Postgres query insights
Query Insights captures per-statement telemetry from your Managed Postgres instance and ranks every query pattern by impact, so you can go from "p99 is creeping up" to "this pattern is spilling to disk" without leaving the cloud console.
The data comes from pg_stat_ch,
the open-source Postgres extension that streams per-statement counters into
ClickHouse Cloud. Telemetry is normalized inside Postgres before it leaves
the database — literals are stripped and replaced with placeholders, so the
exact values you query never enter the telemetry stream.
Open query insights
Open your Managed Postgres instance in the cloud console and click Query insights in the left sidebar. The page is divided into four surfaces, in the order you'd actually use them:
- An Overview that fits a database health check on one screen.
- A Slow patterns table that ranks every query pattern your database has run, sorted by whatever you suspect.
- A Recent queries panel that lists individual executions in reverse chronological order.
- A Detail flyout that aggregates every counter for a single pattern.
Use the Time period selector at the top to switch between the last 15 minutes, hour, day, week, or month. Aggregation bucket size adjusts automatically — 1-minute buckets for the last 15 minutes or hour, 5-minute for the last day, and 1-hour for the last week or month — so the charts stay responsive.
Overview
The overview is a 3×2 grid of six panels:
| Panel | What it shows |
|---|---|
| Queries / sec | Query volume normalized to a rate over the selected window. |
| Query latency | Mean, p50, p95, and p99 on one chart, so you can see when the tail diverges from the median. |
| Operations breakdown | A donut chart of the mix of SELECT, INSERT, UPDATE, and other operations your workload is actually made of. |
| Rows returned / affected | Total rows the workload moved over the window. |
| Buffer hit ratio | A donut chart of shared blocks hit vs. shared blocks read, with total CPU time on the legend. |
| Errors | Total error count, broken out over time. |
One screen tells you whether the database is healthy. A healthy instance has a familiar shape — buffer hit ratio in the high nineties, query volume moving with application traffic, error rate flat or zero, and percentile latencies tracking each other closely.

Slow patterns
When the overview points at trouble, the patterns table is where the investigation starts. One row per normalized query pattern, with the literals stripped out so executions of the same statement collapse onto the same row.

Sort by what you suspect
The table defaults to Total runtime descending — when you sort this way, the top pattern is usually the answer to "what is costing me the most?" It may not be the slowest pattern individually. A query that runs eight million times a day at twelve milliseconds can matter more than one that ran once at three seconds.
Each sort gives you a different lens:
- Total runtime — where the database spent the most wall-clock time.
- CPU time — compute-heavy patterns.
- Calls — high-frequency patterns.
- Errors — repeated failures.
- Avg / P50 / P95 / P99 / Max latency — outliers, by percentile.
- Rows returned, Blocks read, Blocks hit, WAL bytes — patterns that moved the most data through the engine, the cache, or the write-ahead log.
Click the Columns button to toggle additional columns into view. The patterns table exposes 19 columns total, including the percentile breakdown, cache hit ratio, and per-pattern CPU time.
Narrow the table
Filter the table to whichever slice of your workload you're investigating:
- Database
- User
- Operation (
SELECT,INSERT,UPDATE,DELETE, …) - Application — the
application_namefrom the connection string
"Show me only what the orders service is doing on the sales db"
becomes two dropdowns. Filter values auto-populate from what your
instance has actually run.
Recent queries
Below the patterns table, the Recent Queries panel lists individual executions in reverse chronological order — one row per executed statement, not one row per pattern. Use it when you want the raw event stream instead of an aggregate, for example to spot-check that a fix landed or to find the exact moment an error fired.

The default columns are Time, Operation, Query, Duration, Rows, Database, User, and Blks read. Open the Columns picker for Application, Blks hit, CPU user, CPU sys, and PID. The table accepts the same Database, User, Operation, and Application filters as the patterns table, and is sortable by Time, Duration, Rows, Blks read, and CPU time.
Click any row to open the same detail flyout as the patterns table, scoped to that single execution's pattern.
Detail flyout
Click any row in the patterns or recent queries table and the Query detail flyout opens on the right. The flyout takes every execution of that pattern over the selected time range and aggregates the counters that explain why it's slow.
The flyout is a single scrolling layout with five sections:
- Query pattern — the normalized SQL with literals replaced by
$1,$2, … and a copy-to-clipboard button. - Aggregate resource usage — a grid of 13 stat cards covering total calls, avg/P95/P99/max latency, total runtime, rows returned, cache hit ratio, blocks read, blocks hit, CPU time, WAL bytes, and errors.
- Query context — the database, user, operation, and application this pattern came from.
- Notable executions — errors, unusually slow runs, and large-result executions, surfaced before the full recent list.
- Recent executions — the individual runs of the same pattern, with per-execution counters.
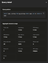
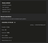
Per-execution counters
Expand a recent execution and you get the counters that pinpoint where the time went:
- Shared blocks — read and hit always shown; written and dirtied shown when non-zero.
- Local and temp block ops — non-zero temp block ops mean a sort or hash spilled to disk.
- Read / write time — I/O time, separately from CPU time.
- CPU time — user and system, separately.
- Parallel workers — planned vs. actually launched.
- JIT — total JIT compilation time and function count.
- WAL — bytes and record count.
Everything you need to diagnose a slow pattern is in one place, on one screen.
Query insights API
The same telemetry is available programmatically through the ClickHouse Cloud OpenAPI. The Slow patterns table maps to the list slow query patterns endpoint, and the detail flyout maps to the get slow query pattern endpoint, which returns one pattern's aggregate metrics together with its recent executions.
How it works
Normalized in Postgres, before the wire
pg_stat_ch hooks the parse-analyze phase, swaps each literal for a
placeholder ($1, $2, …), and caches the resulting pattern in a
per-backend LRU keyed by queryid. When the executor finishes the
statement, that cached pattern is what gets attached to the event. The
exact statement with values never leaves the database.
Out of the way of the database
The producer adds roughly 3% overhead per statement. The enqueue path uses a non-blocking try-lock on a shared-memory ring buffer. Under pressure, the extension drops events with a counter rather than back-pressuring Postgres.
Raw events, not aggregates
pg_stat_ch emits one raw event per executed statement (top-level and
nested), subject to sampling. Every percentile, ranking, and breakdown
in the UI is a ClickHouse query against the same event stream.
Same engine our customers use
The Insights backend is ClickHouse Cloud. Per-query telemetry from a busy Postgres instance is millions of rows a day; columnar compression keeps months of per-execution detail cheap to retain, and sub-second aggregations over billions of rows keep the UI interactive as you slice across a week or a month.
Open source
pg_stat_ch is Apache 2.0. Run it against any Postgres, ship to any
ClickHouse. Source and issues live at
github.com/clickhouse/pg_stat_ch.
Related pages
- Monitoring dashboard — built-in resource and activity charts
- Prometheus endpoint — scrape host-level metrics into your own observability stack
- Managed Postgres OpenAPI — query slow patterns and recent executions programmatically
- Extensions — the extensions available on Managed Postgres instances
pg_stat_chon GitHub — the open-source extension that powers Query Insights
