Migrate to Managed Postgres using PeerDB
This guide provides step-by-step instructions on how to migrate your PostgreSQL database to ClickHouse Managed Postgres using PeerDB.
BetaPrerequisites
- Access to your source PostgreSQL database.
- A ClickHouse Managed Postgres instance where you want to migrate your data.
- PeerDB installed on a machine. You can follow the installation instructions on the PeerDB GitHub repository. You just need to clone the repository and run
docker-compose up. For this guide, we will be using PeerDB UI, which will be accessible athttp://localhost:3000once PeerDB is running.
Considerations before migration
Before starting your migration, keep the following in mind:
- Database objects: PeerDB will create tables automatically in the target database based on the source schema. However, certain database objects like indexes, constraints, and triggers won't be migrated automatically. You'll need to recreate these objects manually in the target database after the migration.
- DDL changes: If you enable continuous replication, PeerDB will keep the target database in sync with the source for DML operations (INSERT, UPDATE, DELETE) and will propagate ADD COLUMN operations. However, other DDL changes (like DROP COLUMN, ALTER COLUMN) aren't propagated automatically. More on schema changes support here
- Network connectivity: Ensure that both the source and target databases are reachable from the machine where PeerDB is running. You may need to configure firewall rules or security group settings to allow connectivity.
Create peers
First, we need to create peers for both the source and target databases. A peer represents a connection to a database. In PeerDB UI, navigate to the "Peers" section by clicking on "Peers" in the sidebar. To create a new peer, click on the + New peer button.
Source peer creation
Create a peer for your source PostgreSQL database by filling in the connection details such as host, port, database name, username, and password. Once you have filled in the details, click on the Create peer button to save the peer.

Target peer creation
Similarly, create a peer for your ClickHouse Managed Postgres instance by providing the necessary connection details. You can get the connection details for your instance from the ClickHouse Cloud console. After filling in the details, click on the Create peer button to save the target peer.

Now, you should see both the source and target peers listed in the "Peers" section.

Obtain source schema dump
To mirror the setup of the source database in the target database, we need to obtain a schema dump of the source database. You can use pg_dump to create a schema-only dump of your source PostgreSQL database:
Installing pg_dump
Ubuntu:
Update package lists:
Install PostgreSQL client:
macOS:
Method 1: Using Homebrew (Recommended)
Install Homebrew if you don't have it:
Install PostgreSQL:
Verify installation:
Remove unique constraints and indexes from the schema dump
Before applying this to the target database, we need to remove UNIQUE constraints and indexes from the dump file so that PeerDB ingestion to target tables is not blocked by these constraints. These can be removed using:
Apply schema dump to target database
After cleaning up the schema dump file, you can apply it to your target ClickHouse Managed Postgres database by connecting via psql and running the schema dump file:
Here on the target side, we do not want PeerDB ingestion to be blocked by foreign key constraints. For this, we can alter the target role (used above in the target peer) to have session_replication_role set to replica:
Create a mirror
Next, we need to create a mirror to define the data migration process between the source and target peers. In PeerDB UI, navigate to the "Mirrors" section by clicking on "Mirrors" in the sidebar. To create a new mirror, click on the + New mirror button.
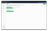
- Give your mirror a name that describes the migration.
- Select the source and target peers you created earlier from the dropdown menus.
- Make sure that:
- Soft delete is OFF.
- Expand
Advanced settings. Make sure that the Postgres type system is enabled and PeerDB columns are disabled.
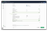
- Select the tables you want to migrate. You can choose specific tables or select all tables from the source database.
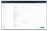
Make sure the destination table names are the same as the source table names in the target database, as we have migrated the schema as is in the earlier step.
- Once you have configured the mirror settings, click on the
Create mirrorbutton.
You should see your newly created mirror in the "Mirrors" section.
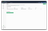
Wait for the initial load
After creating the mirror, PeerDB will start the initial data load from the source to the target database. You can click on the mirror and click on the Initial load tab to monitor the progress of the initial data migration.

Once the initial load is complete, you should see a status indicating that the migration is finished.
Monitoring initial load and replication
If you click on the source peer, you can see a list of running commands which PeerDB is running. For instance:
- Initially we run a COUNT query to estimate the number of rows in each table.
- Then we run a partitioning query using NTILE to break down large tables into smaller chunks for efficient data transfer.
- We then do FETCH commands to pull data from the source database and then PeerDB syncs them to the target database.
Post-migration tasks
These steps may vary based on your specific use case and application requirements. The key is to ensure data consistency, minimize downtime, and validate the integrity of the migrated data before fully switching over to the new system.
After the migration is complete:
- Run pre-cutover validation checks
Compare key tables between source and target before switching traffic:
- Stop writes on the source system
Pause application writes first. As an additional safeguard, set the source database to read-only during cutover:
If rollback is needed, you can re-enable writes:
- Confirm replication is fully caught up
Check that the latest row in one or more high-write tables matches on source and target:
- Recreate and enable constraints, indexes, and triggers
If you removed or deferred constraints/indexes for ingestion, re-apply them now. Also reset the replication role on target if you previously set it to replica:
- Reset sequences on target tables
After data load, align sequences with current table values:
- Cut over application traffic
Once validation passes and sequences/constraints are in place:
- Point read traffic to ClickHouse Managed Postgres.
- Point write traffic to ClickHouse Managed Postgres.
- Monitor application errors, constraint violations, and database health.
- Clean up resources
Once you're satisfied with the migration and have switched your application to use ClickHouse Managed Postgres, you can delete the mirror and peers in PeerDB.
If you enabled continuous replication, PeerDB will create a replication slot on the source PostgreSQL database. Make sure to drop the replication slot manually from the source database after you're done with the migration to avoid unnecessary resource usage.
References
- ClickHouse Managed Postgres Documentation
- PeerDB guide for CDC creation
- Postgres ClickPipe FAQ (holds true for PeerDB as well)
Next steps
Congratulations! You have successfully migrated your PostgreSQL database to ClickHouse Managed Postgres using pg_dump and pg_restore. You're now all set to explore Managed Postgres features and its integration with ClickHouse. Here's a 10 minute quickstart to get you going:
