JDBC Connector
This connector should only be used if your data is simple and consists of primitive data types e.g., int. ClickHouse specific types such as maps are not supported.
For our examples, we utilize the Confluent distribution of Kafka Connect.
Below we describe a simple installation, pulling messages from a single Kafka topic and inserting rows into a ClickHouse table. We recommend Confluent Cloud, which offers a generous free tier for those who do not have a Kafka environment.
Note that a schema is required for the JDBC Connector (You cannot use plain JSON or CSV with the JDBC connector). Whilst the schema can be encoded in each message; it is strongly advised to use the Confluent schema registry to avoid the associated overhead. The insertion script provided automatically infers a schema from the messages and inserts this to the registry - this script can thus be reused for other datasets. Kafka's keys are assumed to be Strings. Further details on Kafka schemas can be found here.
License
The JDBC Connector is distributed under the Confluent Community License
Steps
Gather your connection details
To connect to ClickHouse with HTTP(S) you need this information:
The HOST and PORT: typically, the port is 8443 when using TLS or 8123 when not using TLS.
The DATABASE NAME: out of the box, there is a database named
default, use the name of the database that you want to connect to.The USERNAME and PASSWORD: out of the box, the username is
default. Use the username appropriate for your use case.
The details for your ClickHouse Cloud service are available in the ClickHouse Cloud console. Select the service that you will connect to and click Connect:
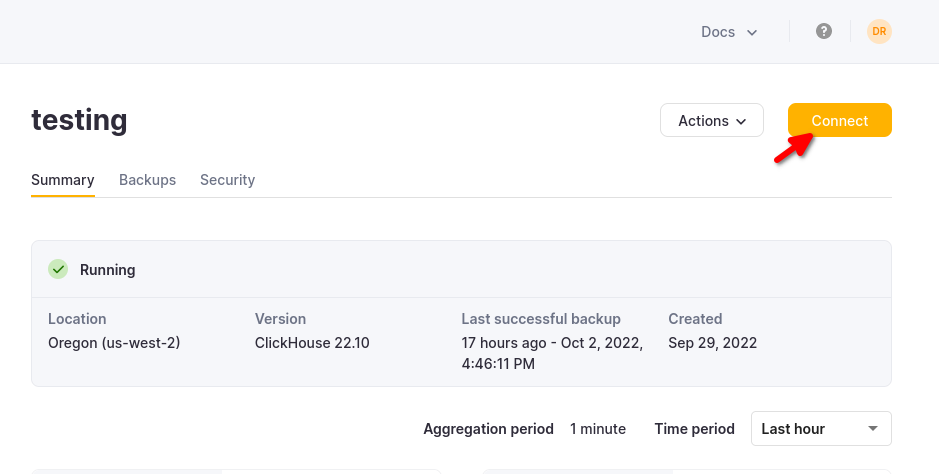
Choose HTTPS, and the details are available in an example curl command.
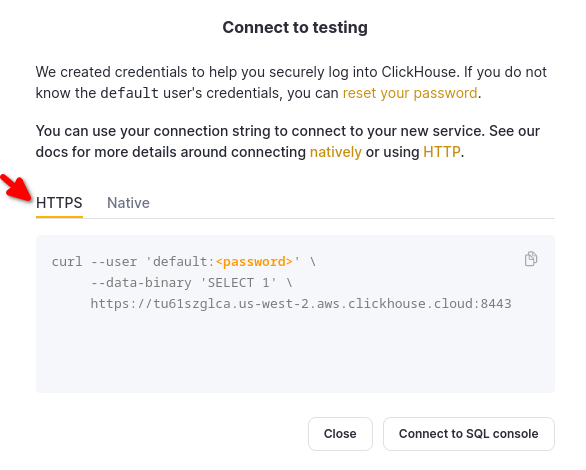
If you are using self-managed ClickHouse, the connection details are set by your ClickHouse administrator.
1. Install Kafka Connect and Connector
We assume you have downloaded the Confluent package and installed it locally. Follow the installation instructions for installing the connector as documented here.
If you use the confluent-hub installation method, your local configuration files will be updated.
For sending data to ClickHouse from Kafka, we use the Sink component of the connector.
2. Download and install the JDBC Driver
Download and install the ClickHouse JDBC driver clickhouse-jdbc-<version>-shaded.jar from here. Install this into Kafka Connect following the details here. Other drivers may work but have not been tested.
Common Issue: the docs suggest copying the jar to share/java/kafka-connect-jdbc/. If you experience issues with Connect finding the driver, copy the driver to share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib/. Or modify plugin.path to include the driver - see below.
3. Prepare Configuration
Follow these instructions for setting up a Connect relevant to your installation type, noting the differences between a standalone and distributed cluster. If using Confluent Cloud the distributed setup is relevant.
The following parameters are relevant to using the JDBC connector with ClickHouse. A full parameter list can be found here:
_connection.url_- this should take the form ofjdbc:clickhouse://<clickhouse host>:<clickhouse http port>/<target database>connection.user- a user with write access to the target databasetable.name.format- ClickHouse table to insert data. This must exist.batch.size- The number of rows to send in a single batch. Ensure this set is to an appropriately large number. Per ClickHouse recommendations a value of 1000 should be considered a minimum.tasks.max- The JDBC Sink connector supports running one or more tasks. This can be used to increase performance. Along with batch size this represents your primary means of improving performance.value.converter.schemas.enable- Set to false if using a schema registry, true if you embed your schemas in the messages.value.converter- Set according to your datatype e.g. for JSON, “io.confluent.connect.json.JsonSchemaConverter”.key.converter- Set to “org.apache.kafka.connect.storage.StringConverter”. We utilise String keys.pk.mode- Not relevant to ClickHouse. Set to none.auto.create- Not supported and must be false.auto.evolve- We recommend false for this setting although it may be supported in the future.insert.mode- Set to “insert”. Other modes are not currently supported.key.converter- Set according to the types of your keys.value.converter- Set based on the type of data on your topic. This data must have a supported schema - JSON, Avro or Protobuf formats.
If using our sample dataset for testing, ensure the following are set:
value.converter.schemas.enable- Set to false as we utilize a schema registry. Set to true if you are embedding the schema in each message.key.converter- Set to “org.apache.kafka.connect.storage.StringConverter”. We utilise String keys.value.converter- Set “io.confluent.connect.json.JsonSchemaConverter”.value.converter.schema.registry.url- Set to the schema server url along with the credentials for the schema server via the parametervalue.converter.schema.registry.basic.auth.user.info.
Example configuration files for the Github sample data can be found here, assuming Connect is run in standalone mode and Kafka is hosted in Confluent Cloud.
4. Create the ClickHouse table
Ensure the table has been created, dropping it if it already exists from previous examples. An example compatible with the reduced Github dataset is shown below. Not the absence of any Array or Map types that are not currently not supported:
CREATE TABLE github
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4, 'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8, 'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11, 'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15, 'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19, 'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9, 'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
path String,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
assignee LowCardinality(String),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
merged_by LowCardinality(String),
review_comments UInt32,
member_login LowCardinality(String)
) ENGINE = MergeTree ORDER BY (event_type, repo_name, created_at)
5. Start Kafka Connect
Start Kafka Connect in either standalone or distributed mode.
./bin/connect-standalone connect.properties.ini github-jdbc-sink.properties.ini
6. Add data to Kafka
Insert messages to Kafka using the script and config provided. You will need to modify github.config to include your Kafka credentials. The script is currently configured for use with Confluent Cloud.
python producer.py -c github.config
This script can be used to insert any ndjson file into a Kafka topic. This will attempt to infer a schema for you automatically. The sample config provided will only insert 10k messages - modify here if required. This configuration also removes any incompatible Array fields from the dataset during insertion to Kafka.
This is required for the JDBC connector to convert messages to INSERT statements. If you are using your own data, ensure you either insert a schema with every message (setting _value.converter.schemas.enable _to true) or ensure your client publishes messages referencing a schema to the registry.
Kafka Connect should begin consuming messages and inserting rows into ClickHouse. Note that warnings regards “[JDBC Compliant Mode] Transaction is not supported.” are expected and can be ignored.
A simple read on the target table “Github” should confirm data insertion.
SELECT count() FROM default.github;
| count\(\) |
| :--- |
| 10000 |