽出、集計、加工できます。
より複雑なモデリングワークフローでは、ClickHouse の dbt integration により、変換をバージョン管理された SQL モデルとして定義し、既存の dbt jobs を ClickHouse 上で直接実行するよう移行できます。
統合
ClickHouse には、Tableau や Looker のような BI ツール向けのネイティブコネクタがあります。ネイティブコネクタを持たないツールでも、追加のセットアップなしで MySQL wire protocol 経由で接続できます。セマンティックレイヤーのワークフローでは、ClickHouse は Cube と統合されており、チームは metrics を一度定義するだけで、任意の下流ツールからそれをクエリできます。金融サービス、ゲーム、eコマース など幅広い業界の企業が、データ到着直後にその価値を引き出すためにこれらの統合を活用し、ライブ dashboards や BI ワークフローを支えています。
ClickHouse は REST インターフェースもサポートしているため、複雑なバイナリプロトコルなしで軽量な application を構築できます。MCPサーバー は、LibreChat や Claude のようなツールを通じた対話型分析のために、ClickHouse を LLM に接続します。柔軟な RBAC とクォータ制御により、クライアント側でのデータ取得向けに読み取り専用テーブルを公開できます。
ハイブリッドアーキテクチャ: 両方のメリットを活かす
データレイクをクエリするだけでなく、超低レイテンシが求められるユースケース (リアルタイム dashboard、運用分析、インタラクティブ application など) 向けに、パフォーマンスクリティカルなデータを ClickHouse ネイティブの MergeTree ストレージに取り込むこともできます。
これにより、階層化されたデータ戦略を実現できます。高頻度でアクセスされるホットデータは、ClickHouse の最適化されたストレージに格納され、サブ秒レベルのクエリ応答を実現します。一方、完全なデータ履歴はデータレイク内に保持され、引き続きクエリ可能です。さらに、ClickHouse の materialized view を使用して、データレイク内のデータを継続的に変換・集約し、最適化されたテーブルに取り込むことで、2 つの階層を自動的に橋渡しできます。
データの配置先は、技術的な制限事項ではなく、パフォーマンス要件に基づいて選択できます。
詳しくは、無料の Data Warehousing with ClickHouse コースを受講してください。
