このページでは、用語「オーダリングキー」を「主キー」と同義で使用します。厳密にはClickHouse ではこれらは異なりますが、本ドキュメントの範囲では同じものとして扱って構いません。このとき オーダリングキー は、テーブルの ORDER BY で指定された列を指します。
ClickHouse の 主キー は、Postgres のような OLTP データベースで類似の用語に慣れている方にとっては挙動が大きく異なる点に注意してください。
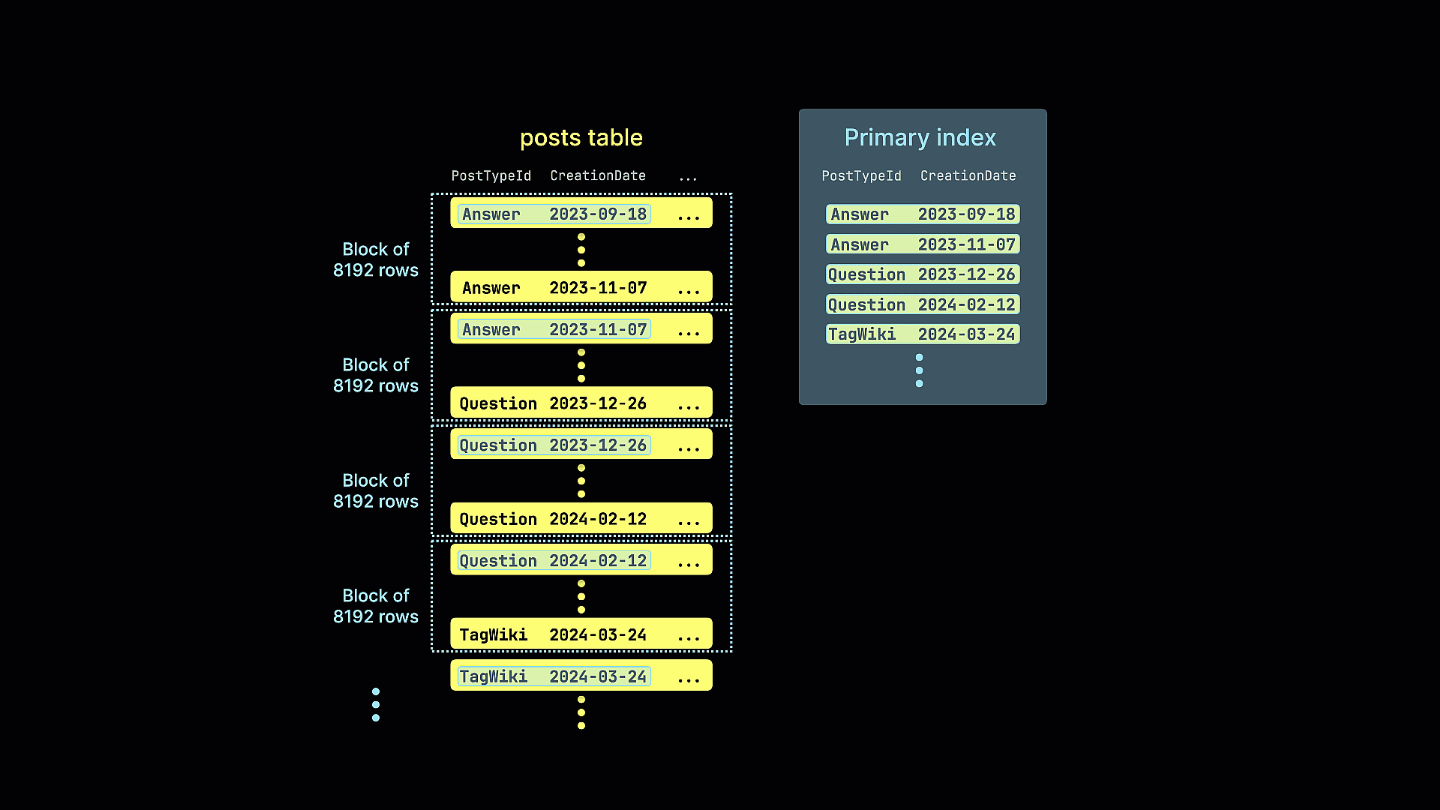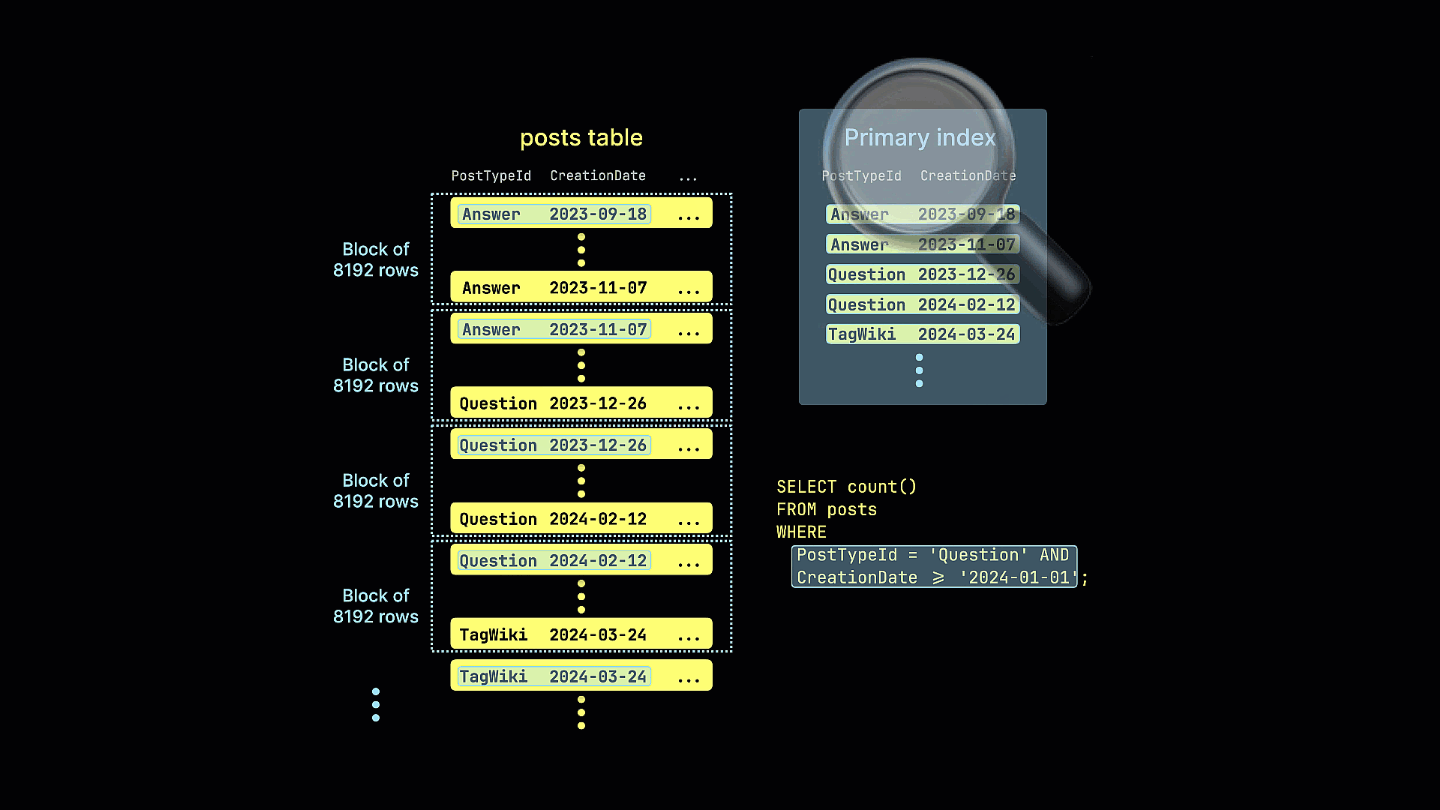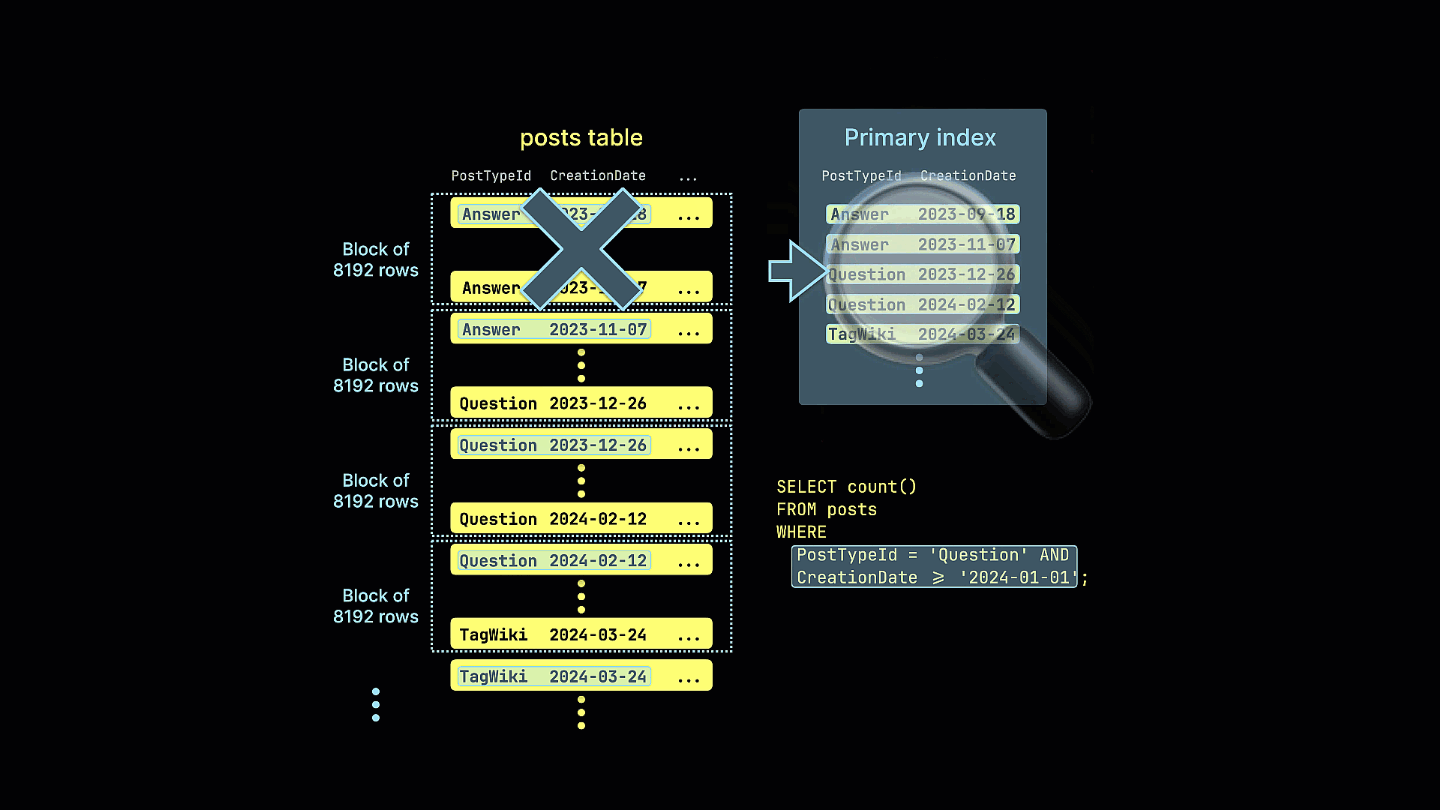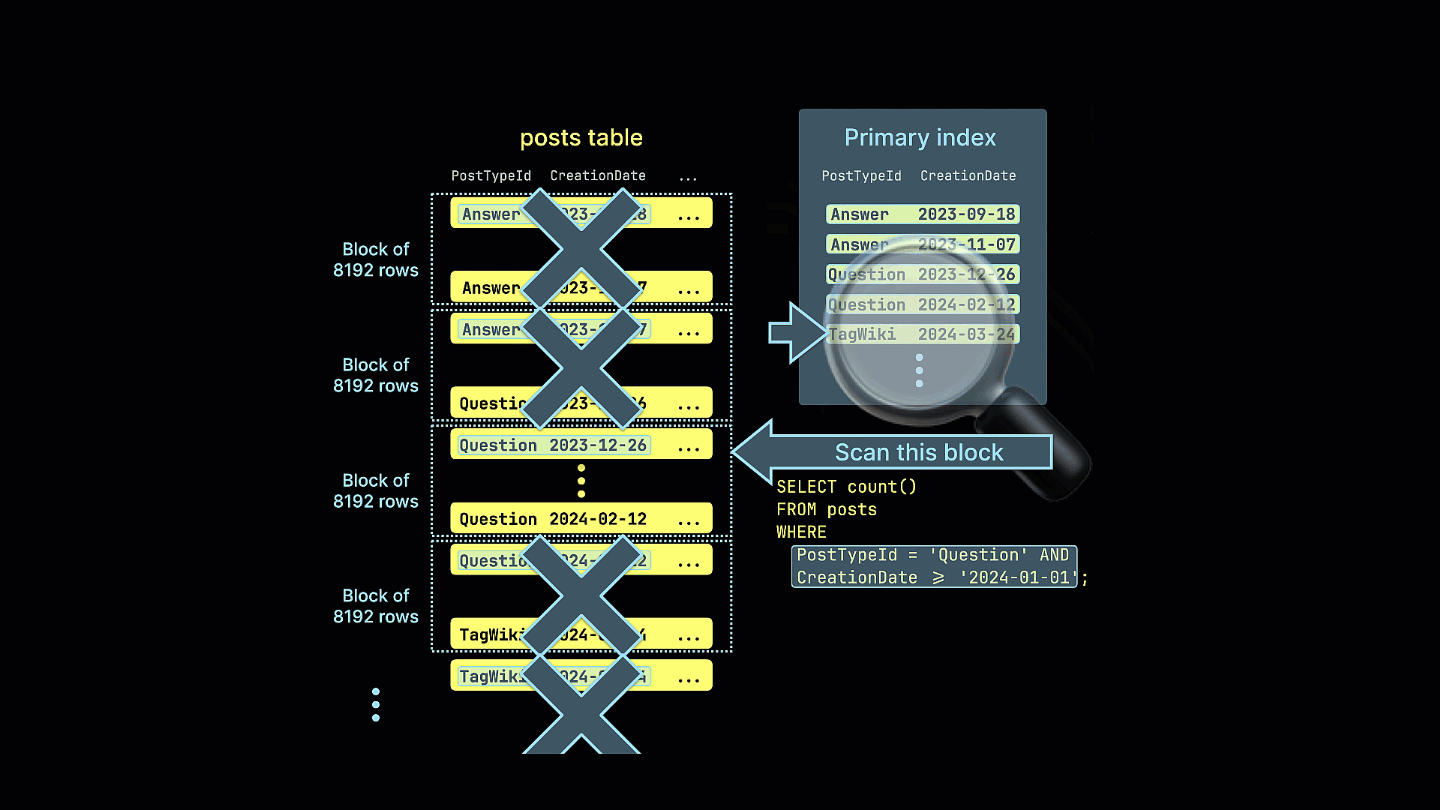
ClickHouse で効果的な 主キー を選択することは、クエリパフォーマンスとストレージ効率の両方にとって極めて重要です。ClickHouse はデータをパーツと呼ばれる単位に分割して保持し、各パーツは独自のスパースな primary index を持ちます。このインデックスにより、スキャンするデータ量を削減してクエリを大幅に高速化できます。さらに、主キー はディスク上のデータの物理的な並び順を決定するため、圧縮効率にも直接影響します。最適に並んだデータはより高い圧縮率を実現でき、その結果として I/O が削減され、性能が一層向上します。
- オーダリングキー を選ぶ際は、クエリフィルタ (
WHERE 句) で頻繁に使用される列、特に大量の行を除外する列を優先してください。
- テーブル内の他のデータと高い相関がある列も有用です。連続した配置により、
GROUP BY や ORDER BY 処理中の圧縮率およびメモリ効率が向上するためです。
オーダリングキー を選ぶ際に役立つ、いくつかの単純なルールを適用できます。以下のルールは互いに矛盾する場合があるため、ここに示す順序で検討してください。このプロセスから複数の候補キーを洗い出すことができ、通常は 4〜5 個あれば十分です。
Important
オーダリングキー はテーブル作成時に定義する必要があり、後から追加することはできません。追加の並び順は、projections と呼ばれる機能を用いて、データ挿入の前後を問わずテーブルに付与できます。ただし、その結果データが重複して保存される点に注意してください。詳細はこちらを参照してください。
次の posts_unordered テーブルを考えます。これは Stack Overflow の投稿 1 件ごとに 1 行のデータを含んでいます。
このテーブルには、ORDER BY tuple() で示されているように、プライマリキーがありません。
CREATE TABLE posts_unordered
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4,
'TagWiki' = 5, 'ModeratorNomination' = 6, 'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
`AcceptedAnswerId` UInt32,
`CreationDate` DateTime,
`Score` Int32,
`ViewCount` UInt32,
`Body` String,
`OwnerUserId` Int32,
`OwnerDisplayName` String,
`LastEditorUserId` Int32,
`LastEditorDisplayName` String,
`LastEditDate` DateTime,
`LastActivityDate` DateTime,
`Title` String,
`Tags` String,
`AnswerCount` UInt16,
`CommentCount` UInt8,
`FavoriteCount` UInt8,
`ContentLicense`LowCardinality(String),
`ParentId` String,
`CommunityOwnedDate` DateTime,
`ClosedDate` DateTime
)
ENGINE = MergeTree
ORDER BY tuple()
あるユーザーが、2024年以降に送信された質問の件数を計算したいとします。そのための処理が、そのユーザーにとって最も一般的なアクセスパターンであると仮定します。
SELECT count()
FROM stackoverflow.posts_unordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─count()─┐
│ 192611 │
└─────────┘
--highlight-next-line
1 row in set. Elapsed: 0.055 sec. Processed 59.82 million rows, 361.34 MB (1.09 billion rows/s., 6.61 GB/s.)
このクエリで読み込まれた行数とバイト数に注目してください。プライマリキーがない場合、クエリはデータセット全体をスキャンする必要があります。
EXPLAIN indexes=1 を使用すると、インデックスが存在しないためにテーブル全体がスキャンされていることが確認できます。
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts_unordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─explain───────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts_unordered) │
└───────────────────────────────────────────────────────────┘
5 rows in set. Elapsed: 0.003 sec.
同じデータを含む posts_ordered というテーブルがあり、そのテーブルの ORDER BY が (PostTypeId, toDate(CreationDate)) として定義されていると仮定します。つまり、
CREATE TABLE posts_ordered
(
`Id` Int32,
`PostTypeId` Enum('Question' = 1, 'Answer' = 2, 'Wiki' = 3, 'TagWikiExcerpt' = 4, 'TagWiki' = 5, 'ModeratorNomination' = 6,
'WikiPlaceholder' = 7, 'PrivilegeWiki' = 8),
...
)
ENGINE = MergeTree
ORDER BY (PostTypeId, toDate(CreationDate))
PostTypeId はカーディナリティが 8 であり、ソートキーの最初の要素として論理的に適した選択です。日付粒度でのフィルタリングで十分である可能性が高いと判断できるため (それでも日時でのフィルタの恩恵は受けます) 、キーの 2 番目の構成要素として toDate(CreationDate) を使用します。これは日付を 16 ビットで表現できるため、より小さいインデックスが生成され、フィルタリングが高速になります。
次のアニメーションは、Stack Overflow の posts テーブルに対して最適化されたスパースプライマリインデックスがどのように作成されるかを示しています。個々の行をインデックス化する代わりに、インデックスは行のブロックを対象とします:
このソートキーを持つテーブルに対して同じクエリを実行した場合:
SELECT count()
FROM stackoverflow.posts_ordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─count()─┐
│ 192611 │
└─────────┘
--highlight-next-line
1 row in set. Elapsed: 0.013 sec. Processed 196.53 thousand rows, 1.77 MB (14.64 million rows/s., 131.78 MB/s.)
このクエリはスパースインデックスを活用し、読み取るデータ量を大幅に削減することで、実行時間を4倍高速化します。読み取る行数とバイト数の削減に注目してください。
インデックスの使用状況は EXPLAIN indexes=1 で確認できます。
EXPLAIN indexes = 1
SELECT count()
FROM stackoverflow.posts_ordered
WHERE (CreationDate >= '2024-01-01') AND (PostTypeId = 'Question')
┌─explain─────────────────────────────────────────────────────────────────────────────────────┐
│ Expression ((Project names + Projection)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Expression │
│ ReadFromMergeTree (stackoverflow.posts_ordered) │
│ Indexes: │
│ PrimaryKey │
│ Keys: │
│ PostTypeId │
│ toDate(CreationDate) │
│ Condition: and((PostTypeId in [1, 1]), (toDate(CreationDate) in [19723, +Inf))) │
│ Parts: 14/14 │
│ Granules: 39/7578 │
└─────────────────────────────────────────────────────────────────────────────────────────────┘
13 rows in set. Elapsed: 0.004 sec.
さらに、疎インデックスが、サンプルクエリで一致する可能性のないすべての行ブロックをどのように除外するかを視覚的に示します。
注記
テーブル内のすべてのカラムは、指定されたオーダリングキーの値に基づいてソートされます。これは、そのカラムがキー自体に含まれているかどうかに関係ありません。たとえば、CreationDate がキーとして使用されている場合、他のすべてのカラムの値の順序は、CreationDate カラムの値の順序に対応します。複数のオーダリングキーを指定することもでき、その場合、SELECT クエリの ORDER BY 句と同じセマンティクスで並べ替えが行われます。
プライマリキーの選択に関する詳細な上級者向けガイドはこちらにあります。
オーダリングキーがどのように圧縮率を高め、ストレージをさらに最適化するかについてより深く理解するには、Compression in ClickHouse および Column Compression Codecs に関する公式ガイドを参照してください。