アーキテクチャ概要
これは、VLDB 2024 の学術論文の Web 版です。論文の背景とその歩みについてはブログ記事も公開しており、ClickHouse の CTO 兼開発者である Alexey Milovidov による VLDB 2024 での発表もぜひご視聴ください:
ABSTRACT
過去数十年にわたり、保存・分析されるデータ量は指数関数的に増加してきました。さまざまな業界やセクターのビジネスは、このデータを活用してプロダクトを改善し、パフォーマンスを評価し、事業にとってクリティカルな意思決定を行うようになっています。しかし、データ量がインターネット規模へと拡大するにつれて、ビジネスは大量の履歴データと新規データをコスト効率よくスケーラブルに管理し、かつ多数の同時クエリとリアルタイムなレイテンシ (ユースケースに応じて例えば1秒未満) という期待に応えつつ分析する必要が生じています。
本稿では、ペタバイト規模データセットに対する高いインジェストレートと高性能なアナリティクスのために設計された、広く利用されているオープンソースの OLAP データベースである ClickHouse の概要を示します。そのストレージレイヤーは、従来の log-structured merge (LSM) ツリーに基づくデータフォーマットと、バックグラウンドで履歴データを継続的に変換 (例:集約、アーカイブ) するための新しい手法を組み合わせています。クエリは扱いやすい SQL 方言で記述され、オプションのコードコンパイルに対応した最先端のベクトル化クエリ実行エンジンによって処理されます。ClickHouse は、クエリにおいて不要なデータの評価を避けるために、積極的にプルーニング手法を利用します。他のデータマネジメントシステムは、テーブル関数、table engine、あるいはデータベースエンジンのレベルで統合することができます。実際のワークロードに基づくベンチマークにより、ClickHouse が市場で最も高速な分析データベースの一つであることが示されています。
1 INTRODUCTION
本稿では、数兆行・数百列のテーブルに対する高性能な分析クエリ向けに設計された列指向 OLAP データベースである ClickHouse について説明します。ClickHouse は 2009 年にウェブ規模のログファイルデータ向けのフィルタおよび集約オペレーターとして開発が開始され、2016 年にオープンソース化されました。本稿で説明する主な機能が ClickHouse にいつ導入されたかを 図1 に示します。
ClickHouse は、現代的な分析データ管理における 5 つの主要な課題に対処するように設計されています。
-
巨大なデータセットと高いインジェストレート。ウェブ解析、金融、e コマースといった業界の多くのデータドリブンなアプリケーションは、巨大で継続的に増加するデータ量という特徴を持ちます。巨大なデータセットを扱うためには、分析データベースは効率的なインデックスおよび圧縮戦略を提供するだけでなく、単一サーバーが数十テラバイト程度のストレージ容量に制約されることを踏まえ、データを複数ノードに分散(スケールアウト)できなければなりません。さらに、リアルタイムなインサイトにおいては、履歴データよりも直近のデータのほうが重要になることがよくあります。その結果として、分析データベースは、新しいデータを常に高いレートまたはバースト的に取り込むことができると同時に、多数のレポートクエリを並行して実行しても速度低下を招くことなく、履歴データの優先度を継続的に下げ(例: 集約、アーカイブ)られる必要があります。
-
多数の同時クエリと低レイテンシへの期待。クエリは一般にアドホック(例: 探索的データ分析)と定期的(例: 定期ダッシュボードクエリ)に分類できます。ユースケースがインタラクティブであればあるほど、低いクエリレイテンシが期待されるため、クエリの最適化と実行における課題が増します。定期的なクエリは、物理データベースレイアウトをワークロードに適応させる機会も提供します。その結果として、データベースは頻出クエリを最適化できるプルーニング手法を備えるべきです。さらにクエリの優先度に応じて、多数のクエリが同時に実行されている場合でも、CPU、メモリ、ディスク、ネットワーク I/O といった共有システムリソースへの平等または優先的なアクセスを保証しなければなりません。
-
多様なデータストア、保存場所、およびフォーマットから成る環境。既存のデータアーキテクチャと統合するために、現代的な分析データベースは、任意のシステム、場所、フォーマットの外部データを読み書きできる高い柔軟性とオープン性を備えている必要があります。
-
性能の解析をサポートする利便性の高いクエリ言語。OLAP データベースの実運用では、追加の「ソフト」な要件が生じます。たとえば、ニッチなプログラミング言語ではなく、入れ子のデータ型や、豊富な通常関数・集約関数・ウィンドウ関数を備えた表現力の高い SQL 方言でデータベースと対話したいとユーザーは考えることが多いでしょう。また分析データベースは、システム全体や個々のクエリの性能を解析・内省するための高度なツール群も提供すべきです。
-
業界水準の堅牢性と多様なデプロイ形態。汎用ハードウェアは信頼性が低いため、データベースはノード障害に対する堅牢性を確保するためにデータレプリケーションを提供しなければなりません。また、データベースは古いノート PC から高性能サーバーまで、あらゆるハードウェア上で動作することが望まれます。最後に、JVM ベースのプログラムにおけるガーベジコレクションのオーバーヘッドを回避し、ベアメタル性能(例: SIMD)を実現するために、データベースは対象プラットフォーム向けのネイティブバイナリとしてデプロイされるのが理想的です。

図1: ClickHouse のタイムライン。
2 アーキテクチャ

図 2: ClickHouse データベースエンジンの高レベルアーキテクチャ。
図 2 に示すように、ClickHouse エンジンは 3 つの主要なレイヤーに分かれている。クエリ処理レイヤー (4 章 で説明) 、ストレージレイヤー (3 章) 、およびインテグレーションレイヤー (5 章) である。これらに加えて、アクセスレイヤーがユーザーセッションを管理し、さまざまなプロトコルを介してアプリケーションとの通信を行う。さらに、スレッド処理、キャッシュ、ロールベースアクセス制御、バックアップ、継続的モニタリングのための直交するコンポーネントも存在する。ClickHouse は C++ で実装されており、依存関係を持たない単一の静的リンクバイナリとして構築されている。
クエリ処理は、受信クエリのパース、論理および物理クエリプランの構築と最適化、そして実行という従来のパラダイムに従う。ClickHouse は、MonetDB/X100 [11] に類似したベクトル化実行モデルと、オポチュニスティックなコードコンパイル [53] を組み合わせて用いる。クエリは、機能が豊富な SQL 方言や PRQL [76]、あるいは Kusto の KQL [50] で記述できる。
ストレージレイヤーは、テーブルデータの形式と配置場所をカプセル化するさまざまなテーブルエンジンから構成される。テーブルエンジンは 3 つのカテゴリに分類される。1 つ目のカテゴリは、ClickHouse における主要な永続化形式を表す MergeTree* ファミリーのテーブルエンジンである。LSM ツリー [60] のアイデアに基づき、テーブルは水平方向のソート済みパーツに分割され、バックグラウンドプロセスによって継続的にマージされる。個々の MergeTree* テーブルエンジンは、入力パーツからの行をどのようにマージするかが異なる。例えば、古くなった行であれば集約したり、置き換えたりできる。
2 つ目のカテゴリは、クエリ実行を高速化または分散させるために使用される、特定用途向けのテーブルエンジンである。このカテゴリには、ディクショナリと呼ばれるインメモリ Key-Value テーブルエンジンが含まれる。dictionary は、内部または外部のデータソースに対して定期的に実行されるクエリの結果をキャッシュする。これは、ある程度のデータの陳腐化を許容できるシナリオにおいて、アクセスレイテンシを大幅に削減する。特定用途向けテーブルエンジンの他の例として、一時テーブルに使用される純粋なインメモリエンジンや、透過的なデータシャーディングのための Distributed table engine (後述) などがある。
3 つ目のテーブルエンジンのカテゴリは、リレーショナルデータベース (例: PostgreSQL, MySQL) 、Publish/Subscribe システム (例: Kafka, RabbitMQ [24]) 、あるいは Key/Value ストア (例: Redis) などの外部システムとの双方向データ交換のための仮想テーブルエンジンである。仮想エンジンは、データレイク (例: Iceberg, DeltaLake, Hudi [36]) や、オブジェクトストレージ内のファイル (例: AWS S3, Google GCP) とも連携できる。
ClickHouse は、スケーラビリティと可用性のために、複数の cluster ノード間でのテーブルのシャーディングおよびレプリケーションをサポートする。シャーディングは、シャーディング式に従ってテーブルを複数のテーブルシャードに分割する。個々のシャードは互いに独立したテーブルであり、通常は異なるノードに配置される。クライアントはシャードを直接読み書きして (すなわち個別のテーブルとして扱って) もよいし、すべてのテーブルシャードのグローバルビューを提供する Distributed の特別な table engine を使用することもできる。シャーディングの主目的は、個々のノードのキャパシティ (典型的には数十テラバイトのデータ) を超えるデータセットを処理することである。シャーディングのもう 1 つの用途は、1 つのテーブルに対する読み書き負荷を複数ノードに分散させる、すなわち負荷分散を行うことである。これとは直交して、shard を複数ノードにレプリケートしてノード障害に対する耐性を持たせることができる。そのために、各 Merge-Tree* table engine には対応する ReplicatedMergeTree* エンジンがあり、Raft コンセンサス [59] に基づくマルチマスタ協調方式 (C++ で実装された Apache Zookeeper のドロップイン代替である Keeper によって実装) を用いて、あらゆる時点で各 shard が設定可能な数のレプリカを持つことを保証する。3.6 章 でレプリケーションメカニズムを詳しく説明する。例として、図 2 は 2 つのシャードを持ち、それぞれが 2 ノードにレプリケートされているテーブルを示している。
最後に、ClickHouse データベースエンジンは、オンプレミス、クラウド、スタンドアロン、インプロセスといった複数のモードで運用できます。オンプレミスモードでは、ユーザーは ClickHouse を単一サーバーとして、あるいはシャーディングやレプリケーションを備えたマルチノードのクラスタとしてローカルにセットアップします。クライアントは、ネイティブプロトコル、MySQL および PostgreSQL のバイナリワイヤプロトコル、または HTTP REST API を介してデータベースと通信します。クラウドモードは、フルマネージドかつ自動スケーリング対応の DBaaS である ClickHouse Cloud によって表現されます。本稿ではオンプレミスモードに焦点を当てていますが、今後の公開資料で ClickHouse Cloud のアーキテクチャについて説明する予定です。スタンドアロンモードでは、ClickHouse をファイルの分析および変換のためのコマンドラインユーティリティとして利用でき、cat や grep などの Unix ツールに対する SQL ベースの代替手段となります。事前の設定は不要ですが、スタンドアロンモードは単一サーバーに限定されます。最近では、chDB [15] と呼ばれるインプロセスモードが開発されており、Jupyter notebooks [37] や Pandas dataframes [61] といったインタラクティブなデータ分析のユースケース向けに利用されています。DuckDB [67] に着想を得た chDB は、ClickHouse を高性能な OLAP エンジンとしてホストプロセスに埋め込みます。このモードでは、他のモードと比較して、同一のアドレス空間で動作するため、データベースエンジンとアプリケーション間でソースデータおよび結果データをコピーすることなく効率的に受け渡すことが可能になります。
3 ストレージ層
このセクションでは、ClickHouse のネイティブなストレージフォーマットである MergeTree* テーブルエンジンについて説明します。ディスク上での表現を示し、その後 ClickHouse における 3 つのデータプルーニング手法を解説します。続いて、同時の挿入処理に影響を与えることなくデータを継続的に変換するマージ戦略を紹介します。最後に、更新と削除がどのように実装されているかに加え、データ重複排除、データレプリケーション、および ACID 準拠について説明します。
3.1 On-Disk Format
MergeTree* table engine の各テーブルは、変更不可能なテーブル parts の集合として構成されています。ある行集合がテーブルに挿入されるたびに 1 つの part が作成されます。Parts は自己完結しており、その内容を解釈するために必要なすべてのメタデータを含んでいるため、中央カタログを追加で参照する必要はありません。テーブルあたりの parts 数を抑えるため、バックグラウンドのマージジョブが定期的に複数の小さな parts を 1 つの大きな part に結合し、設定可能な part サイズ (デフォルトでは 150 GB) に達するまで繰り返します。parts はテーブルの primary key 列でソートされているため (3.2 節参照) 、マージには効率的な k-way マージソート [40] が利用されます。元の parts は非アクティブとしてマークされ、参照カウントが 0 になる、すなわちそれらから読み取るクエリが存在しなくなった時点で最終的に削除されます。
行は 2 つのモードで挿入できます。同期挿入モードでは、各 INSERT 文が新しい part を作成し、それをテーブルに追加します。マージ処理のオーバーヘッドを最小化するため、データベースクライアントは、例えば 20,000 行ずつなど、タプルを一括で挿入することが推奨されます。しかし、クライアント側のバッチ処理による遅延は、データをリアルタイムに分析したい場合にはしばしば許容できません。例えば、オブザーバビリティのユースケースでは、多数のモニタリングエージェントが少量のイベントおよび metrics データを継続的に送信することがよくあります。このようなシナリオでは非同期挿入モードを利用できます。このモードでは、ClickHouse が同一テーブルに対する複数の INSERT からの行をバッファに蓄積し、バッファサイズが設定可能なしきい値を超えるか timeout が発生した時点でのみ新しい part を作成します。
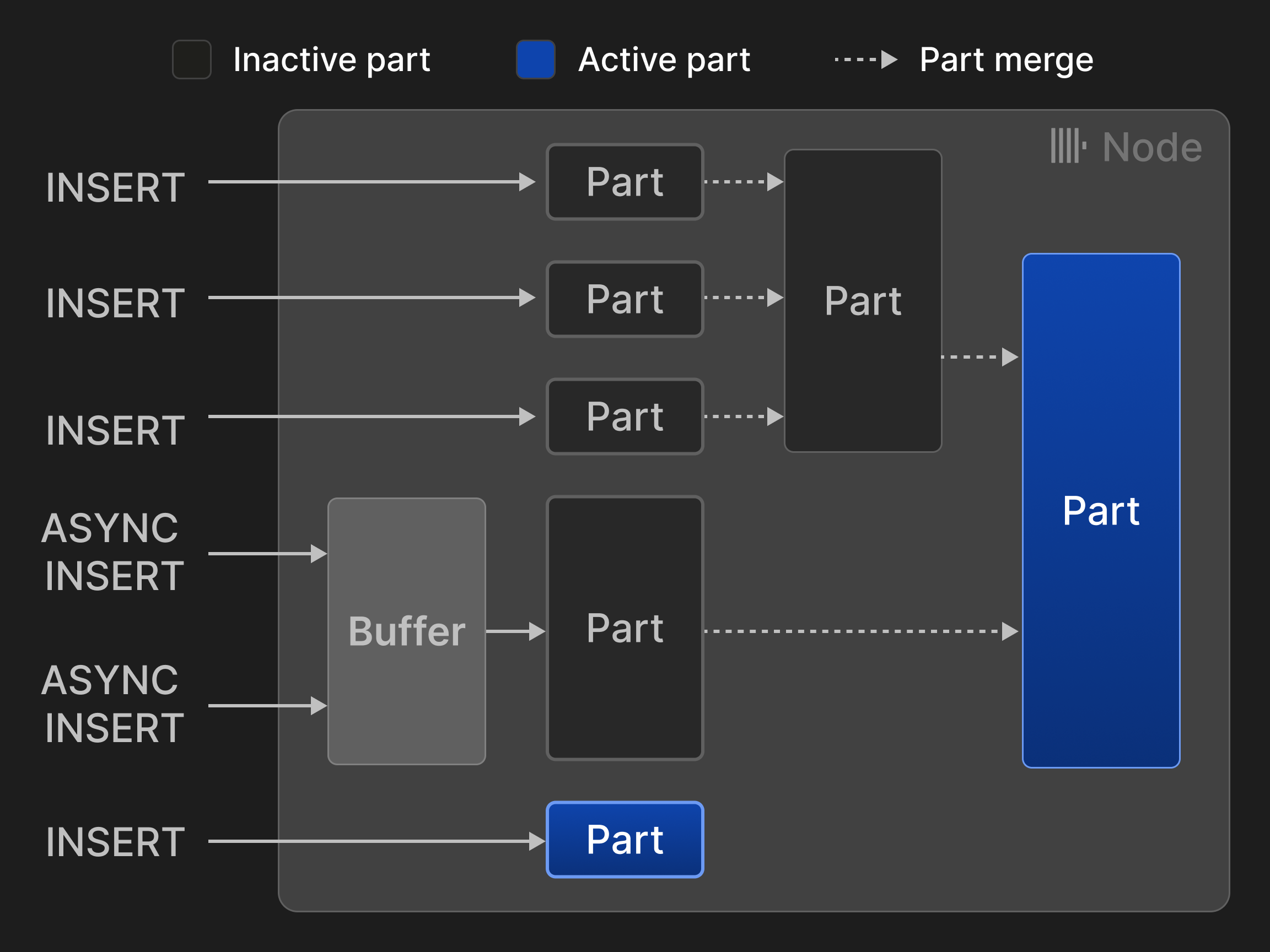
図 3: MergeTree* エンジンテーブルに対する挿入とマージ。
図 3 は、MergeTree* エンジンテーブルに対する 4 回の同期挿入と 2 回の非同期挿入を示しています。2 回のマージによって、アクティブな parts の数は、当初の 5 つから 2 つに削減されています。
LSM ツリー [58] と、その各種データベースでの実装 [13]、[26]、[56] と比較すると、ClickHouse はすべての parts を階層構造に配置するのではなく、同等のものとして扱います。その結果、マージは同じレベル内の parts に限定されなくなります。一方で、この方式では parts の暗黙的な時系列順序も放棄するため、トゥームストーンに依存しない更新および削除のための別のメカニズムが必要になります (3.4 節参照) 。ClickHouse は挿入データを直接ディスクに書き込みますが、他の LSM ツリーベースのストアは通常、書き込み前ログ (write-ahead logging) を使用します (3.7 節参照) 。
1 つの part はディスク上のディレクトリに対応し、その中には各列につき 1 つのファイルが含まれます。最適化として、小さな part (デフォルトでは 10 MB 未満) の列は、読み書き時の空間局所性を高めるため、1 つのファイル内に連続して格納されます。part の行はさらに論理的に 8192 レコードのグループ、すなわち granules に分割されます。granule は、ClickHouse のスキャンおよびインデックスルックアップ演算子が処理する、最小の分割不可能なデータ単位を表します。しかし、ディスク上データの読み書きは granule レベルではなく、複数の隣接する granules を列ごとにまとめた blocks の粒度で行われます。新しい blocks は、block あたりの設定可能なバイトサイズ (デフォルトでは 1 MB) に基づいて形成されます。つまり、block 内の granules 数は可変であり、列のデータ型と分布に依存します。さらに、ブロックはサイズと I/O コストを削減するために圧縮されます。デフォルトでは、ClickHouse は汎用の圧縮アルゴリズムとして LZ4 [75] を使用しますが、ユーザーは Gorilla [63] や FPC [12] など、浮動小数点データ向けの特殊なコーデックを指定することもできます。圧縮アルゴリズムはチェーンとして組み合わせることも可能です。例えば、まず delta coding [23] を用いて数値の論理的冗長性を削減し、その後重い圧縮処理を行い、最後に AES コーデックを用いてデータを暗号化することができます。ブロックはディスクからメモリに読み込まれる際にオンザフライで解凍されます。圧縮が行われていても個々の granules への高速なランダムアクセスを可能にするため、ClickHouse はさらに各列ごとに、各 granule ID を、その granule を含む圧縮 block の列ファイル内オフセットと、非圧縮 block 内での granule のオフセットとに対応付けるマッピングを保持します。
列はさらに辞書エンコード [2, 77, 81] したり、2 つの特別なラッパーデータ型を用いて nullable にすることができます。LowCardinality(T) は元の列の値を整数 ID に置き換えることで、一意な値が少ないデータに対するストレージのオーバーヘッドを大幅に削減します。Nullable(T) は列 T に内部ビットマップを追加し、列の各値が NULL かどうかを表します.
最後に、テーブルは任意のパーティション式を用いて、レンジ、ハッシュ、あるいはラウンドロビンでパーティション分割できます。パーティションプルーニングを有効にするために、ClickHouse は各パーティションごとにパーティション式の最小値および最大値も保持します。ユーザーはオプションで、カーディナリティ推定も提供する、より高度な列統計量 (例:HyperLogLog [30] や t-digest [28] 統計量) を作成できます。
3.2 データプルーニング
ほとんどのユースケースでは、1つのクエリに答えるためだけにPB級のデータをスキャンするのは、低速でコストもかかりすぎます。ClickHouseは、検索時に大部分の行をスキップできる3つのデータプルーニング手法をサポートしており、その結果、クエリを大幅に高速化できます。
まず、ユーザーはテーブルに主キー索引を定義できます。主キーカラムは各パート内での行のソート順を決定します。つまり、索引はローカルにクラスタ化されています。さらにClickHouseは、各パートについて、各granuleの先頭行の主キーカラム値からそのgranuleのidへのマッピングを格納します。つまり、この索引はスパースです [31]。この結果得られるデータ構造は通常、完全にメモリ内に保持できるほど小さく、たとえば810万行を索引付けするのに必要なentriesはわずか1000個です。主キーの主な目的は、順次スキャンではなく二分検索を使って、頻繁にフィルタリングされるカラムに対する等価述語や範囲述語を評価することです (Section 4.4)) 。さらに、このローカルソートはパートマージやクエリ最適化にも活用できます。たとえば、ソートベースの集計や、主キーカラムがソートカラムのプレフィックスを構成している場合に、物理実行計画からソートOperatorを取り除くことなどです。
Figure 4 は、ページインプレッション統計を持つテーブルのカラムEventTime上の主キー索引を示しています。クエリ内の範囲述語に一致するgranuleは、EventTimeを順次スキャンする代わりに、主キー索引を二分検索することで特定できます。

Figure 4: 主キー索引によるフィルタリングの評価。
次に、ユーザーはテーブルプロジェクション、すなわち異なる主キーでソートされた同じ行を含むテーブルの代替バージョンを作成できます [71]。プロジェクションを使うと、メインテーブルの主キーとは異なるカラムでフィルタリングするクエリを高速化できますが、その代償としてinsert、merge、および領域消費のオーバーヘッドが増加します。デフォルトでは、プロジェクションはメインテーブルに新たにinsertされたパーツからのみ遅延的に生成され、ユーザーがプロジェクション全体をマテリアライズしない限り、既存のパーツからは生成されません。クエリオプティマイザは、推定I/Oコストに基づいて、メインテーブルとプロジェクションのどちらから読み取るかを選択します。あるパートに対応するプロジェクションが存在しない場合、クエリ実行は対応するメインテーブルのパートにフォールバックします。
3つ目に、スキッピング索引は、プロジェクションに対する軽量な代替手段です。スキッピング索引の考え方は、複数の連続するgranuleのレベルで少量のmetadataを格納することで、無関係な行のスキャンを回避できるようにすることです。スキッピング索引は、任意の索引式に対して、設定可能なgranularity、すなわちスキッピング索引block内のgranule数を指定して作成できます。利用可能なスキッピング索引のtypeには次のものがあります。1. Min-max 索引 [51]: 各索引blockについて、索引式の最小値と最大値を格納します。この索引typeは、絶対範囲が小さいローカルにクラスタ化されたデータ、たとえば緩やかにソートされたデータに適しています。2. Set 索引: 設定可能な数の索引block内の一意な値を格納します。これらの索引は、ローカルcardinalityが小さいデータ、すなわち値が「ひとかたまりに集まっている」データに最適です。3. Bloom フィルター索引 [9]: 行、token、またはn-gram値に対して、設定可能な偽陽性率で構築されます。これらの索引はテキスト検索をサポートします [73] が、min-max索引やSet 索引とは異なり、範囲述語や否定述語には使用できません。
3.3 Merge-time Data Transformation
ビジネスインテリジェンスやオブザーバビリティのユースケースでは、常に高レートで、あるいはバースト的に生成されるデータを扱う必要があることが多くあります。また、履歴データよりも、直近で生成されたデータの方が、リアルタイムな分析において意味のあるインサイトを得るうえで一般的に重要です。このようなユースケースでは、データベースが高いデータインジェストレートを維持しつつ、集約処理やデータエージングのような手法を通じて履歴データのボリュームを継続的に削減することが求められます。ClickHouse は、さまざまなマージ戦略を用いて既存データを継続的かつインクリメンタルに変換することを可能にします。マージ時のデータ変換は INSERT 文のパフォーマンスを損なうことはありませんが、テーブルに不要な値 (例: 古い値や非集約の値) が一切含まれないことを保証するものではありません。必要に応じて、すべてのマージ時変換は、SELECT 文でキーワード FINAL を指定することで、クエリ時に適用できます。
Replacing マージ は、含まれるパーツの作成タイムスタンプに基づいて、タプルのうち最も最近挿入されたバージョンのみを保持し、古いバージョンを削除します。タプルは、primary key 列の値が同じ場合に等価と見なされます。どのタプルを保持するかを明示的に制御するために、比較用の特別なバージョン列を指定することも可能です。Replacing マージは、マージ時の更新メカニズムとして一般的に使われます (通常は更新が頻繁に発生するユースケース) 、または挿入時のデータ重複排除 (セクション 3.5) の代替として用いられます。
Aggregating マージ は、primary key 列の値が等しい行を 1 行の集約行にまとめます。primary key 以外の列は、サマリ値を保持する部分集約状態でなければなりません。2 つの部分集約状態、たとえば avg() のための sum と count を、新しい部分集約状態に結合します。Aggregating マージは、通常のテーブルではなくマテリアライズドビューで利用されることが一般的です。マテリアライズドビューは、ソーステーブルに対する変換クエリに基づいてデータが投入されます。他のデータベースとは異なり、ClickHouse はソーステーブル全体の内容を用いてマテリアライズドビューを定期的にリフレッシュすることはありません。マテリアライズドビューは、新しいパーツがソーステーブルに挿入されたときに、その変換クエリの結果でインクリメンタルに更新されます。
Figure 5 は、ページインプレッション統計を持つテーブル上に定義された materialized view を示しています。ソーステーブルに新しい parts が挿入されると、変換クエリはリージョンごとにグループ化された最大レイテンシと平均レイテンシを計算し、その結果を materialized view に挿入します。集約関数 avg() および max() に -State 拡張を付けたものは、実際の結果ではなく部分集約状態を返します。materialized view に対して定義された aggregating マージは、異なる parts の部分集約状態を継続的に結合します。最終結果を得るには、ユーザーは materialized view 内の部分集約状態に対して、-Merge 拡張付きの avg() および max() を用いて集約を行います。
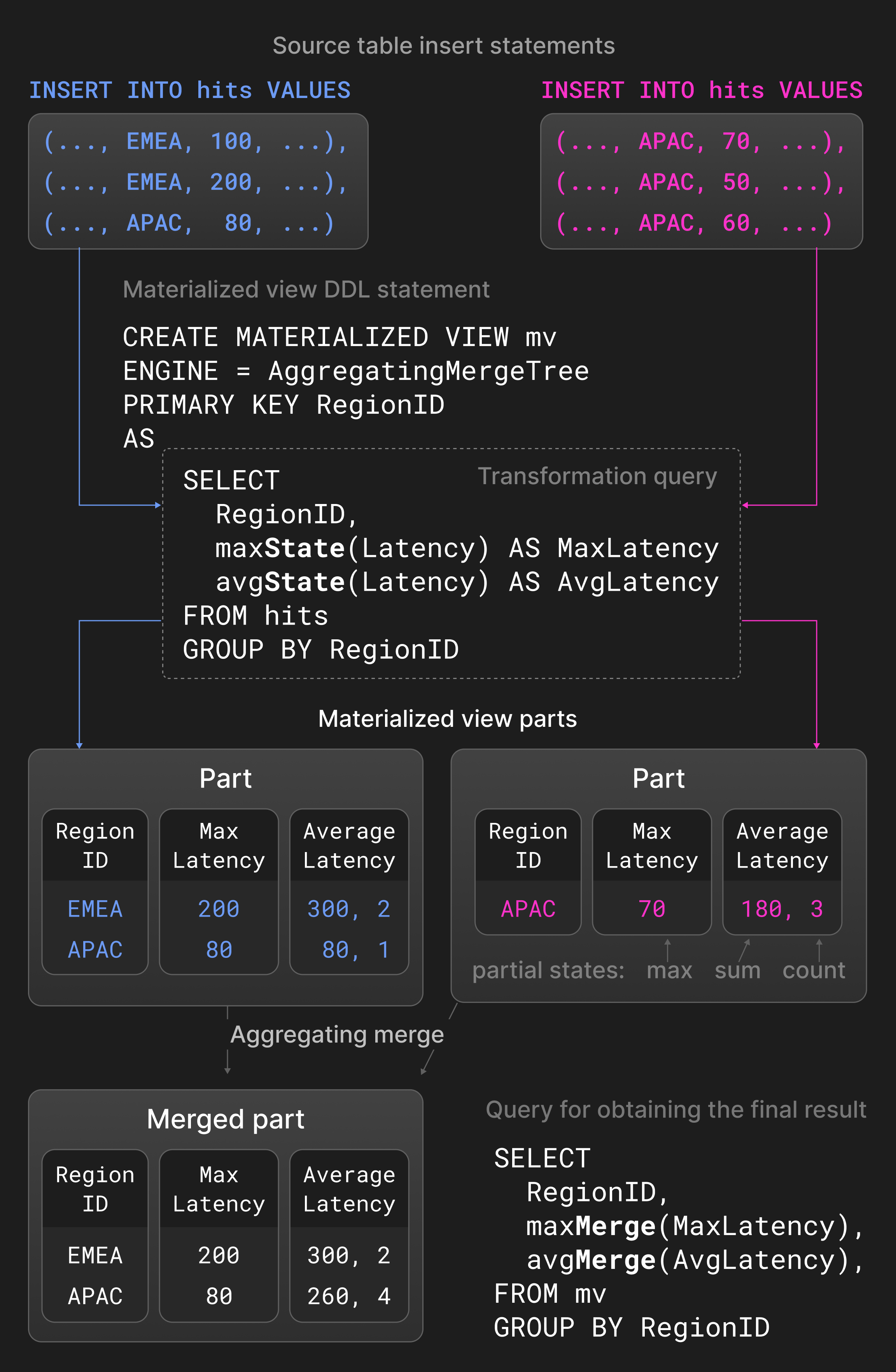
Figure 5: マテリアライズドビューにおける Aggregating マージ。
TTL (time-to-live) マージ は、履歴データに対するエージング処理を提供します。削除や集約を行うマージとは異なり、TTL マージは一度に 1 つのパーツのみを処理します。TTL マージは、トリガーとアクションから構成されるルールによって定義されます。トリガーは、各行に対してタイムスタンプを計算する式であり、その値は TTL マージが実行される時刻と比較されます。これは行粒度でアクションを制御することを可能にしますが、すべての行がある条件を満たしているかどうかを確認し、その条件を満たす場合にパーツ全体に対してアクションを実行するだけで十分であることが分かりました。可能なアクションには、1. パーツを別のボリュームに移動する (例: より安価で低速なストレージ) 、2. パーツを再圧縮する (例: より重いコーデックを使用) 、3. パーツを削除する、4. ロールアップ、すなわちグルーピングキーと集約関数を用いて行を集約する、が含まれます。
例として、Listing 1. のログテーブル定義を考えます。ClickHouse は、timestamp 列の値が 1 週間より古い parts を、低速だがコストの安い S3 オブジェクトストレージに移動します。
Listing 1: パートを1週間後にオブジェクトストレージへ移動する。
3.4 更新と削除
MergeTree* テーブルエンジンの設計は追記専用ワークロードを前提としていますが、コンプライアンス要件などの理由で既存データをときどき変更する必要があるユースケースも存在します。データの更新や削除には 2 つのアプローチがあり、どちらも並列での挿入をブロックしません。
Mutation はテーブルのすべての parts をインプレースで書き換えます。テーブル (削除) またはカラム (更新) のサイズが一時的に 2 倍になるのを防ぐために、この処理は非アトミックです。つまり、並列な SELECT ステートメントは、変更済みと未変更の parts の両方を読み取る可能性があります。Mutation は、処理の終了時点でデータが物理的に変更されていることを保証します。削除の Mutation は、すべての parts 内のすべてのカラムを書き換える必要があるため、依然として高コストです。
代替手段として、lightweight delete は内部のビットマップカラムのみを更新し、行が削除されているかどうかを示します。ClickHouse は SELECT クエリにビットマップカラムに対する追加フィルタを付加し、削除済み行を結果から除外します。削除済み行が物理的に削除されるのは、将来の不特定のタイミングで行われる通常のマージ処理のときだけです。カラム数にもよりますが、lightweight delete は、SELECT が遅くなる代わりに、Mutation より大幅に高速になる場合があります。
同じテーブルに対する更新および削除処理は、論理的な競合を避けるため、発生頻度が低く、直列に実行されることが想定されています。
3.5 冪等な挿入
実運用で頻繁に発生する問題として、クライアントがテーブルへのデータ送信後に接続タイムアウトにどのように対処すべきか、というものがあります。この状況では、クライアントはデータが正常に挿入されたかどうかを判別することが困難です。この問題は従来、クライアントからサーバーへデータを再送し、主キーや一意制約に依存して重複した挿入を拒否することで解決してきました。データベースは、二分木ベースのインデックス構造 [39, [68]](#page-13-16)、radix 木 [45]、またはハッシュテーブル [29] を用いて、必要なポイント検索を高速に実行します。これらのデータ構造はすべてのタプルをインデックスするため、大規模なデータセットや高い取り込みレートに対しては、空間および更新のオーバーヘッドが過大になります。
ClickHouse は、各挿入が最終的に 1 つのパートを作成するという事実に基づき、より軽量な代替手段を提供します。より具体的には、サーバーは直近 N 個の挿入済みパーツ (例: N=100) のハッシュを保持し、既知のハッシュを持つパーツの再挿入を無視します。非レプリケートテーブルとレプリケートテーブルのハッシュは、それぞれローカルと Keeper に保存されます。その結果、挿入は冪等になり、すなわちクライアントはタイムアウト後に同じ行のバッチを単純に再送し、サーバー側で重複排除が行われるとみなすことができます。重複排除処理をより細かく制御するために、クライアントはオプションで、パートハッシュとして機能する挿入トークンを指定できます。ハッシュベースの重複排除では、新しい行のハッシュ計算に伴うオーバーヘッドは発生しますが、ハッシュの保存および比較のコストは無視できる程度です。
3.6 Data Replication
レプリケーションは高可用性 (ノード障害に対する耐性) の前提条件であるだけでなく、負荷分散やゼロダウンタイムでのアップグレード [14] にも使用されます。ClickHouse におけるレプリケーションは、テーブルのパーツ (3.1 セクション) と、カラム名や型といったテーブルメタデータからなるテーブル状態という概念に基づいています。ノードは次の 3 つの操作でテーブル状態を更新します。1. Insert は状態に新しいパートを追加し、2. merge は新しいパートを追加し、既存のパーツを状態に追加または状態から削除し、3. mutation と DDL 文は、具体的な操作内容に応じてパーツを追加し、および/または削除し、および/またはテーブルメタデータを変更します。これらの操作は単一ノード上でローカルに実行され、グローバルなレプリケーションログ内の状態遷移のシーケンスとして記録されます。
レプリケーションログは、通常 3 つの ClickHouse Keeper プロセスからなるアンサンブルによって維持されます。これらは Raft コンセンサスアルゴリズム [59] を用いて、ClickHouse ノードのクラスタに対する分散かつフォールトトレラントな調整レイヤーを提供します。すべてのクラスタノードは、初期状態ではレプリケーションログ内の同じ位置を指します。ノードがローカルで insert、merge、mutation、DDL 文を実行している間、レプリケーションログは他のすべてのノード上で非同期にリプレイされます。その結果、レプリケーションされたテーブルは最終的整合性のみを満たす状態となり、すなわちノードは最新状態へと収束している間、一時的に古いテーブル状態を読み取る可能性があります。前述のほとんどの操作は、代わりに同期的に実行することもでき、その場合はノードのクォーラム (例: ノードの過半数または全ノード) が新しい状態を採用するまで待機します。
例として、Figure 6 は、3 つの ClickHouse ノードからなるクラスタ内の、初期状態が空のレプリケーションされたテーブルを示します。まず Node 1 が 2 つの insert 文を受信し、それらを Keeper アンサンブルに格納されたレプリケーションログ内に記録します ( 1 2 )。次に Node 2 は、最初のログエントリをフェッチして ( 3 )、Node 1 から新しいパートをダウンロードすることで ( 4 ) それをリプレイします。一方、Node 3 は両方のログエントリをリプレイします ( 3 4 5 6 )。最後に Node 3 は両方のパーツを 1 つの新しいパートにマージし、入力となったパーツを削除し、レプリケーションログに merge エントリを記録します ( 7 )。

Figure 6: 3 つのノードからなるクラスタにおけるレプリケーション。
同期を高速化するための 3 つの最適化が存在します。第一に、クラスタに新しく追加されたノードは、レプリケーションログを最初からリプレイするのではなく、最後のレプリケーションログエントリを書き込んだノードの状態をそのままコピーします。第二に、merge はローカルで再実行してリプレイするか、別のノードから結果のパートを取得することでリプレイされます。正確な挙動は設定可能で、CPU 消費量とネットワーク I/O のバランスを調整できます。たとえば、データセンター間レプリケーションでは、運用コストを最小化するためにローカルでの merge が優先されるのが一般的です。第三に、ノードは互いに独立したレプリケーションログエントリを並列にリプレイします。これには、例えば同一テーブルに連続して挿入された新しいパーツのフェッチや、異なるテーブル上での操作が含まれます。
3.7 ACID 準拠
同時実行される読み取りおよび書き込み処理のパフォーマンスを最大化するため、ClickHouse は可能な限りラッチの取得を回避します。クエリは、クエリ開始時点で作成された、関係するすべてのテーブル内のすべてのパーツのスナップショットに対して実行されます。これにより、並列な INSERT やマージ (セクション 3.1) によって新たに挿入されたパーツは実行の対象になりません。パーツが同時に変更または削除されることを防ぐため (セクション 3.4)、処理対象のパーツの参照カウントはクエリの実行期間中インクリメントされます。形式的には、これはバージョン付きパーツに基づく MVCC の一種 [6] によって実現されるスナップショット分離に相当します。その結果、スナップショット取得時点に行われている並行書き込みが、それぞれ単一のパートのみにしか影響しないというまれなケースを除き、ステートメントは一般に ACID 準拠ではありません。
実際には、ClickHouse のほとんどの書き込み負荷の高い意思決定支援系ユースケースでは、停電時に新しいデータが一部失われる小さなリスクは許容されます。データベースはこの点を利用し、新規に挿入されたパーツをデフォルトではディスクにコミット (fsync) することを強制せず、その代わりにアトミシティ (原子性) を犠牲にしてカーネルが書き込みをバッチ処理できるようにしています。
4 クエリ処理レイヤー
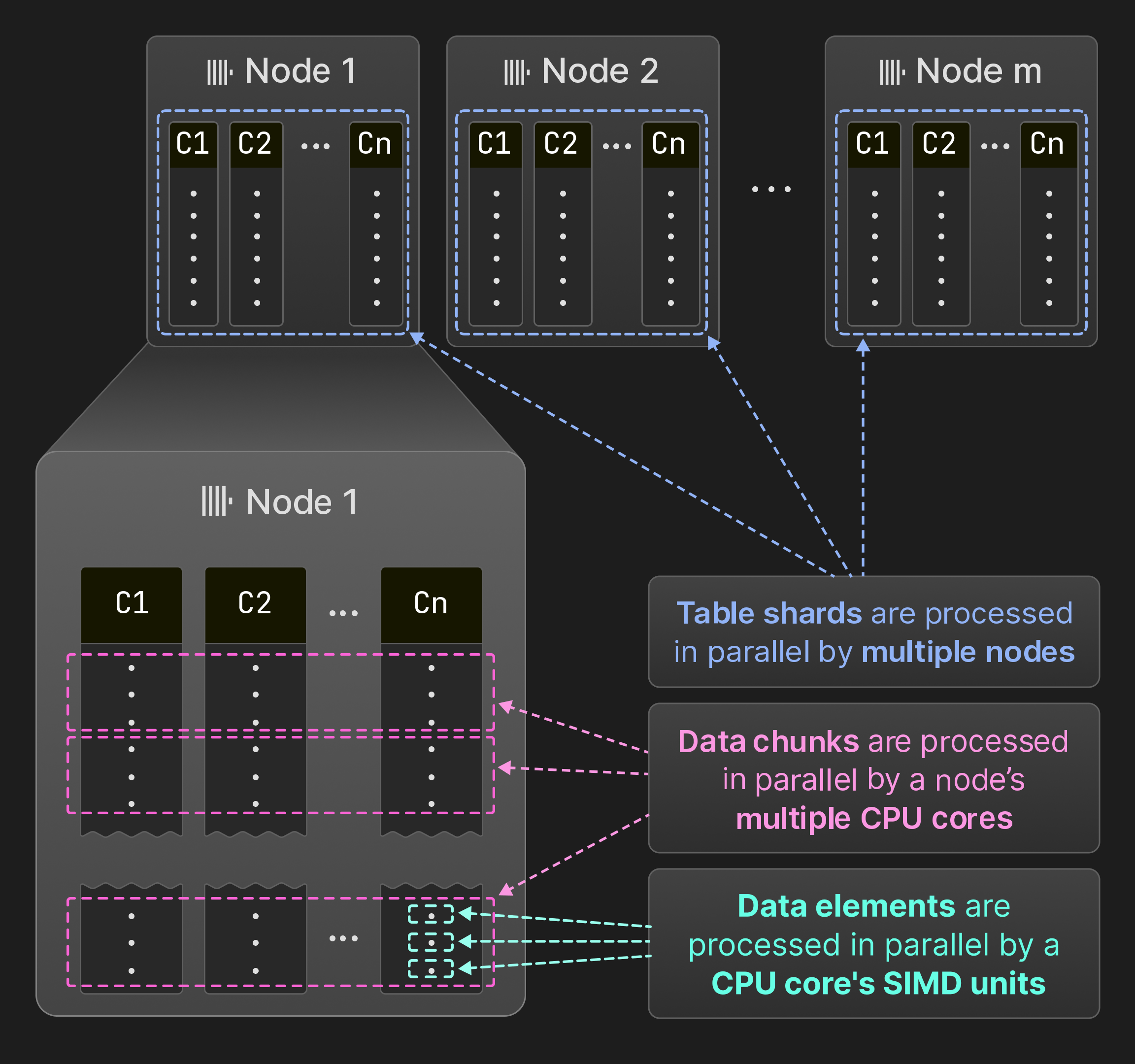
図 7: SIMD ユニット、コア、ノード間での並列化。
図 7 に示すように、ClickHouse はクエリをデータ要素、データチャンク、およびテーブルシャードのレベルで並列化します。複数のデータ要素は、SIMD 命令を用いることでオペレーター内で一度に処理できます。単一ノード上では、クエリエンジンは複数スレッドでオペレーターを同時に実行します。ClickHouse は MonetDB/X100 [11] と同じベクトル化モデルを採用しており、オペレーターは仮想関数呼び出しのオーバーヘッドを最小化するために、単一行ではなく複数行 (データチャンク) を生成・受け渡し・消費します。ソーステーブルが互いに重ならないテーブルシャードに分割されている場合、複数ノードが同時にそれぞれのシャードをスキャンできます。その結果、すべてのハードウェアリソースが十分に活用され、ノードを追加することで水平方向に、コアを追加することで垂直方向にクエリ処理をスケールできます。
本節の残りでは、まずデータ要素、データチャンク、および shard の粒度での並列処理について詳しく説明します。次に、クエリ性能を最大化するための主要な最適化のいくつかを示します。最後に、複数のクエリが同時に実行されている状況で、ClickHouse が共有システムリソースをどのように管理するかについて説明します。
4.1 SIMD Parallelization
オペレーター間で複数行を渡すことで、ベクトル化する余地が生まれます。ベクトル化は、手書きのイントリンシック命令 [64, [80]](#page-13-19) に基づく場合と、コンパイラの自動ベクトル化 [25] に基づく場合があります。ベクトル化の恩恵を受けるコードは、異なる計算カーネルとしてコンパイルされます。例えば、クエリオペレーターの内部にあるホットループは、非ベクトル化カーネル、自動ベクトル化された AVX2 カーネル、および手動でベクトル化した AVX-512 カーネルとして実装できます。最も高速なカーネルは、cpuid 命令に基づいて実行時に選択されます。このアプローチにより、ClickHouse は(SSE 4.2 を最低要件としつつ)最長 15 年前のような古いシステム上でも動作可能であり、最新ハードウェア上では大きな高速化を提供できます。
4.2 Multi-Core Parallelization
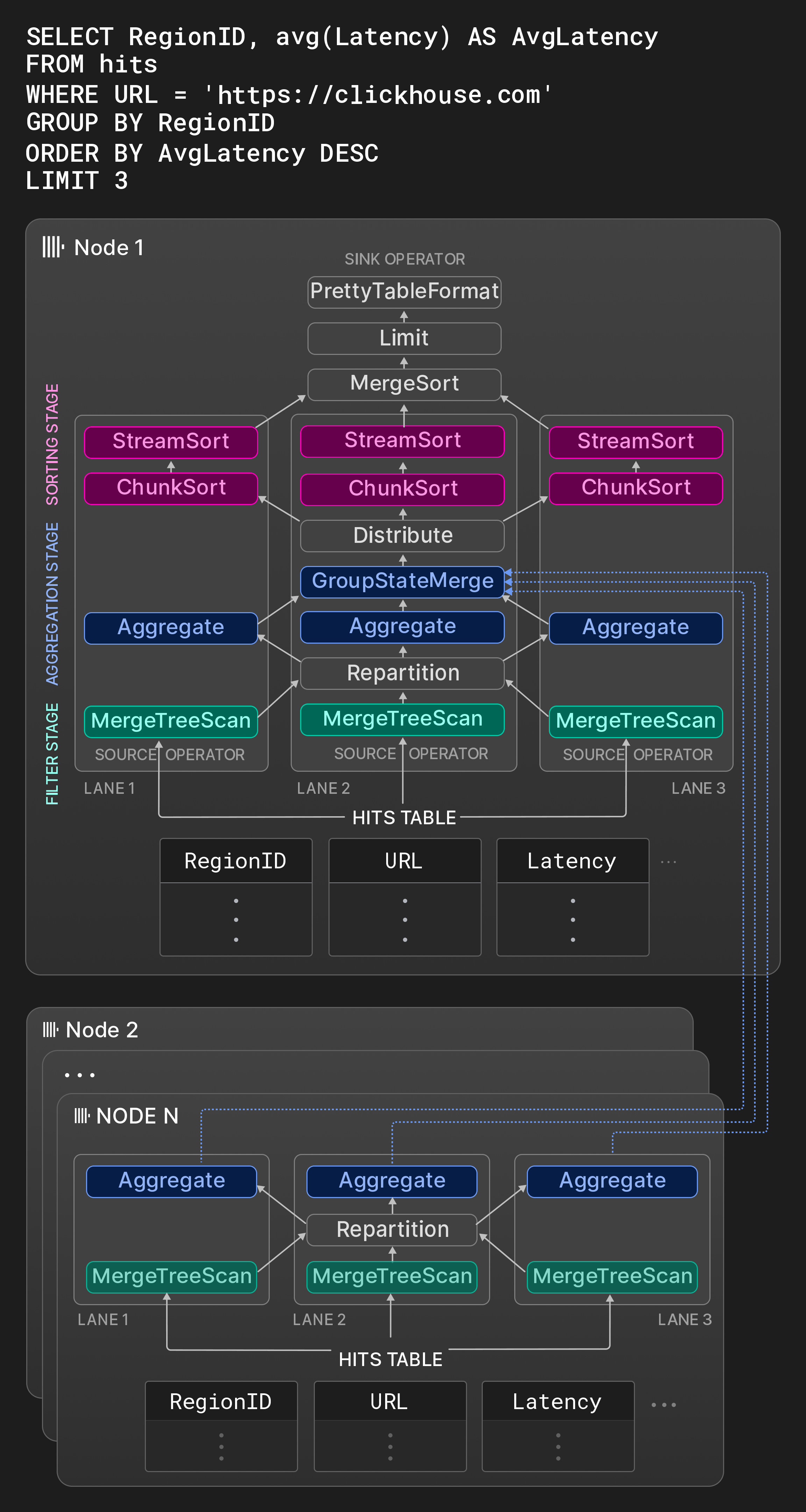
図 8: 3 本のレーンから成る物理オペレータプラン。
ClickHouse は、SQL クエリを物理プランオペレータの有向グラフに変換するという従来のアプローチ [31] を採用しています。オペレータプランの入力は、ネイティブ形式またはサポートされているサードパーティ形式(セクション 5) 参照)でデータを読み取る特別なソースオペレータによって表現されます。同様に、特別なシンクオペレータが結果を要求される出力形式に変換します。物理オペレータプランは、クエリのコンパイル時に、設定可能なワーカースレッドの最大数(デフォルトではコア数)とソーステーブルサイズに基づいて、互いに独立した実行レーンに展開されます。レーンは、並列オペレータが処理するデータを互いに重ならない範囲に分解します。並列処理の機会を最大化するため、レーンは可能な限り遅いステージまでマージされません。
例として、図 8 の Node 1 のボックスは、ページインプレッション統計を格納したテーブルに対する典型的な OLAP クエリのオペレータグラフを示しています。第 1 ステージでは、ソーステーブルの 3 つの互いに重ならない範囲が同時にフィルタ処理されます。Repartition 交換オペレータは、第 1 ステージと第 2 ステージの間で結果チャンクを動的にルーティングし、処理スレッドの利用度を均等に保ちます。スキャンされた範囲の選択度が大きく異なる場合、第 1 ステージの後でレーン間の負荷が不均衡になることがあります。第 2 ステージでは、フィルタを通過した行が RegionID ごとにグループ化されます。Aggregate オペレータは、RegionID をグルーピング列とし、avg() の部分集約状態としてグループごとの合計と件数を持つローカルな結果グループを維持します。ローカルな集約結果は最終的に、GroupStateMerge オペレータによってマージされ、グローバルな集約結果になります。このオペレータはパイプラインブレーカでもあり、すなわち、第 3 ステージは集約結果の計算が完全に完了した後にのみ開始できます。第 3 ステージでは、まず Distribute 交換オペレータによって結果グループが大きさの等しい 3 つの互いに重ならないパーティションに分割され、その後 AvgLatency でソートされます。ソートは 3 ステップで行われます。まず、ChunkSort オペレータが各パーティションの個々のチャンクをソートします。次に、StreamSort オペレータがローカルなソート済み結果を保持し、到着するソート済みチャンクを 2-way マージソートで統合します。最後に、MergeSort オペレータが k-way ソートを用いてこれらのローカル結果を結合し、最終結果を得ます。
オペレータはステートマシンであり、入出力ポートを介して互いに接続されています。オペレータの取りうる 3 つの状態は、need-chunk、ready、done です。need-chunk から ready への遷移を行うには、オペレータの入力ポートにチャンクを配置します。ready から done への遷移を行うには、オペレータが入力チャンクを処理し、出力チャンクを生成します。done から need-chunk への遷移を行うには、オペレータの出力ポートから出力チャンクを取り除きます。接続された 2 つのオペレータにおける 1 番目と 3 番目の状態遷移は、結合された 1 つのステップとしてのみ実行できます。ソースオペレータ(シンクオペレータ)は ready と done(need-chunk と done)の状態のみを持ちます。
ワーカースレッドは物理オペレータプランを継続的に走査し、状態遷移を実行します。CPU キャッシュを有効に活用するため、同じスレッドが同一レーン内の連続したオペレータを処理すべきであるというヒントがプラン内に含まれています。並列処理は、ステージ内の互いに重ならない入力に対して水平方向に(例として、図 8 では Aggregate オペレータが並行実行されています)、およびパイプラインブレーカで分割されていないステージ間で垂直方向に(例として、図 8 では同一レーン内の Filter と Aggregate オペレータが同時に実行可能です)行われます。新しいクエリの開始時や同時実行中のクエリの終了時にスレッドの過剰割り当てや過少割り当てを避けるため、並列度はクエリ実行中に、クエリ開始時に指定されたそのクエリに対する最大ワーカースレッド数と 1 の間で変更することができます(セクション 4.5) 参照)。
さらにオペレータは、ランタイムにおけるクエリ実行に 2 つの方法で影響を与えることができます。第 1 に、オペレータは新しいオペレータを動的に生成し、接続できます。これは主に、メモリ使用量が設定可能な閾値を超えた際にクエリをキャンセルする代わりに、外部集約・ソート・結合アルゴリズムへ切り替えるために使用されます。第 2 に、オペレータはワーカースレッドに対して、非同期キューへ移動するよう要求できます。これは、リモートデータの待機中にワーカースレッドをより効果的に活用するのに役立ちます。
ClickHouse のクエリ実行エンジンと morsel-driven parallelism [44] は、レーンが通常は異なるコア/NUMA ソケット上で実行され、ワーカースレッドが他のレーンからタスクを盗むことができるという点で類似している。また、集中型のスケジューリングコンポーネントは存在せず、ワーカースレッドがオペレータプランを継続的に走査することで、それぞれが個別にタスクを選択する。morsel-driven parallelism と異なり、ClickHouse は最大並列度をプラン自体に織り込み、ソーステーブルの分割においては、デフォルトの morsel サイズ(約 100,000 行)と比べてはるかに大きな範囲を用いる。このことは場合によっては(例えば、異なるレーンにおける filter オペレータの実行時間が大きく異なるときに)処理の停滞を引き起こす可能性があるが、Repartition のような exchange オペレータを広く活用することで、少なくともステージ間で不均衡が累積することは防げると考えられる。
4.3 マルチノード並列化
クエリのソーステーブルがシャーディングされている場合、そのクエリを受け取ったノード(イニシエーターノード)のクエリオプティマイザは、可能な限り多くの処理を他のノードで実行しようとします。他のノードからの結果は、クエリプランのさまざまなポイントに統合されます。クエリの内容に応じて、リモートノードは次のいずれかを行います。1. ソーステーブルの生の列データをイニシエーターノードにストリーミングする、2. ソース列をフィルタリングして条件を満たした行のみを送信する、3. フィルタと集約ステップを実行し、部分的な集約状態を含むローカルの結果グループを送信する、4. フィルタ・集約・ソートを含むクエリ全体を実行する。
Figure 8 におけるノード 2 ~ N は、hits テーブルのシャードを保持する他のノードで実行されるプランフラグメントを示しています。これらのノードはローカルデータをフィルタおよびグループ化し、その結果をイニシエーターノードへ送信します。ノード 1 上の GroupStateMerge 演算子は、結果グループが最終的にソートされる前に、ローカル結果とリモート結果をマージします。
4.4 ホリスティックなパフォーマンス最適化
本節では、クエリ実行のさまざまな段階に適用される主要なパフォーマンス最適化のうち、代表的なものを示します。
クエリ最適化。最初の一連の最適化は、クエリの AST から得られたセマンティックなクエリ表現に対して適用されます。このような最適化の例としては、定数畳み込み (例: concat(lower('a'),upper('b')) が 'aB' になる) 、特定の集約関数からスカラーを外に出すこと (例: sum(a2) が 2 * sum(a) になる) 、共通部分式の除去、等値フィルタの論理和を IN リストへ変換すること (例: x=c OR x=d が x IN (c,d) になる) などがあります。最適化されたセマンティックなクエリ表現は、その後論理オペレータプランに変換されます。論理プランに対する最適化には、フィルタのプッシュダウン、関数評価とソート処理のステップの順序変更などが含まれ、どちらの処理コストが高いと見積もられるかに応じて決定されます。最後に、論理クエリプランは物理オペレータプランへと変換されます。この変換では、関与するテーブルエンジンの特性を活用できます。たとえば MergeTree-table engine の場合、ORDER BY 列が primary key のプレフィックスを構成していれば、ディスク上の順序でデータを読み出すことができ、プランからソートオペレータを削除できます。また、集約におけるグルーピング列が primary key のプレフィックスを構成する場合、ClickHouse はソート集約 [33] を利用できます。つまり、あらかじめソートされた入力において、同一値の連続区間を直接集約します。ハッシュ集約と比較して、ソート集約はメモリ消費が大幅に少なく、連続区間の処理が完了するとすぐに集約値を次のオペレータへ渡すことができます。
クエリコンパイル。ClickHouse は LLVM ベースのクエリコンパイル を利用して、隣接するプランオペレータを動的に融合します [38, [53]](#page-13-0)。たとえば、式 a * b + c + 1 は、3 つのオペレータではなく 1 つのオペレータにまとめることができます。式だけでなく、ClickHouse は複数の集約関数を一度に評価する場合 (すなわち GROUP BY の場合) や、複数のソートキーを持つソート処理にもコンパイルを用います。クエリコンパイルにより仮想関数呼び出しの回数が減り、データをレジスタや CPU キャッシュ内に保持しやすくなり、実行すべきコード量が減ることでブランチ予測にも寄与します。さらに、実行時コンパイルにより、論理最適化やコンパイラに実装されたピープホール最適化など、豊富な最適化が可能となり、ローカルで利用可能な最速の CPU 命令を利用できます。コンパイルは、同じ通常の式、集約式、またはソート式が、設定可能な回数を超えて複数のクエリで実行されたときにのみ開始されます。コンパイルされたクエリオペレータはキャッシュされ、将来のクエリで再利用できます.[7]
Primary key インデックス評価。ClickHouse は、WHERE 条件に含まれるフィルタ句のうち、条件の連言標準形における一部の句が primary key 列のプレフィックスを構成する場合、その条件を primary key インデックスを使って評価します。primary key インデックスは、キー値の辞書式順序でソートされた範囲を左から右へと解析します。primary key 列に対応するフィルタ句は三値論理で評価され、その範囲内の値に対して「すべて真」「すべて偽」「真と偽が混在」のいずれかになります。最後のケースでは、その範囲をサブレンジに分割し、再帰的に解析します。フィルタ条件内の関数に対しては、追加の最適化が存在します。まず、関数には単調性を表す属性が付与されます。たとえば toDayOfMonth(date) は 1 か月の範囲内では区分的に単調です。単調性属性により、ソートされた入力キー範囲に対して、その関数がソートされた結果を生成するかどうかを推論できます。次に、一部の関数は、与えられた関数結果に対する逆像を計算できます。これは、キー列に対する関数呼び出しと定数との比較を、キー列値とその逆像との比較に置き換えるために利用されます。たとえば、toYear(k) = 2024 は k >= 2024-01-01 && k < 2025-01-01 に置き換えることができます。
データスキップ。ClickHouse は、3.2 節 で紹介したデータ構造を利用して、クエリ実行時のデータ読み取りを可能な限り回避します。加えて、異なる列に対するフィルタは、ヒューリスティクスおよび (オプションの) 列統計量に基づく推定選択度の高い順に、逐次的に評価されます。少なくとも 1 行のマッチする行を含むデータチャンクだけが次の述語に渡されます。これにより、述語ごとに読み取るデータ量と実行すべき計算量が段階的に削減されます。この最適化は、少なくとも 1 つの高選択度な述語が存在する場合にのみ適用されます。そうでない場合、すべての述語を並列に評価する場合と比べて、クエリのレイテンシが悪化してしまうためです。
ハッシュテーブル。ハッシュテーブルは、集約やハッシュ結合のための基本的なデータ構造です。適切な種類のハッシュテーブルを選択することは性能にとって極めて重要です。ClickHouse は、汎用的なハッシュテーブルテンプレートから、ハッシュ関数、アロケータ、セル型、リサイズポリシーをバリエーションポイントとして、さまざまなハッシュテーブル(2024 年 3 月時点で 30 種類以上)をインスタンス化します。グループ化列のデータ型、推定されるハッシュテーブルのカーディナリティ、その他の要因に応じて、各クエリオペレーターごとに最速のハッシュテーブルが個別に選択されます。ハッシュテーブルに対しては、さらに次のような最適化が実装されています。
- 巨大なキー集合をサポートするための、256 個のサブテーブル(ハッシュ値の先頭 1 バイトに基づく)を持つ 2 レベル構成、
- 4 つのサブテーブルを持ち、文字列長に応じて異なるハッシュ関数を用いる文字列ハッシュテーブル [79],
- キー数が少ない場合に、キーをそのままバケットインデックスとして使用する(すなわちハッシュ化を行わない)ルックアップテーブル、
- 比較コストが高い場合(例: 文字列、AST)に、より高速な衝突解決のためにハッシュ値を値に埋め込む方式、
- 実行時統計から予測されるサイズに基づくハッシュテーブルの作成による、不必要なリサイズの回避、
- 同一の生成/破棄ライフサイクルを持つ複数の小さなハッシュテーブルを 1 つのメモリスラブ上に割り当てる方式、
- ハッシュマップ単位およびセル単位のバージョンカウンタを用いた、再利用のためのハッシュテーブルの即時クリア、
- キーをハッシュ化した後の値の取得を高速化するための CPU プリフェッチ(
__builtin_prefetch)の利用。
結合 (Joins)。ClickHouse は当初、結合を簡易的にしかサポートしていなかったため、歴史的には多くのユースケースで非正規化テーブルが利用されていました。現在では、このデータベースは、SQL で利用可能なすべての結合タイプ(inner、left-/right/full outer、cross、as-of)に加え、ハッシュ結合(naïve、grace)、ソートマージ結合、キー・バリュー検索が高速なテーブルエンジン(通常は辞書)向けのインデックス結合など、さまざまな結合アルゴリズムを提供しています。
結合はデータベース操作の中でも最も高コストなものの 1 つであるため、古典的な結合アルゴリズムの並列バリアントを、理想的には空間/時間トレードオフを設定可能な形で提供することが重要です。ハッシュ結合に対して、ClickHouse は [7] で提案されているノンブロッキングな共有パーティションアルゴリズムを実装しています。たとえば、図 9 のクエリは、ページヒット統計テーブルに対する自己結合を通じて、ユーザーが URL 間をどのように移動するかを計算します。結合のビルドフェーズは 3 つのレーンに分割され、ソーステーブルの互いに重ならない 3 つの範囲をそれぞれ処理します。グローバルなハッシュテーブルの代わりに、パーティション化されたハッシュテーブルが使用されます。(通常 3 つの)ワーカースレッドは、ハッシュ関数の結果に対するモジュロ演算を計算することで、ビルド側の各入力行のターゲットパーティションを決定します。ハッシュテーブルパーティションへのアクセスは Gather Exchange オペレーターを用いて同期されます。プローブフェーズは、入力タプルのターゲットパーティションを同様の方法で見つけます。このアルゴリズムは、タプルあたり 2 回の追加ハッシュ計算を導入する一方で、ハッシュテーブルパーティションの数に応じて、ビルドフェーズにおけるラッチ競合を大幅に削減します。
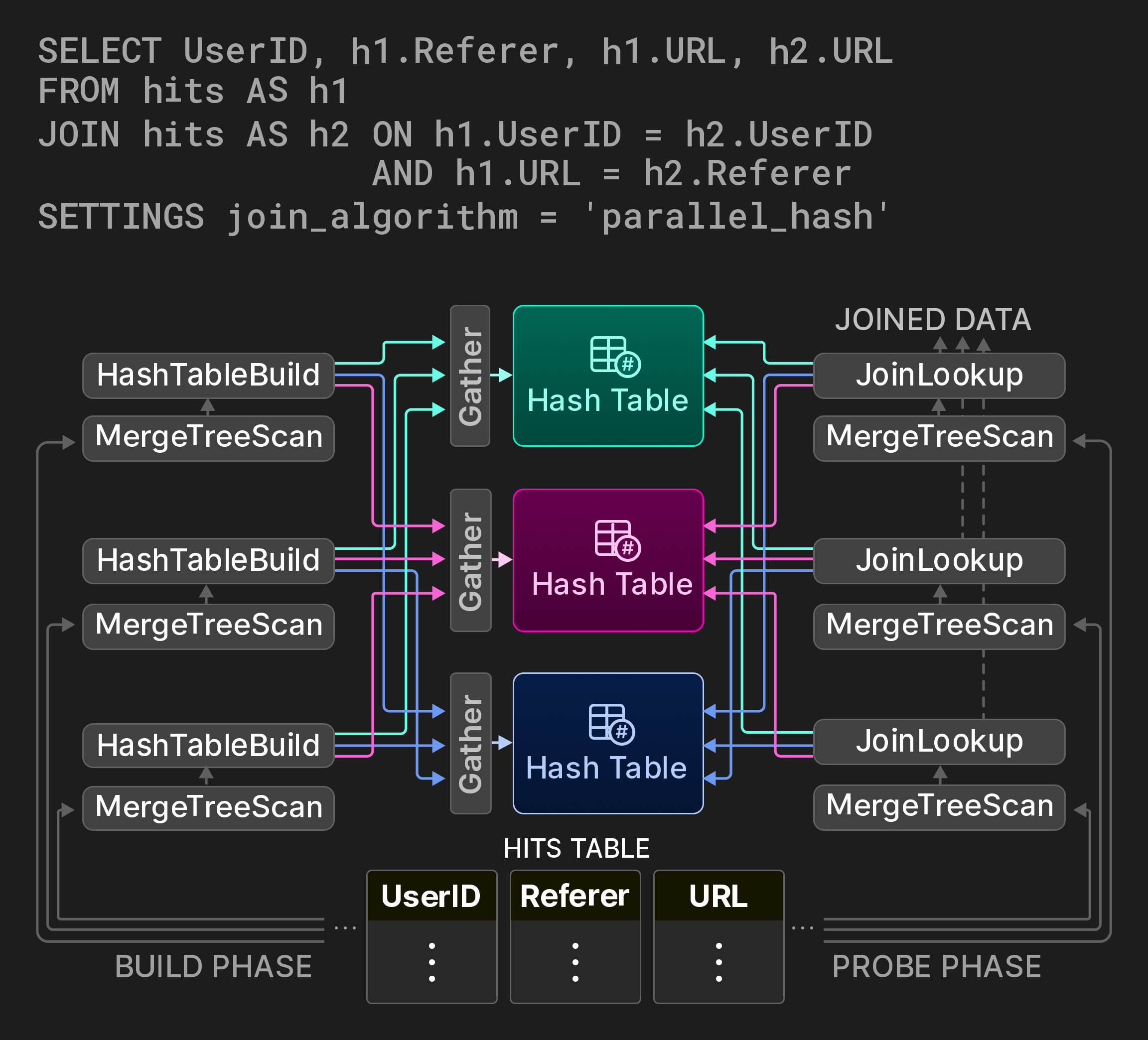
図 9: 3 つのハッシュテーブルパーティションによる並列ハッシュ結合。
4.5 ワークロード分離
ClickHouse は同時実行制御、メモリ使用量の上限設定、および I/O スケジューリングを提供し、ユーザーがクエリをワークロードクラスごとに分離できるようにします。特定のワークロードクラスに対して共有リソース(CPU コア、DRAM、ディスクおよびネットワーク I/O)の上限を設定することで、これらのクエリが他の重要なビジネスクエリに影響を与えないようにできます。
同時実行制御は、多数のクエリが同時実行されるシナリオでのスレッドの過剰割り当てを防ぎます。より具体的には、クエリごとのワーカースレッド数は、利用可能な CPU コア数に対する指定された比率に基づいて動的に調整されます。
ClickHouse はメモリアロケーションのバイト数をサーバー、ユーザー、およびクエリのレベルで追跡し、柔軟なメモリ使用量制限の設定を可能にします。メモリのオーバーコミットにより、クエリは保証されたメモリ量を超えて空きメモリを追加利用できる一方で、他のクエリのメモリ上限は保証されます。さらに、集約、ソート、結合句におけるメモリ使用量に上限を設定でき、メモリ上限を超えた場合には外部アルゴリズムへのフォールバックが行われます。
最後に、I/O スケジューリングにより、最大帯域幅、処理中のリクエスト数、およびポリシー(例: FIFO、SFC [32])に基づいて、ワークロードクラスごとのローカルおよびリモートディスクアクセスを制限できます。
5 INTEGRATION LAYER
リアルタイムで意思決定を行うアプリケーションは、多くの場合、複数の場所に存在するデータへ効率的かつ低レイテンシでアクセスできることに依存します。外部データを OLAP データベースで利用可能にするには、2 つのアプローチがあります。プッシュ型データアクセスでは、サードパーティコンポーネントがデータベースと外部データストアを橋渡しします。その一例が、リモートデータを宛先システムにプッシュする、特化した抽出・変換・ロード(ETL)ツールです。プル型モデルでは、データベース自体がリモートデータソースに接続し、クエリのためにローカルテーブルにデータを取り込むか、データをリモートシステムへエクスポートします。プッシュ型アプローチはより汎用的で一般的ですが、その分アーキテクチャのフットプリントが大きくなり、スケーラビリティのボトルネックも生じます。対照的に、データベース内で直接リモート接続を行うと、全体のアーキテクチャをシンプルに保ちつつ、ローカルデータとリモートデータの結合など、インサイトを得るまでの時間を短縮する興味深い機能を提供できます。
この節の残りでは、リモートロケーションのデータへアクセスすることを目的とした、ClickHouse におけるプル型データ統合方式を説明します。SQL データベースにおけるリモート接続という考え方自体は新しいものではないことに留意してください。例えば、2001 年に導入され、2011 年から PostgreSQL によって実装されている SQL/MED 標準 [35] は、外部データを管理するための統一インターフェースとして foreign data wrapper を提案しています [65]。他のデータストアやストレージフォーマットとの最大限の相互運用性は、ClickHouse の設計目標の 1 つです。2024 年 3 月時点で、ClickHouse は我々の知る限り、すべての分析向けデータベースの中で最も多くの組み込みデータ統合オプションを提供しています。
外部接続。ClickHouse は、ODBC、MySQL、PostgreSQL、SQLite、Kafka、Hive、MongoDB、Redis、S3/GCP/Azure オブジェクトストアおよび各種データレイクを含む外部システムやストレージロケーションへの接続のために、50+ 種類の統合テーブル関数とエンジンを提供します。これらは、(元の VLDB 論文には含まれない)次のボーナス図で示すカテゴリーにさらに分類されます。
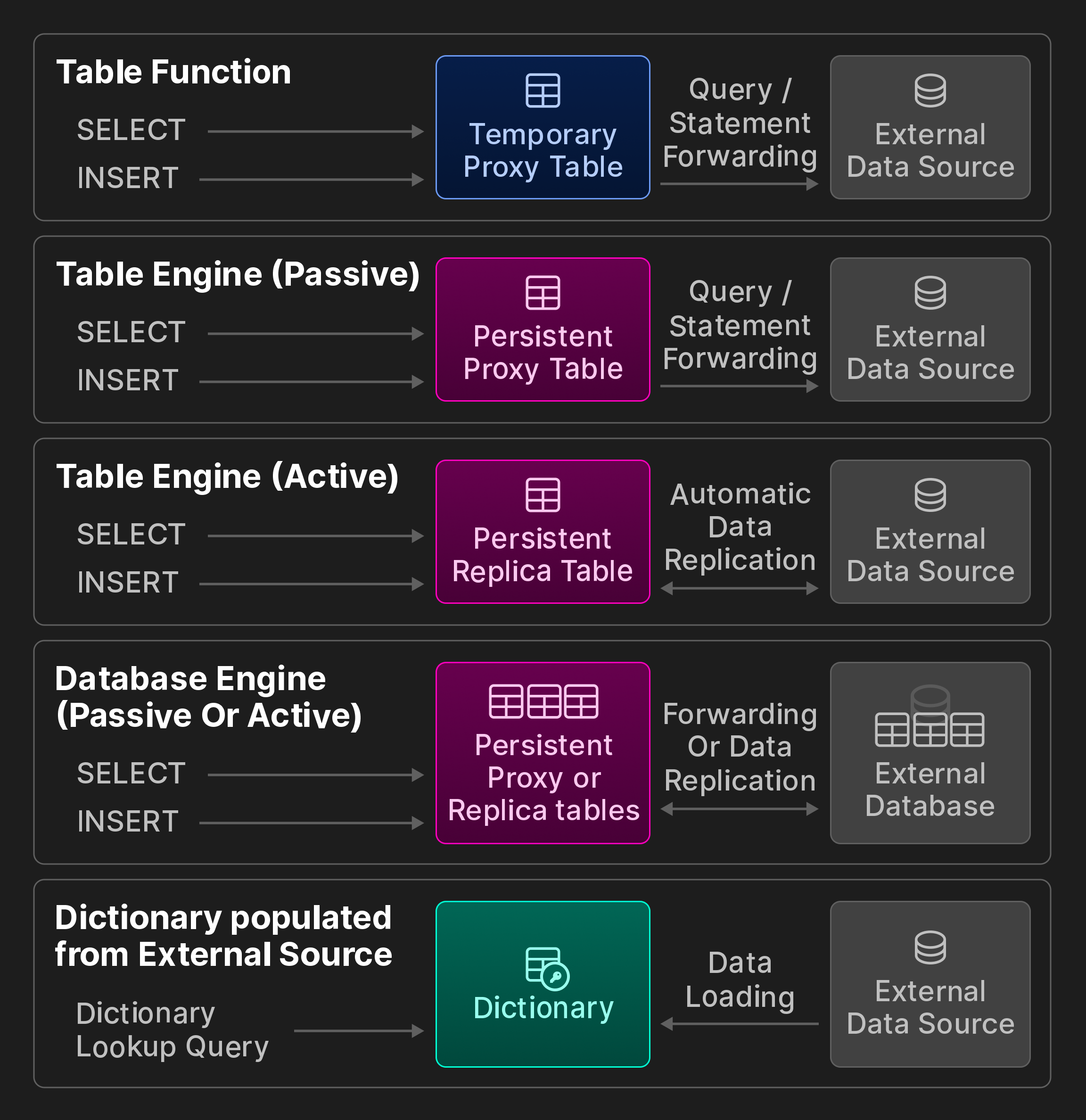
ボーナス図: ClickBench の相互運用性オプション。
統合 テーブル関数 による一時的アクセス。テーブル関数は、SELECT クエリの FROM 句で呼び出すことで、探索的なアドホッククエリのためにリモートデータを読み取ることができます。あるいは、INSERT INTO TABLE FUNCTION 文を使用して、リモートストアへデータを書き込むために利用することもできます。
永続的なアクセス。リモートデータストアおよび処理システムと永続的な接続を作成するには、3 つの方法があります。
第一に、統合 テーブルエンジン は、MySQL テーブルのようなリモートデータソースを永続的なローカルテーブルとして表現します。ユーザーは、CREATE TABLE AS 構文を SELECT クエリおよびテーブル関数と組み合わせて使用し、テーブル定義を保存します。例えば、リモート列のサブセットのみを参照するためにカスタムスキーマを指定することも、列名とそれに相当する ClickHouse 型を自動的に決定するスキーマ推論を使用することも可能です。さらに、実行時の挙動としてパッシブとアクティブを区別します。パッシブテーブルエンジンは、クエリをリモートシステムへ転送し、その結果でローカルのプロキシテーブルを埋めます。対照的に、アクティブテーブルエンジンは、リモートシステムから定期的にデータをプルするか、PostgreSQL のロジカルレプリケーションプロトコルなどを通じてリモートの変更を購読します。その結果、ローカルテーブルにはリモートテーブルの完全なコピーが保持されます。
第二に、統合 データベースエンジン は、リモートデータストア内のテーブルスキーマに属するすべてのテーブルを ClickHouse 上にマッピングします。前者と異なり、一般にリモートデータストアがリレーショナルデータベースであることを要件とし、さらに DDL 文への限定的なサポートを提供します。
第三に、辞書 は、対応する統合テーブル関数またはエンジンを用いて、ほぼあらゆるデータソースに対する任意のクエリからデータを取り込むことができます。実行時の挙動はアクティブであり、リモートストレージから一定間隔でデータがプルされます。
データフォーマット。サードパーティシステムと連携するためには、最新の分析データベースはあらゆるフォーマットのデータを処理できなければなりません。ネイティブフォーマットに加えて、ClickHouse は CSV、JSON、Parquet、Avro、ORC、Arrow、Protobuf などを含む 90+ 種類のフォーマットをサポートしています。各フォーマットは、入力フォーマット(ClickHouse が読み取れるもの)、出力フォーマット(ClickHouse がエクスポートできるもの)、あるいはその両方になり得ます。Parquet のような分析指向フォーマットの一部はクエリ処理と統合されており、すなわちオプティマイザが埋め込まれた統計情報を利用でき、フィルタは圧縮データ上で直接評価されます。
互換性インターフェース。ネイティブなバイナリワイヤプロトコルおよび HTTP に加えて、クライアントは MySQL または PostgreSQL のワイヤプロトコル互換インターフェース経由で ClickHouse とやり取りできます。この互換性機能は、ベンダーがまだネイティブな ClickHouse 接続を実装していない(特定のビジネスインテリジェンスツールなどの)プロプライエタリアプリケーションからのアクセスを可能にする上で有用です。
6 機能としてのパフォーマンス
このセクションでは、パフォーマンス分析のための組み込みツールを紹介し、実際のクエリおよびベンチマーククエリを用いてパフォーマンスを評価します。
6.1 ビルトインのパフォーマンス解析ツール
個々のクエリやバックグラウンド処理におけるパフォーマンスボトルネックを調査するための、幅広いツールが利用可能です。ユーザーは、すべてのツールを system テーブルに基づく統一的なインターフェースを通じて操作します。
サーバーおよびクエリのメトリクス。アクティブパーツ数、ネットワークスループット、キャッシュヒット率などのサーバーレベルの統計情報に加えて、読み取られたブロック数やインデックス使用状況統計などのクエリ単位の統計情報が提供されます。メトリクスは、リクエストに応じて同期的に、または設定可能な間隔で非同期に計算されます。
サンプリングプロファイラ。サーバースレッドのコールスタックは、サンプリングプロファイラを用いて収集できます。結果は、必要に応じて flamegraph ビジュアライザなどの外部ツールにエクスポートできます。
OpenTelemetry との統合。OpenTelemetry は、複数のデータ処理システム間でデータ行をトレースするためのオープンな標準仕様です [8]。ClickHouse は、すべてのクエリ処理ステップに対して粒度を設定可能な OpenTelemetry ログスパンを生成できるほか、他のシステムからの OpenTelemetry ログスパンを収集および解析できます。
EXPLAIN クエリ。他のデータベースと同様に、SELECT クエリの前に EXPLAIN を付けることで、そのクエリの AST、論理および物理オペレータプラン、実行時の挙動に関する詳細な情報を得ることができます。
6.2 ベンチマーク
ベンチマークは、現実的でないという批判もあるものの [10, 52, 66, [74]](#page-13-24)、データベースの長所と短所を把握するうえで依然として有用です。以下では、ClickHouse の性能を評価する際にベンチマークがどのように使われているかを説明します。
6.2.1 Denormalized Tables
非正規化されたファクトテーブルに対するフィルタおよび集計クエリは、歴史的に ClickHouse の主たるユースケースとなっています。ここでは、この種の典型的なワークロードである ClickBench の実行時間を報告します。ClickBench は、クリックストリームおよびトラフィック解析で用いられるアドホックおよび定期的なレポーティングクエリをシミュレートします。このベンチマークは、ウェブ上で最大級のアナリティクスプラットフォームの 1 つに由来する、1 億件の匿名化されたページヒットを含むテーブルに対する 43 個のクエリで構成されています。オンラインダッシュボード [17] では、2024 年 6 月時点で 45 を超える商用および研究用データベースに対する測定結果(コールド/ホットの実行時間、データインポート時間、オンディスクサイズ)が示されています。結果は、一般公開されているデータセットおよびクエリ [16] に基づき、第三者のコントリビュータによって投稿されています。クエリはシーケンシャルスキャンおよびインデックススキャンのアクセスパスをテストし、CPU、IO、あるいはメモリがボトルネックとなるリレーショナルオペレータを頻繁に顕在化させます。
Figure 10 は、アナリティクスで頻繁に使われるデータベースにおいて、すべての ClickBench クエリを順次実行した場合の総相対コールドおよびホット実行時間を示しています。測定は、16 vCPU、32 GB RAM、および 5000 IOPS / 1000 MiB/s のディスクを備えた単一ノードの AWS EC2 c6a.4xlarge インスタンス上で行いました。Redshift(ra3.4xlarge、12 vCPU、96 GB RAM)および Snowfake(warehouse size S: 2x8 vCPU、2x16 GB RAM)には同等のシステムを使用しました。物理的なデータベース設計のチューニングは最小限にとどめており、たとえば主キーは指定しますが、個々のカラムの圧縮方式を変更したり、プロジェクションやスキップインデックスを作成したりはしていません。また、各コールドクエリ実行の前に Linux ページキャッシュをフラッシュしますが、データベースやオペレーティングシステムの各種設定値は調整していません。各クエリについて、すべてのデータベースの中で最も速い実行時間をベースラインとして使用します。他のデータベースの相対クエリ実行時間は ( + 10)/(_ + 10) として計算されます。あるデータベースの合計相対実行時間は、クエリごとの比率の幾何平均です。研究用データベース Umbra [54] はホット実行時間で全体として最良の結果を達成していますが、ClickHouse はホットおよびコールドの実行時間の両方で、他のすべてのプロダクショングレードのデータベースを上回っています。
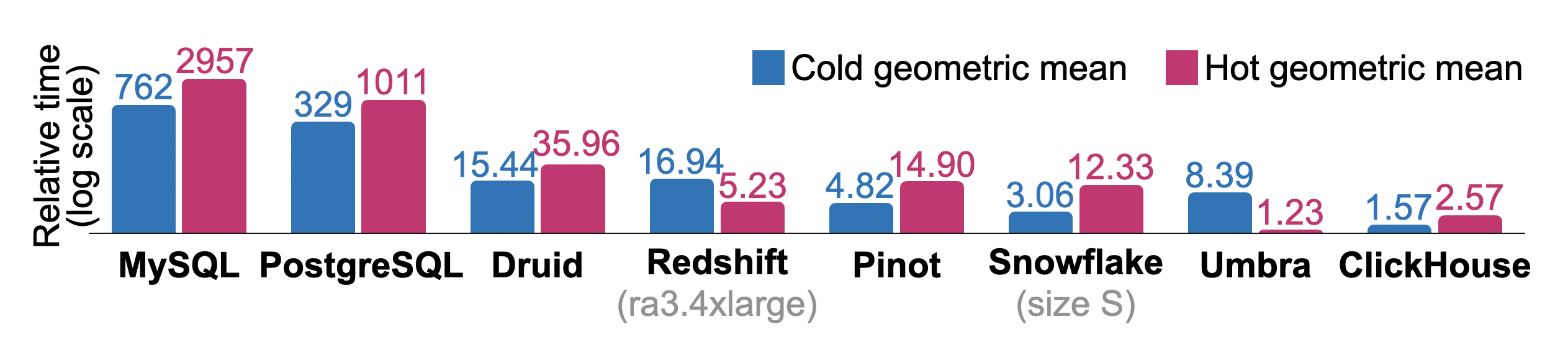
Figure 10: ClickBench の相対コールドおよびホット実行時間。
より多様なワークロードにおける SELECT の性能を時間とともに追跡するために、VersionsBench [19] と呼ばれる 4 つのベンチマークの組み合わせを使用しています。このベンチマークは、新しいリリースが公開されるたびに月 1 回実行され、その性能を評価 [20] し、性能を劣化させた可能性のあるコード変更を特定します。個々のベンチマークは次のとおりです。1. 上述の ClickBench、2. 15 個の MgBench [21] クエリ、3. 6 億行の非正規化 Star Schema Benchmark [57] ファクトテーブルに対する 13 個のクエリ、4. 34 億行を持つ NYC Taxi Rides に対する 4 個のクエリ [70]。
Figure 11 は、2018 年 3 月から 2024 年 3 月までの 77 個の ClickHouse バージョンにおける VersionsBench 実行時間の推移を示しています。個々のクエリの相対実行時間の違いを補正するために、全バージョンにわたる最小クエリ実行時間に対する比率を重みとして、幾何平均を用いて実行時間を正規化しています。過去 6 年間で VersionBench の性能は 1.72 倍向上しました。長期サポート(LTS)リリースのリリース日は x 軸上に示されています。一部の期間では一時的に性能が低下したものの、LTS リリースは概して、直前の LTS バージョンと同等かそれ以上の性能を持ちます。2022 年 8 月の大幅な改善は、セクション 4.4. で説明したカラム単位のフィルタ評価手法によるものです。
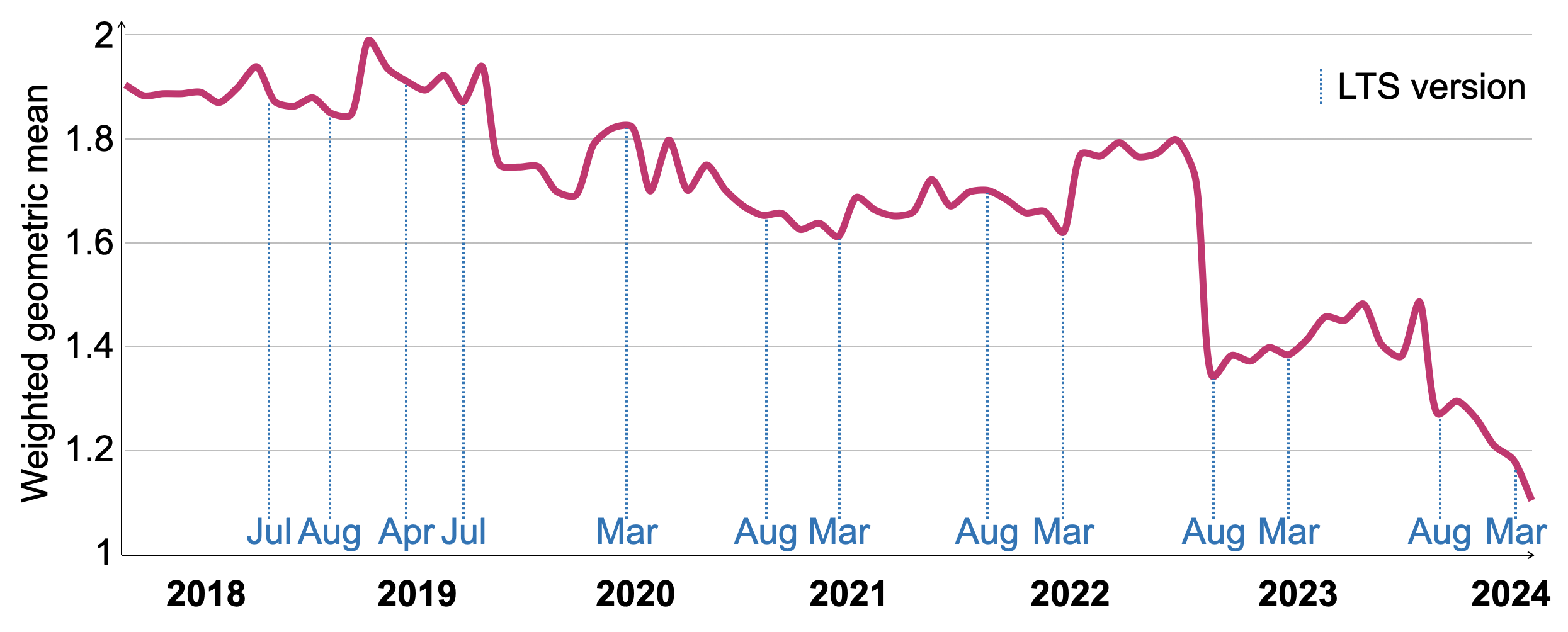
Figure 11: VersionsBench 2018–2024 の相対ホット実行時間。
6.2.2 正規化テーブル
従来型のデータウェアハウジングでは、データはしばしばスター・スキーマやスノーフレーク・スキーマを用いてモデリングされます。ここでは TPC-H クエリ(スケールファクタ 100)の実行時間を示しますが、正規化テーブルは ClickHouse にとって新たなユースケースとして台頭しつつあることに留意してください。Figure 12 は、4.4 節 で説明した並列ハッシュ結合アルゴリズムに基づく TPC-H クエリのホットランタイムを示しています。計測は、64 vCPU、128 GB RAM、および 5000 IOPS / 1000 MiB/s のディスクを備えた単一ノードの AWS EC2 c6i.16xlarge インスタンス上で実施しました。5 回の実行のうち最速のものを記録しています。参考として、同程度の規模(warehouse size L、8x8 vCPU、8x16 GB RAM)の Snowfake システムでも同じ計測を行いました。表からは 11 個のクエリの結果を除外しています。クエリ Q2、Q4、Q13、Q17、および Q20–22 には相関サブクエリが含まれており、これは ClickHouse v24.6 時点ではサポートされていません。クエリ Q7–Q9 および Q19 は、結合のための拡張されたプランレベル最適化(結合の並べ替えや結合述語のプッシュダウンなど、いずれも ClickHouse v24.6 時点では未実装)に依存しており、実用的なランタイムを達成するにはこれらが必要です。サブクエリの自動デコリレーションおよび結合に対するより良いオプティマイザのサポートは、2024 年に実装予定です [18]。残り 11 個のクエリのうち、5(6)個のクエリは ClickHouse(Snowfake)の方が高速に実行されました。上述の最適化は性能にとって重要であることが知られているため [27]、それらが実装されれば、これらのクエリのランタイムはさらに改善されると期待されます。

Figure 12: TPC-H クエリのホットランタイム(秒)。
7 関連研究
分析データベースは、ここ数十年にわたり学術的にも商業的にも大きな関心を集めてきた [1]。Sybase IQ [48]、Teradata [72]、Vertica [42]、Greenplum [47] のような初期のシステムは、高価なバッチ ETL ジョブとオンプレミスであることに起因するエラスティシティの制限によって特徴付けられた。2010 年代初頭には、Snowfake [22]、BigQuery [49]、Redshift [4] のようなクラウドネイティブなデータウェアハウスおよび Database-as-a-Service (DBaaS) の登場により、組織における分析のコストと複雑さが劇的に低下しつつ、高可用性と自動リソーススケーリングの恩恵を受けられるようになった。さらに近年では、Photon [5] や Velox [62] といった分析実行カーネルが登場し、さまざまな分析・ストリーミング・機械学習アプリケーションで利用するために共同で最適化されたデータ処理を提供している。
目標や設計原則という観点で ClickHouse に最も類似しているデータベースは、Druid [78] と Pinot [34] である。両システムは、高いデータインジェスト率を伴うリアルタイム分析をターゲットとしている。ClickHouse と同様に、テーブルはセグメントと呼ばれる水平方向の parts に分割される。ClickHouse は小さな parts を継続的にマージし、オプションでセクション 3.3, の手法を用いてデータ量を削減するのに対し、Druid と Pinot では parts は永続的に不変のままである。また、Druid と Pinot ではテーブルの作成・変更・検索のために専用ノードが必要である一方、ClickHouse はこれらのタスクに単一のモノリシックなバイナリを用いる。
Snowfake [22] は、共有ディスクアーキテクチャに基づく広く利用されているプロプライエタリなクラウドデータウェアハウスである。テーブルをマイクロパーティションに分割するというアプローチは、ClickHouse における parts の概念と類似している。Snowfake は永続化のためにハイブリッド PAX ページ [3] を利用するのに対し、ClickHouse のストレージフォーマットは厳密にカラム指向である。Snowfake は、ローカルキャッシュおよび自動的に作成される軽量インデックス [31, [51]](#page-13-14) を用いたデータのプルーニングを、高い性能を実現するための要素として重視している。ClickHouse におけるプライマリキーと同様に、ユーザはオプションでクラスタ化インデックスを作成し、同じ値を持つデータを共配置させることができる。
Photon [5] と Velox [62] は、複雑なデータ管理システムのコンポーネントとして利用されることを想定したクエリ実行エンジンである。両システムはクエリプランを入力として受け取り、その後ローカルノード上で Parquet (Photon) または Arrow (Velox) ファイル [46] に対してクエリを実行する。ClickHouse もこれらの汎用フォーマットでデータを読み書きすることが可能だが、ストレージにはネイティブなファイルフォーマットを優先して用いる。Velox と Photon はクエリプラン自体を最適化することはなく (Velox は基本的な式の最適化を行う)、その代わりに、データ特性に応じて計算カーネルを動的に切り替えるといったランタイム適応技法を活用する。同様に、ClickHouse のプランオペレーターは、
主としてクエリのメモリ消費量に応じて外部集約オペレーターや外部結合オペレーターへ切り替える目的で、実行時に他のオペレーターを生成することができる。Photon の論文では、コード生成型の設計 [38, 41, [53]](#page-13-0) は、インタプリタ型のベクトル化設計 [11] と比べて開発およびデバッグがより困難であると指摘している。Velox における (実験的な) コード生成サポートでは、実行時に生成された C++ コードから生成された共有ライブラリをビルドしてリンクするのに対し、ClickHouse は LLVM のオンデマンドコンパイル API と直接対話する。
DuckDB [67] はホストプロセスに組み込んで利用されることを想定している点では同様ですが、加えてクエリ最適化機能およびトランザクション機能も提供します。これは、OLAP クエリにときおり OLTP ステートメントが混在するワークロード向けに設計されています。DuckDB はそれに合わせて DataBlocks [43] ストレージフォーマットを採用しており、順序保持ディクショナリや frame-of-reference [2] のような軽量な圧縮方式を用いて、ハイブリッドワークロードで良好なパフォーマンスを実現しています。対照的に、ClickHouse は追記専用ユースケース、すなわち更新や削除が存在しない、もしくはまれである状況向けに最適化されています。ブロックは LZ4 のような重量級の圧縮手法で圧縮されており、ユーザーが頻出クエリの高速化のためにデータプルーニングを積極的に行うこと、そして残りのクエリでは I/O コストが伸長コストを大きく上回ることを前提としています。DuckDB はさらに、Hyper の MVCC スキーム [55] に基づくシリアライザブルトランザクションも提供しますが、ClickHouse が提供するのはスナップショット分離のみです。
8 結論と今後の展望
本稿では、オープンソースの高性能な OLAP データベースである ClickHouse のアーキテクチャを紹介した。書き込みに最適化されたストレージレイヤーと最先端のベクタ化クエリエンジンを基盤とすることで、ClickHouse は高いインジェストレートを維持しつつ、ペタバイト級データセットに対するリアルタイム分析を可能にしている。バックグラウンドでデータのマージおよび変換を非同期に行うことで、ClickHouse はデータメンテナンスと並列インサートを効率的に分離している。ストレージレイヤーは、疎なプライマリインデックス、スキップインデックス、projection テーブルを用いることで、積極的なデータプルーニングを実現する。さらに、ClickHouse における更新および削除、冪等なインサート、高可用性のためのノード間レプリケーションの実装について述べた。クエリ処理レイヤーは、多様な手法を用いてクエリを最適化し、すべてのサーバーおよび cluster リソースにまたがって実行を並列化する。統合テーブルエンジンおよび関数は、他のデータ管理システムやデータ形式とシームレスに連携するための便利な手段を提供する。ベンチマークを通じて、ClickHouse が市場で最も高速な分析データベースの一つであることを示すとともに、実世界の ClickHouse 導入環境における典型的なクエリ性能が、年月をかけて大きく向上してきたことを示した。
2024 年に計画されているすべての機能および拡張は、パブリックなロードマップ [18] に記載されている。計画中の改善には、ユーザートランザクションのサポート、代替クエリ言語としての PromQL [69]、半構造化データ (例:JSON) 向けの新しいデータ型、結合のより高度なプランレベル最適化に加え、軽量削除を補完する軽量更新の実装などが含まれる。
ACKNOWLEDGMENTS
バージョン 24.6 時点で、SELECT * FROM system.contributors の実行結果には、ClickHouse に貢献した 1994 名の個人が記録されています。ClickHouse Inc. のエンジニアリングチーム全体と、素晴らしい ClickHouse オープンソースコミュニティの皆様が、このデータベースを共に構築していくために注いでこられた多大な努力と献身に、心より感謝申し上げます。
参考情報
- [1] Daniel Abadi、Peter Boncz、Stavros Harizopoulos、Stratos Idreaos、および Samuel Madden. 2013. The Design and Implementation of Modern Column-Oriented Database Systems. https://doi.org/10.1561/9781601987556
- [2] Daniel Abadi、Samuel Madden、Miguel Ferreira。2006年。カラム指向データベースシステムにおける圧縮と実行の統合。In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data (SIGMOD '06), 671–682。https://doi.org/10.1145/1142473.1142548
- [3] Anastassia Ailamaki, David J. DeWitt, Mark D. Hill, and Marios Skounakis. 2001. Weaving Relations for Cache Performance(リレーションの編成によるキャッシュ性能向上). In Proceedings of the 27th International Conference on Very Large Data Bases (VLDB '01). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 169–180.
- [4] Nikos Armenatzoglou、Sanuj Basu、Naga Bhanoori、Mengchu Cai、Naresh Chainani、Kiran Chinta、Venkatraman Govindaraju、Todd J. Green、Monish Gupta、Sebastian Hillig、Eric Hotinger、Yan Leshinksy、Jintian Liang、Michael McCreedy、Fabian Nagel、Ippokratis Pandis、Panos Parchas、Rahul Pathak、Orestis Polychroniou、Foyzur Rahman、Gaurav Saxena、Gokul Soundararajan、Sriram Subramanian、および Doug Terry。2022年。Amazon Redshift Re-Invented。In Proceedings of the 2022 International Conference on Management of Data (Philadelphia, PA, USA) (SIGMOD '22)。Association for Computing Machinery, New York, NY, USA, 2205–2217。https://doi.org/10.1145/3514221.3526045
- [5] Alexander Behm, Shoumik Palkar, Utkarsh Agarwal, Timothy Armstrong, David Cashman, Ankur Dave, Todd Greenstein, Shant Hovsepian, Ryan Johnson, Arvind Sai Krishnan, Paul Leventis, Ala Luszczak, Prashanth Menon, Mostafa Mokhtar, Gene Pang, Sameer Paranjpye, Greg Rahn, Bart Samwel, Tom van Bussel, Herman van Hovell, Maryann Xue, Reynold Xin, および Matei Zaharia. 2022年. Photon: レイクハウスシステム向けの高速クエリエンジン (SIGMOD '22). Association for Computing Machinery, New York, NY, USA, 2326–2339. https://doi.org/10.1145/3514221. 3526054
- [6] Philip A. Bernstein and Nathan Goodman. 1981. Concurrency Control in Distributed Database Systems. ACM Computing Survey 13, 2 (1981), 185–221. https://doi.org/10.1145/356842.356846
- [7] Spyros Blanas, Yinan Li, and Jignesh M. Patel. 2011. マルチコア CPU 向けのメインメモリ・ハッシュ結合アルゴリズムの設計と評価. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data (Athens, Greece) (SIGMOD '11). Association for Computing Machinery, New York, NY, USA, 37–48. https://doi.org/10.1145/1989323.1989328
- [8] Daniel Gomez Blanco. 2023年. 『Practical OpenTelemetry』. Springer Nature.
- [9] Burton H. Bloom. 1970. 許容誤差のあるハッシュ符号における空間と時間のトレードオフ. Commun. ACM 13, 7 (1970), 422–426. https://doi.org/10.1145/362686. 362692
- [10] Peter Boncz、Thomas Neumann、Orri Erling。2014年。TPC-H の分析:隠れたメッセージと、この影響力の大きいベンチマークから得られた教訓。『Performance Characterization and Benchmarking』所収。61–76。 https://doi.org/10.1007/978-3-319- 04936-6_5
- [11] Peter Boncz、Marcin Zukowski、Niels Nes. 2005. MonetDB/X100: Hyper-Pipelining Query Execution. In CIDR.
- [12] Martin Burtscher and Paruj Ratanaworabhan. 2007. High Throughput Compression of Double-Precision Floating-Point Data(倍精度浮動小数点データの高スループット圧縮). In Data Compression Conference (DCC). 293–302. https://doi.org/10.1109/DCC.2007.44
- [13] Jef Carpenter, Eben Hewitt. 2016. Cassandra: The Defnitive Guide(第2版)。O'Reilly Media, Inc.
- [14] Bernadette Charron-Bost, Fernando Pedone, and André Schiper(編). 2010. Replication: Theory and Practice. Springer-Verlag.
- [15] chDB. 2024. chDB - 組み込み OLAP SQL エンジン。2024 年 6 月 20 日に https://github.com/chdb-io/chdb から取得。
- [16] ClickHouse. 2024. ClickBench: a Benchmark for Analytical Databases. 2024-06-20 閲覧: https://github.com/ClickHouse/ClickBench
- [17] ClickHouse. 2024. ClickBench: Comparative Measurements(比較測定). 2024-06-20 閲覧: https://benchmark.clickhouse.com
- [18] ClickHouse. 2024. ClickHouse Roadmap 2024(GitHub). 2024-06-20 閲覧: https://github.com/ClickHouse/ClickHouse/issues/58392
- [19] ClickHouse. 2024年. ClickHouse Versions Benchmark. 2024-06-20 に https://github.com/ClickHouse/ClickBench/tree/main/versions から取得
- [20] ClickHouse. 2024. ClickHouse バージョンのベンチマーク結果. 2024-06-20 閲覧: https://benchmark.clickhouse.com/versions/
- [21] Andrew Crotty. 2022. MgBench. 2024-06-20 に取得。 https://github.com/ andrewcrotty/mgbench
- [22] Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, and Philipp Unterbrunner. 2016. The Snowfake Elastic Data Warehouse. Proceedings of the 2016 International Conference on Management of Data(San Francisco, California, USA)(SIGMOD '16)に収録。Association for Computing Machinery, New York, NY, USA, 215–226. https: //doi.org/10.1145/2882903.2903741
- [23] Patrick Damme, Annett Ungethüm, Juliana Hildebrandt, Dirk Habich, and Wolfgang Lehner. 2019. 軽量整数圧縮アルゴリズムに対する包括的な実験的調査からコストベース選択戦略へ. ACM Trans. Database Syst. 44, 3, Article 9 (2019), 46ページ. https://doi.org/10.1145/3323991
- [24] Philippe Dobbelaere and Kyumars Sheykh Esmaili. 2017. Kafka versus RabbitMQ: 2つの業界標準的な Publish/Subscribe 実装の比較研究:Industry Paper (DEBS '17). Association for Computing Machinery, New York, NY, USA, 227–238. https://doi.org/10.1145/3093742.3093908
- [25] LLVM ドキュメント. 2024. LLVM における自動ベクトル化. 2024年6月20日アクセス, https://llvm.org/docs/Vectorizers.html
- [26] Siying Dong, Andrew Kryczka, Yanqin Jin, and Michael Stumm. 2021. RocksDB: 大規模アプリケーション向けキーバリューストアにおける開発優先事項の変遷. ACM Transactions on Storage 17, 4, Article 26 (2021), 32ページ. https://doi.org/10.1145/3483840
- [27] Markus Dreseler, Martin Boissier, Tilmann Rabl, and Matthias Ufacker. 2020. TPC-H チョークポイントとその最適化の定量的評価. Proc. VLDB Endow. 13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
- [28] Ted Dunning. 2021. t-digest: 分布の効率的な推定手法. Software Impacts 7 (2021). https://doi.org/10.1016/j.simpa.2020.100049
- [29] Martin Faust, Martin Boissier, Marvin Keller, David Schwalb, Holger Bischof, Katrin Eisenreich, Franz Färber, および Hasso Plattner. 2016年. Footprint Reduction and Uniqueness Enforcement with Hash Indices in SAP HANA. In Database and Expert Systems Applications. 137–151. https://doi.org/10.1007/978-3-319-44406- 2_11
- [30] Philippe Flajolet、Eric Fusy、Olivier Gandouet、および Frederic Meunier。2007 年。HyperLogLog: ほぼ最適な基数推定アルゴリズムに関する解析。AofA: Analysis of Algorithms、DMTCS Proceedings 第 AH 巻、2007 年 Conference on Analysis of Algorithms (AofA 07) に収録。Discrete Mathematics and Theoretical Computer Science、137–156。https://doi.org/10.46298/dmtcs.3545
- [31] Hector Garcia-Molina, Jefrey D. Ullman, and Jennifer Widom. 2009. Database Systems — The Complete Book (第2版).
- [32] Pawan Goyal, Harrick M. Vin, and Haichen Chen. 1996. Start-time フェアキューイング:統合サービス型パケット交換ネットワーク用スケジューリングアルゴリズム. 26, 4 (1996), 157–168. https://doi.org/10.1145/248157.248171
- [33] Goetz Graefe. 1993. 大規模データベース向けクエリ評価手法. ACM Comput. Surv. 25, 2 (1993), 73–169. https://doi.org/10.1145/152610.152611
- [34] Jean-François Im, Kishore Gopalakrishna, Subbu Subramaniam, Mayank Shrivastava, Adwait Tumbde, Xiaotian Jiang, Jennifer Dai, Seunghyun Lee, Neha Pawar, Jialiang Li, and Ravi Aringunram. 2018年. Pinot: Realtime OLAP for 530 Million Users. In Proceedings of the 2018 International Conference on Management of Data (Houston, TX, USA) (SIGMOD '18). Association for Computing Machinery, New York, NY, USA, 583–594頁. https://doi.org/10.1145/3183713.3190661
- [35] ISO/IEC 9075-9:2001 2001年. 情報技術 — データベース言語 — SQL — 第9部:外部データの管理 (SQL/MED)。規格。国際標準化機構 (ISO)。
- [36] Paras Jain, Peter Kraft, Conor Power, Tathagata Das, Ion Stoica, and Matei Zaharia. 2023年. レイクハウス・ストレージシステムの分析と比較. CIDR.
- [37] Project Jupyter. 2024. Jupyter Notebooks. 2024年6月20日取得、https: //jupyter.org/ より
- [38] Timo Kersten、Viktor Leis、Alfons Kemper、Thomas Neumann、Andrew Pavlo、Peter Boncz。2018年。コンパイル方式およびベクトル化クエリについて、知りたかったが聞けなかったすべてのこと。Proc. VLDB Endow. 11, 13 (2018年9月), 2209–2222。 https://doi.org/10.14778/3275366.3284966
- [39] Changkyu Kim、Jatin Chhugani、Nadathur Satish、Eric Sedlar、Anthony D. Nguyen、Tim Kaldewey、Victor W. Lee、Scott A. Brandt、Pradeep Dubey。2010年。FAST: fast architecture sensitive tree search on modern CPUs and GPUs。In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (Indianapolis, Indiana, USA) (SIGMOD '10)。Association for Computing Machinery、New York, NY, USA、339–350。 https://doi.org/10.1145/1807167.1807206
- [40] Donald E. Knuth. 1973. The Art of Computer Programming, Volume III: Sorting and Searching(『コンピュータプログラミングの芸術 第3巻:ソートと探索』). Addison-Wesley.
- [41] André Kohn, Viktor Leis, and Thomas Neumann. 2018. Adaptive Execution of Compiled Queries. In 2018 IEEE 34th International Conference on Data Engineering (ICDE). 197–208. https://doi.org/10.1109/ICDE.2018.00027
- [42] Andrew Lamb、Matt Fuller、Ramakrishna Varadarajan、Nga Tran、Ben Vandiver、Lyric Doshi、および Chuck Bear。2012年。The Vertica Analytic Database: C-Store 7 Years Later. Proc. VLDB Endow. 5, 12(2012年8月), 1790–1801。 https://doi.org/10. 14778/2367502.2367518
- [43] Harald Lang, Tobias Mühlbauer, Florian Funke, Peter A. Boncz, Thomas Neumann, and Alfons Kemper. 2016. Data Blocks: ベクトル化とコンパイルの両方を用いた圧縮ストレージ上のハイブリッド OLTP/OLAP. In Proceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA) (SIGMOD '16). Association for Computing Machinery, New York, NY, USA, 311–326. https://doi.org/10.1145/2882903.2882925
- [44] Viktor Leis, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2014. Morsel駆動並列処理: マルチコア時代のNUMA対応のクエリ評価フレームワーク. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD '14). Association for Computing Machinery, New York, NY, USA, 743–754. https://doi.org/10.1145/2588555. 2610507
- [45] Viktor Leis、Alfons Kemper、Thomas Neumann。2013年。The adaptive radix tree: メインメモリデータベース向けの ART インデックス方式。2013年 IEEE 第29回国際データエンジニアリング会議 (ICDE)。38–49。 https://doi.org/10.1109/ICDE. 2013.6544812
- [46] Chunwei Liu, Anna Pavlenko, Matteo Interlandi, and Brandon Haynes. 2023. 分析用DBMS向け一般的なオープン形式の徹底解説. 16, 11 (2023年7月), 3044–3056. https://doi.org/10.14778/3611479.3611507
- [47] Zhenghua Lyu, Huan Hubert Zhang, Gang Xiong, Gang Guo, Haozhou Wang, Jinbao Chen, Asim Praveen, Yu Yang, Xiaoming Gao, Alexandra Wang, Wen Lin, Ashwin Agrawal, Junfeng Yang, Hao Wu, Xiaoliang Li, Feng Guo, Jiang Wu, Jesse Zhang, および Venkatesh Raghavan. 2021. Greenplum: トランザクション処理および分析処理ワークロード向けハイブリッドデータベース (SIGMOD '21). Association for Computing Machinery, New York, NY, USA, 2530–2542. https: //doi.org/10.1145/3448016.3457562
- [48] Roger MacNicol と Blaine French。2004年。Sybase IQ Multiplex - Designed for Analytics。Thirtieth International Conference on Very Large Data Bases(VLDB '04, Toronto, Canada)論文集第30巻に収録。VLDB Endowment, 1227–1230。
- [49] Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geofrey Romer, Shiva Shivakumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky, and Jef Shute. 2020. Dremel: A Decade of Interactive SQL Analysis at Web Scale. Proc. VLDB Endow. 13, 12 (2020年8月), 3461–3472. https://doi.org/10.14778/3415478.3415568
- [50] Microsoft. 2024. Kusto Query Language. 2024-06-20 に https: //github.com/microsoft/Kusto-Query-Language から閲覧。
- [51] Guido Moerkotte. 1998. Small Materialized Aggregates: A Light Weight Index Structure for Data Warehousing. 第24回 International Conference on Very Large Data Bases (VLDB '98) 論文集, pp. 476–487.
- [52] Jalal Mostafa, Sara Wehbi, Suren Chilingaryan, and Andreas Kopmann. 2022. SciTS: 科学実験およびインダストリアル・インターネット・オブ・シングスにおける時系列データベースのベンチマーク. In 第34回 Scientific and Statistical Database Management 国際会議 (SSDBM '22) 論文集. 第12論文. https: //doi.org/10.1145/3538712.3538723
- [53] Thomas Neumann. 2011. 現代ハードウェア向け効率的クエリプランの効率的コンパイル. Proc. VLDB Endow. 4, 9 (2011年6月), 539–550. https://doi.org/10.14778/ 2002938.2002940
- [54] Thomas Neumann and Michael J. Freitag. 2020. Umbra: インメモリ性能を実現したディスクベースシステム. In 10th Conference on Innovative Data Systems Research, CIDR 2020, Amsterdam, The Netherlands, January 12-15, 2020, Online Proceedings. www.cidrdb.org. http://cidrdb.org/cidr2020/papers/p29-neumanncidr20.pdf
- [55] Thomas Neumann, Tobias Mühlbauer, and Alfons Kemper. 2015年. Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems. 2015年 ACM SIGMOD International Conference on Management of Data (Melbourne, Victoria, Australia) (SIGMOD '15) 会議論文集に収録. Association for Computing Machinery, New York, NY, USA, pp. 677–689. https://doi.org/10.1145/2723372. 2749436
- [56] GitHub 上の LevelDB。2024 年。LevelDB。2024-06-20 に https://github. com/google/leveldb から取得。
- [57] Patrick O'Neil, Elizabeth O'Neil, Xuedong Chen, and Stephen Revilak. 2009年. 「スタースキーマベンチマークと拡張ファクトテーブルインデックス付け」『Performance Evaluation and Benchmarking』所収, Springer Berlin Heidelberg, 237–252ページ. https: //doi.org/10.1007/978-3-642-10424-4_17
- [58] Patrick E. O'Neil, Edward Y. C. Cheng, Dieter Gawlick, and Elizabeth J. O'Neil. 1996年. ログ構造化マージ木(LSM-tree). Acta Informatica 33 (1996), 351–385. https://doi.org/10.1007/s002360050048
- [59] Diego Ongaro、John Ousterhout. 2014. In Search of an Understandable Consensus Algorithm(理解しやすいコンセンサスアルゴリズムの探求). In Proceedings of the 2014 USENIX Conference on USENIX Annual Technical Conference (USENIX ATC'14). 305–320. https://doi.org/doi/10. 5555/2643634.2643666
- [60] Patrick O'Neil、Edward Cheng、Dieter Gawlick、Elizabeth O'Neil。1996年。The Log-Structured Merge-Tree (LSM-Tree)。Acta Inf. 33, 4 (1996), 351–385。 https: //doi.org/10.1007/s002360050048
- [61] Pandas. 2024年. Pandas Dataframes. 2024年6月20日閲覧。参照元: https://pandas. pydata.org/
- [62] Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He, and Biswapesh Chattopadhyay. 2022. Velox: Meta's Unified Execution Engine. Proc. VLDB Endow. 15, 12 (aug 2022), 3372–3384. https: //doi.org/10.14778/3554821.3554829
- [63] Tuomas Pelkonen、Scott Franklin、Justin Teller、Paul Cavallaro、Qi Huang、Justin Meza、Kaushik Veeraraghavan。2015年。Gorilla: A Fast, Scalable, in-Memory Time Series Database。Proceedings of the VLDB Endowment 8, 12 (2015), 1816–1827。 https://doi.org/10.14778/2824032.2824078
- [64] Orestis Polychroniou、Arun Raghavan、および Kenneth A. Ross。2015年。Rethinking SIMD Vectorization for In-Memory Databases(インメモリデータベースにおけるSIMDベクトル化の再考)。2015 ACM SIGMOD International Conference on Management of Data (SIGMOD '15) 論文集, pp. 1493–1508。 https://doi.org/10.1145/2723372.2747645
- [65] PostgreSQL. 2024. PostgreSQL - Foreign Data Wrappers(外部データラッパー). 2024-06-20 参照, https://wiki.postgresql.org/wiki/Foreign_data_wrappers
- [66] Mark Raasveldt、Pedro Holanda、Tim Gubner、Hannes Mühleisen. 2018. 公正なベンチマークは困難とされる: データベース性能テストにおける一般的な落とし穴. In Proceedings of the Workshop on Testing Database Systems (Houston, TX, USA) (DBTest'18). Article 2, 6 pages. https://doi.org/10.1145/3209950.3209955
- [67] Mark Raasveldt と Hannes Mühleisen。2019年。DuckDB: An Embeddable Analytical Database (SIGMOD '19)。Association for Computing Machinery、New York, NY, USA、1981–1984。https://doi.org/10.1145/3299869.3320212
- [68] Jun Rao and Kenneth A. Ross. 1999. メインメモリ内の意思決定支援のためのキャッシュ指向インデックス付け. In Proceedings of the 25th International Conference on Very Large Data Bases (VLDB '99). San Francisco, CA, USA, 78–89.
- [69] Navin C. Sabharwal and Piyush Kant Pandey. 2020. Working with Prometheus Query Language (PromQL). 『Monitoring Microservices and Containerized Applications』所収. https://doi.org/10.1007/978-1-4842-6216-0_5
- [70] Todd W. Schneider. 2022. New York City Taxi and For-Hire Vehicle Data. 2024-06-20 に https://github.com/toddwschneider/nyc-taxi-data より取得。
- [71] Mike Stonebraker, Daniel J. Abadi, Adam Batkin, Xuedong Chen, Mitch Cherniack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O'Neil, Pat O'Neil, Alex Rasin, Nga Tran, and Stan Zdonik. 2005. C-Store: A Column-Oriented DBMS. In Proceedings of the 31st International Conference on Very Large Data Bases (VLDB '05). 553–564.
- [72] Teradata. 2024. Teradata Database. 2024年6月20日閲覧。https://www. teradata.com/resources/datasheets/teradata-database
- [73] Frederik Transier. 2010. インメモリテキスト検索エンジンのためのアルゴリズムとデータ構造. 博士学位論文. https://doi.org/10.5445/IR/1000015824
- [74] Adrian Vogelsgesang, Michael Haubenschild, Jan Finis, Alfons Kemper, Viktor Leis, Tobias Muehlbauer, Thomas Neumann, and Manuel Then. 2018. Get Real: How Benchmarks Fail to Represent the Real World(ベンチマークは現実世界をどのように表現し損なっているか). In Proceedings of the Workshop on Testing Database Systems(Houston, TX, USA)(DBTest'18). Article 1, 全6ページ. https://doi.org/10.1145/3209950.3209952
- [75] LZ4 ウェブサイト. 2024. LZ4. https://lz4.org/(2024-06-20 参照)
- [76] PRQL ウェブサイト。2024年。PRQL。2024-06-20 に https://prql-lang.org から取得。 [77] Till Westmann, Donald Kossmann, Sven Helmer, and Guido Moerkotte. 2000年。圧縮データベースの実装と性能。SIGMOD Rec.
- 29, 3 (2000年9月), 55–67。 https://doi.org/10.1145/362084.362137 [78] Fangjin Yang, Eric Tschetter, Xavier Léauté, Nelson Ray, Gian Merlino, and Deep Ganguli. 2014. Druid: リアルタイム分析用データストア. Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (Snowbird, Utah, USA) (SIGMOD '14). Association for Computing Machinery, New York, NY, USA, 157–168. https://doi.org/10.1145/2588555.2595631
- [79] Tianqi Zheng, Zhibin Zhang, and Xueqi Cheng. 2020. SAHA:分析データベース向けの文字列適応型ハッシュテーブル。Applied Sciences 10, 6 (2020). https: //doi.org/10.3390/app10061915
- [80] Jingren Zhou and Kenneth A. Ross. 2002. SIMD 命令を用いたデータベース操作の実装. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data (SIGMOD '02). 145–156. https://doi.org/10. 1145/564691.564709
- [81] Marcin Zukowski, Sandor Heman, Niels Nes, and Peter Boncz. 2006. Super-Scalar RAM-CPU Cache Compression. 第22回 International Conference on Data Engineering (ICDE '06) 論文集, 59. https://doi.org/10.1109/ICDE. 2006.150
