Understanding ClickHouse data skipping indexes
Introduction
Many factors affect ClickHouse query performance. The critical element in most scenarios is whether ClickHouse can use the primary key when evaluating the query WHERE clause condition. Accordingly, selecting a primary key that applies to the most common query patterns is essential for effective table design.
Nevertheless, no matter how carefully tuned the primary key, there will inevitably be query use cases that can not efficiently use it. Users commonly rely on ClickHouse for time series type data, but they often wish to analyze that same data according to other business dimensions, such as customer id, website URL, or product number. In that case, query performance can be considerably worse because a full scan of each column value may be required to apply the WHERE clause condition. While ClickHouse is still relatively fast in those circumstances, evaluating millions or billions of individual values will cause "non-indexed" queries to execute much more slowly than those based on the primary key.
In a traditional relational database, one approach to this problem is to attach one or more "secondary" indexes to a table. This is a b-tree structure that permits the database to find all matching rows on disk in O(log(n)) time instead of O(n) time (a table scan), where n is the number of rows. However, this type of secondary index won't work for ClickHouse (or other column-oriented databases) because there are no individual rows on the disk to add to the index.
Instead, ClickHouse provides a different type of index, which in specific circumstances can significantly improve query speed. These structures are labeled "Skip" indexes because they enable ClickHouse to skip reading significant chunks of data that are guaranteed to have no matching values.
Basic operation
You can only employ Data Skipping Indexes on the MergeTree family of tables. Each data skipping has four primary arguments:
- Index name. The index name is used to create the index file in each partition. Also, it is required as a parameter when dropping or materializing the index.
- Index expression. The index expression is used to calculate the set of values stored in the index. It can be a combination of columns, simple operators, and/or a subset of functions determined by the index type.
- TYPE. The type of index controls the calculation that determines if it is possible to skip reading and evaluating each index block.
- GRANULARITY. Each indexed block consists of GRANULARITY granules. For example, if the granularity of the primary table index is 8192 rows, and the index granularity is 4, each indexed "block" will be 32768 rows.
When a user creates a data skipping index, there will be two additional files in each data part directory for the table.
skp_idx_{index_name}.idx, which contains the ordered expression valuesskp_idx_{index_name}.mrk2, which contains the corresponding offsets into the associated data column files.
If some portion of the WHERE clause filtering condition matches the skip index expression when executing a query and reading the relevant column files, ClickHouse will use the index file data to determine whether each relevant block of data must be processed or can be bypassed (assuming that the block hasn't already been excluded by applying the primary key). To use a very simplified example, consider the following table loaded with predictable data.
When executing a simple query that doesn't use the primary key, all 100 million entries in the my_value
column are scanned:
Now add a very basic skip index:
Normally skip indexes are only applied on newly inserted data, so just adding the index won't affect the above query.
To index already existing data, use this statement:
Rerun the query with the newly created index:
Instead of processing 100 million rows of 800 megabytes, ClickHouse has only read and analyzed 32768 rows of 360 kilobytes -- four granules of 8192 rows each.
In a more visual form, this is how the 4096 rows with a my_value of 125 were read and selected, and how the following rows
were skipped without reading from disk:
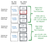
You can access detailed information about skip index usage by enabling the trace when executing queries. From
clickhouse-client, set the send_logs_level:
This will provide useful debugging information when trying to tune query SQL and table indexes. From the above example, the debug log shows that the skip index dropped all but two granules:
Skip index types
minmax
This lightweight index type requires no parameters. It stores the minimum and maximum values of the index expression for each block (if the expression is a tuple, it separately stores the values for each member of the element of the tuple). This type is ideal for columns that tend to be loosely sorted by value. This index type is usually the least expensive to apply during query processing.
This type of index only works correctly with a scalar or tuple expression -- the index will never be applied to expressions that return an array or map data type.
set
This lightweight index type accepts a single parameter of the max_size of the value set per block (0 permits an unlimited number of discrete values). This set contains all values in the block (or is empty if the number of values exceeds the max_size). This index type works well with columns with low cardinality within each set of granules (essentially, "clumped together") but higher cardinality overall.
The cost, performance, and effectiveness of this index is dependent on the cardinality within blocks. If each block contains a large number of unique values, either evaluating the query condition against a large index set will be very expensive, or the index won't be applied because the index is empty due to exceeding max_size.
text
For workloads that involve natural language or free-form text search (e.g., searching words or phrases in large text columns), ClickHouse provides a text index (a real inverted index).
Text index supports efficient full-text search semantics and tokenized lookups. It is the recommended choice for full-text search queries because it provides deterministic token indexing and better performance for search functions such as hasAnyToken, hasAllTokens but also optimize all common text search functions.
See the text index documentation for details here.
Bloom filter types
A Bloom filter is a data structure that allows space-efficient testing of set membership at the cost of a slight chance of false positives. A false positive isn't a significant concern in the case of skip indexes because the only disadvantage is reading a few unnecessary blocks. However, the potential for false positives does mean that the indexed expression should be expected to be true, otherwise valid data may be skipped.
Because Bloom filters can more efficiently handle testing for a large number of discrete values, they can be appropriate for conditional expressions that produce more values to test. In particular, a Bloom filter index can be applied to arrays, where every value of the array is tested, and to maps, by converting either the keys or values to an array using the mapKeys or mapValues function.
There are three Data Skipping Index types based on Bloom filters:
-
The basic bloom_filter which takes a single optional parameter of the allowed "false positive" rate between 0 and 1 (if unspecified, .025 is used).
-
The specialized tokenbf_v1 (Deprecated)). It takes three parameters, all related to tuning the bloom filter used: (1) the size of the filter in bytes (larger filters have fewer false positives, at some cost in storage), (2) number of hash functions applied (again, more hash filters reduce false positives), and (3) the seed for the bloom filter hash functions. See the calculator here for more detail on how these parameters affect bloom filter functionality. This index works only with String, FixedString, and Map datatypes. The input expression is split into character sequences separated by non-alphanumeric characters. For example, a column value of
This is a candidate for a "full text" searchwill contain the tokensThisisacandidateforfulltextsearch. It is intended for use in LIKE, EQUALS, IN, hasToken() and similar searches for words and other values within longer strings. For example, one possible use might be searching for a small number of class names or line numbers in a column of free form application log lines. -
The specialized ngrambf_v1 (Deprecated). This index functions the same as the token index. It takes one additional parameter before the Bloom filter settings, the size of the ngrams to index. An ngram is a character string of length
nof any characters, so the stringA short stringwith an ngram size of 4 would be indexed as:
This index can also be useful for text searches, particularly languages without word breaks, such as Chinese.
For full-text search workloads, the dedicated text index (see Text index for full-text search) is recommended over the deprecated tokenbf_v1 or ngrambf_v1 indexes. The text index provides a true inverted index with better search performance, more predictable behavior, and greater flexibility and performance compared with token-based Bloom filter indexes.
Skip index functions
The core purpose of data-skipping indexes is to limit the amount of data analyzed by popular queries. Given the analytic nature of ClickHouse data, the pattern of those queries in most cases includes functional expressions. Accordingly, skip indexes must interact correctly with common functions to be efficient. This can happen either when:
- data is inserted and the index is defined as a functional expression (with the result of the expression stored in the index files), or
- the query is processed and the expression is applied to the stored index values to determine whether to exclude the block.
Each type of skip index works on a subset of available ClickHouse functions appropriate to the index implementation listed here. In general, set indexes and Bloom filter based indexes (another type of set index) are both unordered and therefore don't work with ranges. In contrast, minmax indexes work particularly well with ranges since determining whether ranges intersect is very fast. The efficacy of partial match functions LIKE, startsWith, endsWith, and hasToken depend on the index type used, the index expression, and the particular shape of the data.
Skip index settings
There are two available settings that apply to skip indexes.
- use_skip_indexes (0 or 1, default 1). Not all queries can efficiently use skip indexes. If a particular filtering condition is likely to include most granules, applying the data skipping index incurs an unnecessary, and sometimes significant, cost. Set the value to 0 for queries that are unlikely to benefit from any skip indexes.
- force_data_skipping_indices (comma separated list of index names). This setting can be used to prevent some kinds of inefficient queries. In circumstances where querying a table is too expensive unless a skip index is used, using this setting with one or more index names will return an exception for any query that doesn't use the listed index. This would prevent poorly written queries from consuming server resources.
Skip index best practices
Skip indexes aren't intuitive, especially for those accustomed to secondary row-based indexes from the RDMS realm or inverted indexes from document stores. To get any benefit, applying a ClickHouse data skipping index must avoid enough granule reads to offset the cost of calculating the index. Critically, if a value occurs even once in an indexed block, it means the entire block must be read into memory and evaluated, and the index cost has been needlessly incurred.
Consider the following data distribution:

Assume the primary/order by key is timestamp, and there is an index on visitor_id. Consider the following query:
A traditional secondary index would be very advantageous with this kind of data distribution. Instead of reading all 32768 rows to find
the 5 rows with the requested visitor_id, the secondary index would include just five row locations, and only those five rows would be
read from disk. The exact opposite is true for a ClickHouse data skipping index. All 32768 values in the visitor_id column will be tested
regardless of the type of skip index.
Accordingly, the natural impulse to try to speed up ClickHouse queries by simply adding an index to key columns is often incorrect. This advanced functionality should only be used after investigating other alternatives, such as modifying the primary key (see How to Pick a Primary Key), using projections, or using materialized views. Even when a data skipping index is appropriate, careful tuning both the index and the table will often be necessary.
In most cases a useful skip index requires a strong correlation between the primary key and the targeted, non-primary column/expression. If there is no correlation (as in the above diagram), the chances of the filtering condition being met by at least one of the rows in the block of several thousand values is high and few blocks will be skipped. In contrast, if a range of values for the primary key (like time of day) is strongly associated with the values in the potential index column (such as television viewer ages), then a minmax type of index is likely to be beneficial. Note that it may be possible to increase this correlation when inserting data, either by including additional columns in the sorting/ORDER BY key, or batching inserts in a way that values associated with the primary key are grouped on insert. For example, all of the events for a particular site_id could be grouped and inserted together by the ingest process, even if the primary key is a timestamp containing events from a large number of sites. This will result in many granules that contains only a few site ids, so many blocks could be skipped when searching by a specific site_id value.
Another good candidate for a skip index is for high cardinality expressions where any one value is relatively sparse in the data. One example might be an observability platform that tracks error codes in API requests. Certain error codes, while rare in the data, might be particularly important for searches. A set skip index on the error_code column would allow bypassing the vast majority of blocks that don't contain errors and therefore significantly improve error focused queries.
Finally, the key best practice is to test, test, test. Again, unlike b-tree secondary indexes or inverted indexes for searching documents, data skipping index behavior isn't easily predictable. Adding them to a table incurs a meaningful cost both on data ingest and on queries that for any number of reasons don't benefit from the index. They should always be tested on real world type of data, and testing should include variations of the type, granularity size and other parameters. Testing will often reveal patterns and pitfalls that aren't obvious from thought experiments alone.
