効率的なデータインジェストは、高性能な ClickHouse デプロイメントの基盤です。適切な 挿入 戦略を選ぶことは、スループット、コスト、信頼性に大きく影響します。このセクションでは、ワークロードに適した判断ができるよう、ベストプラクティス、トレードオフ、設定オプションについて説明します。
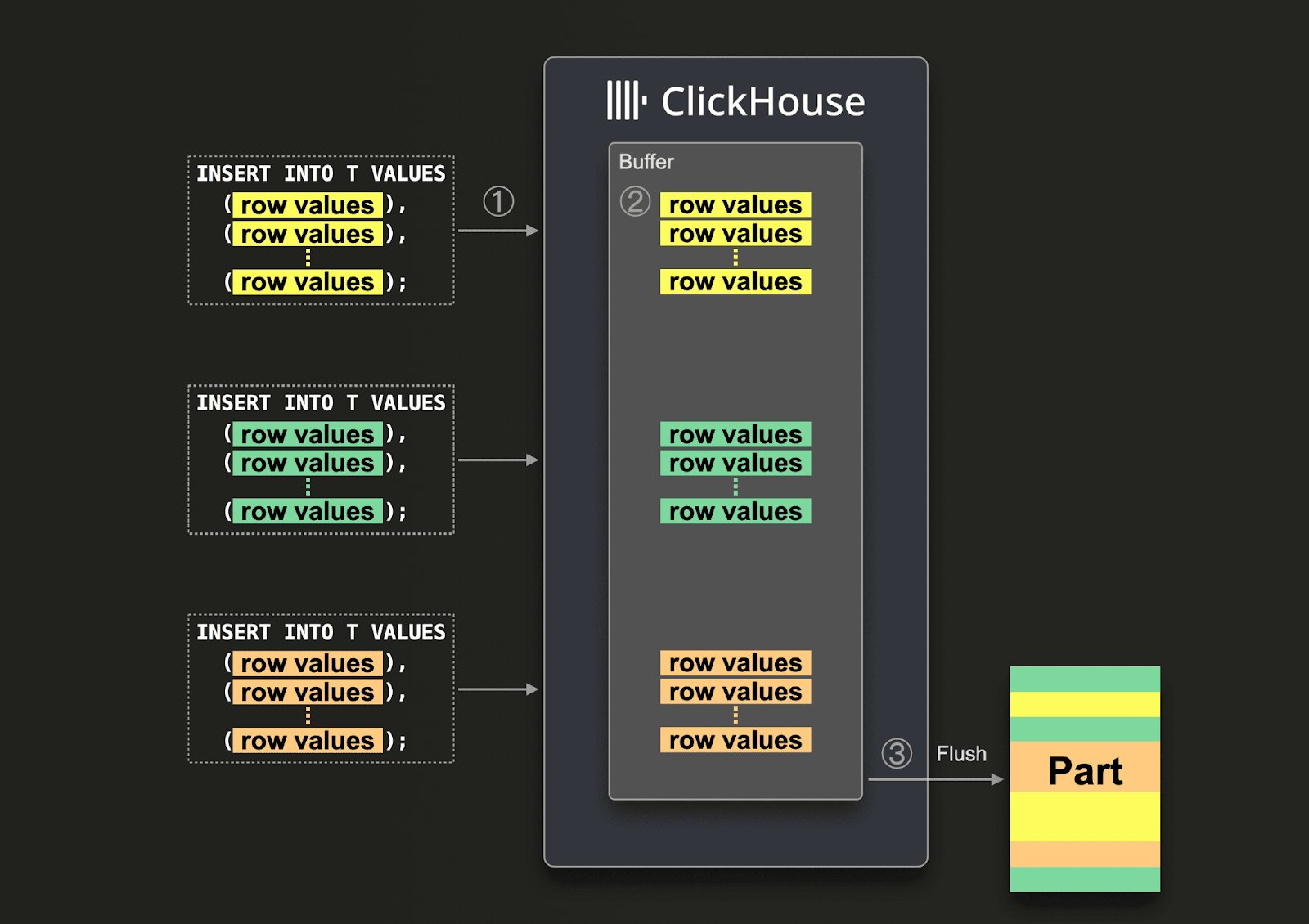
デフォルトでは、ClickHouse への挿入は同期的に行われます。各挿入クエリでは、メタデータや索引を含むストレージパーツがディスク上に直ちに作成されます。
クライアント側でデータをバッチ化できる場合は、同期挿入を使用してくださいできない場合は、以下の非同期挿入を参照してください。 insert のサイズにかかわらず、INSERT クエリ数は 1 秒あたりおよそ 1 件に保つことを推奨します。これは、作成されたパーツがバックグラウンドでより大きなパーツへマージされるためです (読み取りクエリ向けにデータを最適化するため) 。そのため、1 秒あたりに送信する INSERT クエリが多すぎると、バックグラウンドでのマージが新しいパーツの生成に追いつけなくなることがあります。ただし、非同期挿入を使用する場合は、1 秒あたりの INSERT クエリ数をさらに増やすことができます (非同期挿入 を参照) 。
- 挿入 は成功したものの、ネットワークの中断によりクライアントが確認応答を受信できなかった。
- 挿入 はサーバー側で失敗し、タイムアウトした。
どちらの場合でも、バッチの内容と順序が完全に同一である限り、挿入 を再試行 しても安全です。そのため、クライアントはデータを変更したり順序を入れ替えたりせず、常に同じ形で再試行することが重要です。
分片化されたクラスターでは、次の 2 つの選択肢があります。
- MergeTree または ReplicatedMergeTree テーブルに直接挿入します。これは、クライアントが分片間で負荷分散を行える場合に最も効率的な方法です。
internal_replication = true を指定すると、ClickHouse が透過的にレプリケーションを処理します。
- 分散テーブル に挿入します。これにより、クライアントは任意のノードにデータを送信し、ClickHouse に正しい分片へ転送させることができます。こちらのほうが簡単ですが、転送処理が 1 段増えるぶん、パフォーマンスはわずかに低下します。
internal_replication = true は引き続き推奨されます。
ClickHouse Cloud では、すべてのノードが同じ単一の分片に対して読み書きを行います。挿入はノード間で自動的に負荷分散されます。公開されているエンドポイントに送信するだけで済みます。
ClickHouse でデータを効率よく取り込むには、適切な入力フォーマットを選ぶことが重要です。対応フォーマットは 70 種類以上あり、最も高性能なフォーマットを選ぶことで、挿入速度、CPU とメモリの使用量、システム全体の効率に大きく影響します。
柔軟性はデータエンジニアリングやファイルベースのインポートでは有用ですが、アプリケーションではパフォーマンス重視のフォーマットを優先すべきです。
- Native format (推奨) : 最も効率的です。列指向で、サーバー側で必要なパースも最小限です。Go クライアントおよび Python クライアントではデフォルトで使用されます。
- RowBinary: 効率的な行ベースのフォーマットで、クライアント側で列指向への変換が難しい場合に最適です。Java クライアントで使用されます。
- JSONEachRow: 使いやすい一方で、パースのコストが高くなります。少量データのユースケースや短期間でのインテグレーションに適しています。
圧縮は、ネットワークのオーバーヘッドを削減し、挿入を高速化し、ClickHouse のストレージコストを抑えるうえで重要な役割を果たします。適切に活用すれば、データのフォーマットやスキーマを変更しなくても、インジェスト性能を向上させることができます。
挿入するデータを圧縮すると、ネットワーク経由で送信されるペイロードのサイズが小さくなり、帯域幅の使用量を最小限に抑えつつ、転送を高速化できます。
挿入では、圧縮は特に Nativeフォーマット と組み合わせると効果的です。これは、ClickHouse の内部的な列指向ストレージモデルにすでに適合しているためです。この構成では、サーバーはデータを効率よく展開し、最小限の変換でそのまま保存できます。
速度を重視するなら LZ4、圧縮率を重視するなら ZSTD
- LZ4: 高速かつ軽量です。CPU オーバーヘッドをほとんど増やさずにデータサイズを大きく削減できるため、高スループットの 挿入 に適しており、ほとんどの ClickHouse クライアントでデフォルトとして使われています。
- ZSTD: より高い圧縮率を得られる一方で、CPU 負荷も高くなります。リージョン間やクラウドプロバイダー間のようにネットワーク転送コストが高い場合に有効ですが、クライアント側のコンピュートとサーバー側の伸長時間がわずかに増加します。
ベストプラクティス: 帯域幅に制約がある、またはデータ送信コストがかかる場合を除き、LZ4 を使用してください。そのような場合は ZSTD を検討してください。
FastFormats benchmark のテストでは、LZ4 圧縮の Native inserts によりデータサイズが 50% 以上削減され、5.6 GiB のデータセットでインジェスト時間が 150 秒から 131 秒に短縮されました。ZSTD に切り替えると、同じデータセットは 1.69 GiB まで圧縮されましたが、サーバー側の処理時間はわずかに増加しました。 同期モードで多数の小さなバッチを送信することは推奨されません。多くのパーツが作成される原因になるためです。これにより、クエリ性能の低下や “too many part” エラーにつながります。 async_insert 設定によって制御されます。
非同期挿入は HTTP と native TCP の両方のインターフェイスでサポートされています。
有効化されている場合 (async_insert = 1) 、INSERT はバッファリングされ、次のフラッシュ条件のいずれかが満たされた時点でのみ disk に書き込まれます。
最初に到達したしきい値でフラッシュがトリガーされます。
このバッチ処理はクライアントからは見えず、ClickHouse が複数のソースからの INSERT トラフィックを効率的にマージするのに役立ちます。ただし、フラッシュが発生するまでは、そのデータをクエリすることはできません。重要なのは、INSERT の shape と settings の組み合わせごとに複数のバッファが存在し、クラスターではノードごとにバッファが維持されることです。これにより、マルチテナント環境全体で細かな制御が可能になります。それ以外の INSERT の仕組みは、同期挿入 で説明されているものと同一です。
非同期挿入の動作は、wait_for_async_insert 設定によってさらに細かく制御できます。
1 (デフォルト) に設定すると、ClickHouse はデータが正常にディスクにフラッシュされたあとでのみ insert の受け付けを通知します。これにより高い永続性が確保され、error 処理もシンプルになります。フラッシュ中に問題が発生した場合は、その error がクライアントに返されます。このモードは、ほとんどの本番環境、とくに insert の失敗を確実に追跡する必要がある場合に推奨されます。
ベンチマーク では、適応的な insert と安定した part 作成動作により、200 クライアントでも 500 クライアントでも、高い並行度でも良好にスケールすることが示されています。
wait_for_async_insert = 0 を設定すると、「fire-and-forget」モードが有効になります。この場合、server はデータが storage に書き込まれるのを待たず、バッファ に格納された時点で insert の受け付けを通知します。
これにより、超低 latency の insert と最大限の throughput が得られるため、高速に流入し、重要度の低いデータに適しています。ただし、これにはトレードオフがあります。データが永続化される保証はなく、error が表面化するのはフラッシュ時だけで、失敗した insert のための dead-letter queue もありません。障害を追跡するには、事後的に サーバーログ とシステムテーブルを調査する必要があります。このモードは、workload がデータ損失を許容できる場合にのみ使用してください。
ベンチマークではさらに、バッファ のフラッシュ頻度が低い場合 (たとえば 30 Seconds ごと) には、part の大幅な削減と CPU 使用率の低下も示されていますが、気づかれないまま失敗するリスクは残ります。
非同期挿入を使用する場合は、async_insert=1,wait_for_async_insert=1 を使うことを強く推奨します。wait_for_async_insert=0 の使用は非常に危険です。error が発生しても INSERT クライアントがそれを認識できない可能性があるうえ、service の信頼性を確保するために ClickHouse server 側で書き込みを抑制し、backpressure をかける必要がある状況でも、クライアントが高速な書き込みを続けることで過負荷を引き起こすおそれがあるためです。
バージョン 24.2 以降、ClickHouse ではデフォルトで適応型のフラッシュタイムアウト (async_insert_use_adaptive_busy_timeout) が使用されます。固定のフラッシュ間隔ではなく、受信データのレートに応じて、タイムアウトが最小値 (async_insert_busy_timeout_min_ms、デフォルトは 50 ms) から最大値 (async_insert_busy_timeout_max_ms、デフォルトは 200 ms、Cloud では 1000 ms) までの範囲で動的に調整されます。
データが高頻度で到着する場合、より早くフラッシュしてエンドツーエンドのレイテンシを抑えるため、タイムアウトは最小値寄りに保たれます。データがスパースな場合は、より大きなバッチを蓄積できるよう、最大値に向かって長くなります。これは、固定の長いタイムアウトを設定すると、フラッシュ可能なデータがすでに揃っていてもクライアントがその間ずっと待たされてしまうデフォルトモード (wait_for_async_insert=1) で特に有効です。
スキーマの検証とデータのパースは、insert の受信時ではなく、バッファのフラッシュ時に行われます。INSERT クエリ内のいずれかの行にパースまたは型のエラーがある場合、そのクエリのデータは一切フラッシュされません — クエリ全体のペイロードが拒否されます。デフォルトモード (wait_for_async_insert=1) では、エラーはクライアントに返されます。fire-and-forget モードでは、エラーはサーバーログと system.asynchronous_inserts テーブルに書き込まれます。
フラッシュが実行されるたびに、バッファ内の異なる各パーティションキーの値ごとに少なくとも 1 つのパーツが作成されます。パーティションキーのないテーブルであっても、バッファされたデータが max_insert_block_size (デフォルトは約 100 万行) を超える場合、1 回のフラッシュで複数のパーツが生成されることがあります。
非同期 INSERT を使用していても、パーティション化キーのカーディナリティが高い場合は、“パーツが多すぎる” エラーが発生することがあります。
-
ユーザーレベルで非同期挿入を有効にします。この例ではユーザー
default を使用しています。別のユーザーを作成した場合は、そのユーザー名に置き換えてください。
-
INSERT クエリの SETTINGS 句を使用して、非同期挿入の設定を指定することもできます。
-
ClickHouse のプログラミング言語クライアントを使用する場合は、接続パラメーターとして非同期挿入の設定を指定することもできます。
たとえば、ClickHouse Cloud への接続に ClickHouse Java JDBCドライバーを使用する場合、JDBC 接続文字列では次のように指定できます。
非同期挿入は INSERT INTO ... SELECT クエリには適用されません。挿入に SELECT 句が含まれている場合、async_insert 設定に関係なく、クエリは常に同期的に実行されます。
- DDL の変更は不要です。 非同期挿入は透過的に動作するため、追加のテーブルを作成するのではなく、設定を有効にするだけで利用できます。
- クエリ形状ごとのバッファリング。 非同期挿入では、一意のクエリ形状と設定の組み合わせごとに個別のバッファが維持されるため、きめ細かな フラッシュ ポリシーを適用できます。Buffer tables では、ターゲットテーブルごとに 1 つのバッファを使用します。
- 耐久性。 デフォルトモード (
wait_for_async_insert=1) では、クライアントに確認応答が返される前に、データがディスクに書き込まれたことが確認されます。Buffer tables は fire-and-forget 型で動作するため、クラッシュ時にはバッファ内のデータが失われます。
- クラスターでの動作。 クラスターでは、非同期挿入のバッファはノードごとに維持されます。Buffer tables では、各ノードで明示的に作成する必要があります。
インターフェイスの選択—HTTP またはネイティブ
Content-Encoding: lz4) を使って圧縮できますが、圧縮は個々のデータブロックではなくペイロード全体に適用されます。このインターフェイスは、生のパフォーマンスよりも、プロトコルの単純さ、ロードバランシング、または幅広いフォーマット互換性が重要な環境で好まれることがよくあります。
これらのインターフェイスのより詳しい説明については、こちらを参照してください。