Sending many small batches in synchronous mode isn’t recommended, leading to many parts being created. This will lead to poor query performance and “too many part” errors.
async_insert setting.
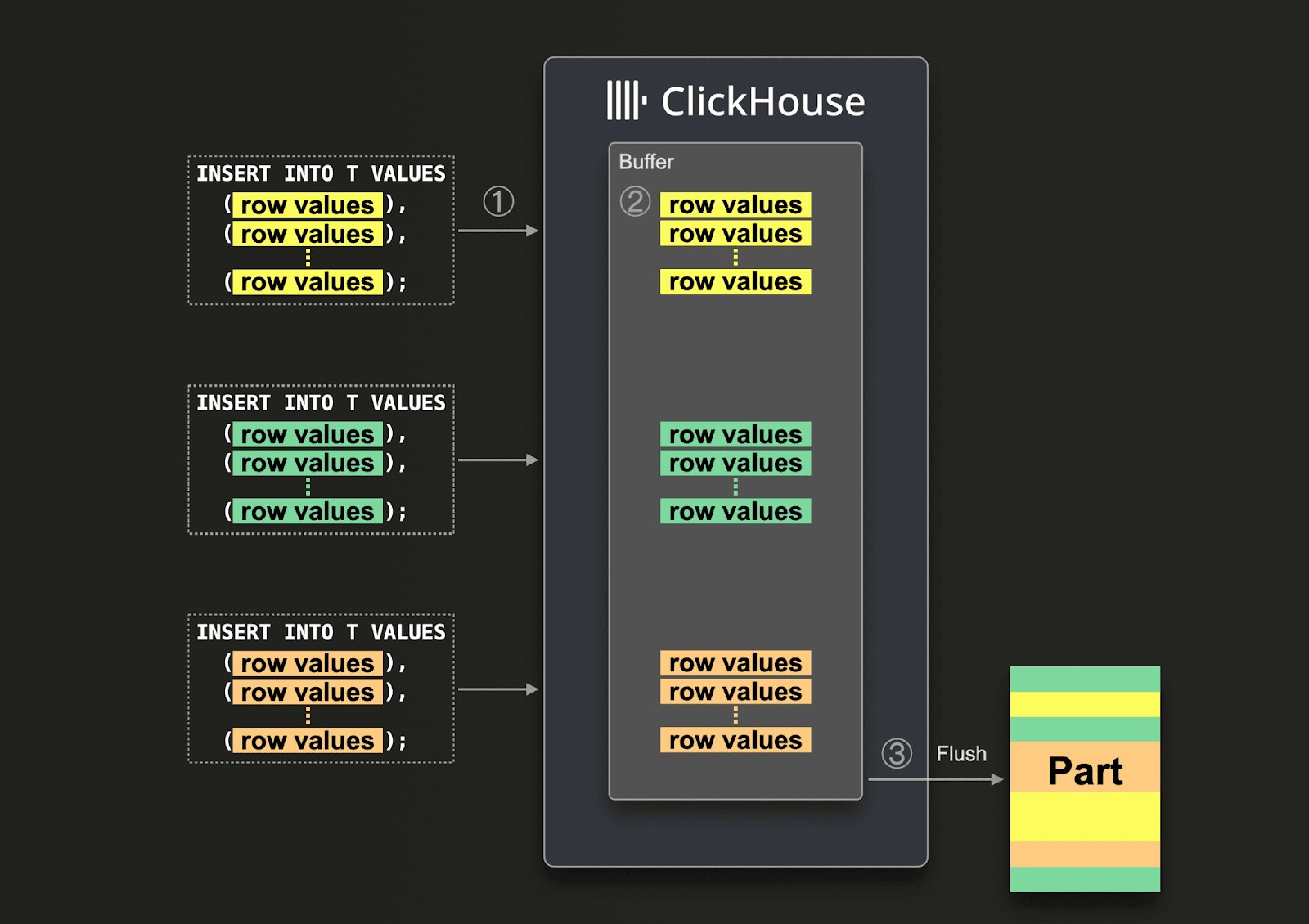
async_insert = 1), inserts are buffered and only written to disk once one of the flush conditions is met:
- The buffer reaches a specified data size (
async_insert_max_data_size, default 100 MiB). - A time threshold elapses (
async_insert_busy_timeout_ms, default 200 ms or 1000 ms on Cloud). - A maximum number of insert queries accumulate (
async_insert_max_query_number, default 450).
Choosing a return mode
The behavior of asynchronous inserts is further refined using thewait_for_async_insert setting.
When set to 1 (the default), ClickHouse only acknowledges the insert after the data is successfully flushed to disk. This ensures strong durability guarantees and makes error handling straightforward: if something goes wrong during the flush, the error is returned to the client. This mode is recommended for most production scenarios, especially when insert failures must be tracked reliably.
Benchmarks show it scales well with concurrency—whether you’re running 200 or 500 clients—thanks to adaptive inserts and stable part creation behavior.
Setting wait_for_async_insert = 0 enables “fire-and-forget” mode. Here, the server acknowledges the insert as soon as the data is buffered, without waiting for it to reach storage.
This offers ultra-low-latency inserts and maximal throughput, ideal for high-velocity, low-criticality data. However, this comes with trade-offs: there’s no guarantee the data will be persisted, errors only surface during flush, and there is no dead-letter queue for failed inserts — tracing failures requires inspecting server logs and system tables after the fact. Use this mode only if your workload can tolerate data loss.
Benchmarks also demonstrate substantial part reduction and lower CPU usage when buffer flushes are infrequent (e.g. every 30 seconds), but the risk of silent failure remains.
Our strong recommendation is to use async_insert=1,wait_for_async_insert=1 if using asynchronous inserts. Using wait_for_async_insert=0 is very risky because your INSERT client may not be aware if there are errors, and also can cause potential overload if your client continues to write quickly in a situation where the ClickHouse server needs to slow down the writes and create some backpressure to ensure reliability of the service.
Adaptive async inserts
Since version 24.2, ClickHouse uses adaptive flush timeouts by default (async_insert_use_adaptive_busy_timeout). Instead of a fixed flush interval, the timeout dynamically adjusts between a minimum (async_insert_busy_timeout_min_ms, default 50 ms) and maximum (async_insert_busy_timeout_max_ms, default 200 ms or 1000 ms on Cloud) based on incoming data rate.
When data arrives frequently, the timeout stays closer to the minimum to flush sooner and reduce end-to-end latency. When data is sparse, it grows toward the maximum to accumulate larger batches. This is especially useful in default mode (wait_for_async_insert=1), where a fixed high timeout would force clients to block for the full interval even when data is ready to flush.
Error handling
Schema validation and data parsing happen during buffer flush, not when the insert is received. If any row in an insert query has a parsing or type error, none of the data from that query is flushed — the entire query’s payload is rejected. In default mode (wait_for_async_insert=1), the error is returned to the client. In fire-and-forget mode, errors are written to server logs and the system.asynchronous_inserts table.
Each flush creates at least one part per distinct partition key value in the buffer. Even for tables without a partition key, a single flush can produce multiple parts if the buffered data exceeds max_insert_block_size (default ~1 million rows).
Despite using async inserts, you can still encounter “too many parts” errors if the partitioning key has high cardinality.
Deduplication and reliability
By default, ClickHouse performs automatic deduplication for synchronous inserts, which makes retries safe in failure scenarios. However, this is disabled for asynchronous inserts unless explicitly enabled (this shouldn’t be enabled if you have dependent materialized views — see issue). In practice, if deduplication is turned on and the same insert is retried — due to, for instance, a timeout or network drop — ClickHouse can safely ignore the duplicate. This helps maintain idempotency and avoids double-writing data.Enabling asynchronous inserts
Asynchronous inserts can be enabled for a particular user, or for a specific query:-
Enabling asynchronous inserts at the user level. This example uses the user
default, if you create a different user then substitute that username: -
You can specify the asynchronous insert settings by using the SETTINGS clause of insert queries:
-
You can also specify asynchronous insert settings as connection parameters when using a ClickHouse programming language client.
As an example, this is how you can do that within a JDBC connection string when you use the ClickHouse Java JDBC driver for connecting to ClickHouse Cloud:
Asynchronous inserts don’t apply to
INSERT INTO ... SELECT queries. When the insert contains a SELECT clause, the query is always executed synchronously regardless of the async_insert setting.Flushing buffers on shutdown
To flush all pending async insert buffers — for example, during a graceful shutdown or before maintenance — run:Comparison with buffer tables
Asynchronous inserts are the modern replacement for Buffer tables. Key differences:- No DDL changes required. Async inserts are transparent — you enable a setting, not create additional tables.
- Per-shape buffering. Async inserts maintain separate buffers per unique query shape and settings combination, enabling granular flush policies. Buffer tables use a single buffer per target table.
- Durability. In default mode (
wait_for_async_insert=1), data is confirmed on disk before the client receives acknowledgment. Buffer tables behave like fire-and-forget — buffered data is lost on crash. - Cluster behavior. In clusters, async insert buffers are maintained per node. Buffer tables require explicit creation on each node.