Choosing a primary key
We interchangeably use the term "ordering key" to refer to the "primary key" on this page. Strictly, these differ in ClickHouse, but for the purposes of this document, readers can use them interchangeably, with the ordering key referring to the columns specified in the table
ORDER BY.
Note that a ClickHouse primary key works very differently to those familiar with similar terms in OLTP databases such as Postgres.
Choosing an effective primary key in ClickHouse is crucial for query performance and storage efficiency. ClickHouse organizes data into parts, each containing its own sparse primary index. This index significantly speeds up queries by reducing the volume of data scanned. Additionally, because the primary key determines the physical order of data on disk, it directly impacts compression efficiency. Optimally ordered data compresses more effectively, which further enhances performance by reducing I/O.
- When selecting an ordering key, prioritize columns frequently used in query filters (i.e. the
WHEREclause), especially those that exclude large numbers of rows. - Columns highly correlated with other data in the table are also beneficial, as contiguous storage improves compression ratios and memory efficiency during
GROUP BYandORDER BYoperations.
Some simple rules can be applied to help choose an ordering key. The following can sometimes be in conflict, so consider these in order. You can identify a number of keys from this process, with 4-5 typically sufficient:
Ordering keys must be defined on table creation and can't be added. Additional ordering can be added to a table after (or before) data insertion through a feature known as projections. Be aware these result in data duplication. Further details here.
Example
Consider the following posts_unordered table. This contains a row per Stack Overflow post.
This table has no primary key - as indicated by ORDER BY tuple().
Suppose a user wishes to compute the number of questions submitted after 2024, with this representing their most common access pattern.
Note the number of rows and bytes read by this query. Without a primary key, queries must scan the entire dataset.
Using EXPLAIN indexes=1 confirms a full table scan due to lack of indexing.
Assume a table posts_ordered, containing the same data, is defined with an ORDER BY defined as (PostTypeId, toDate(CreationDate)) i.e.
PostTypeId has a cardinality of 8 and represents the logical choice for the first entry in our ordering key. Recognizing date granularity filtering is likely to be sufficient (it will still benefit datetime filters) so we use toDate(CreationDate) as the 2nd component of our key. This will also produce a smaller index as a date can be represented by 16 bits, speeding up filtering.
The following animation shows how an optimized sparse primary index is created for the Stack Overflow posts table. Instead of indexing individual rows, the index targets blocks of rows:

If the same query is repeated on a table with this ordering key:
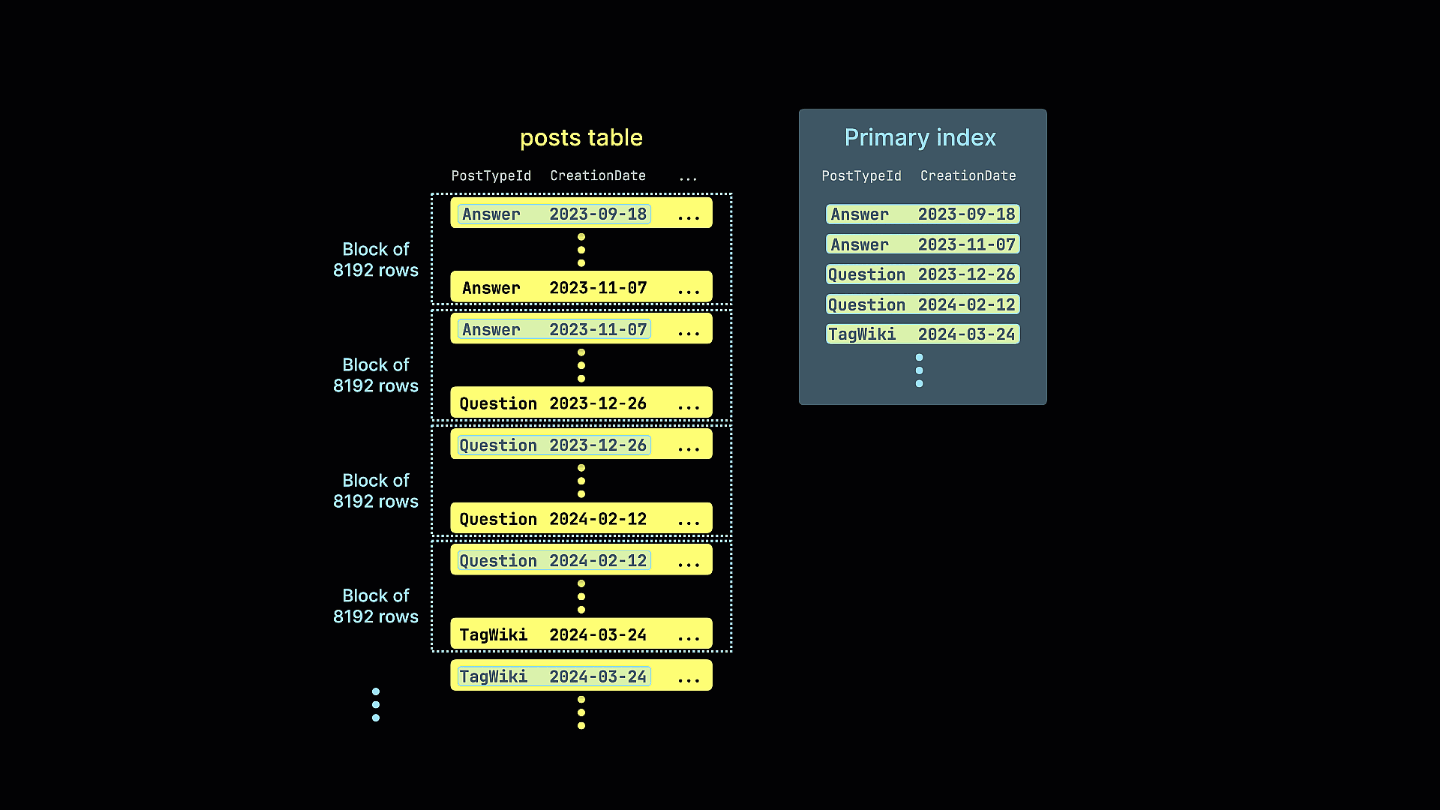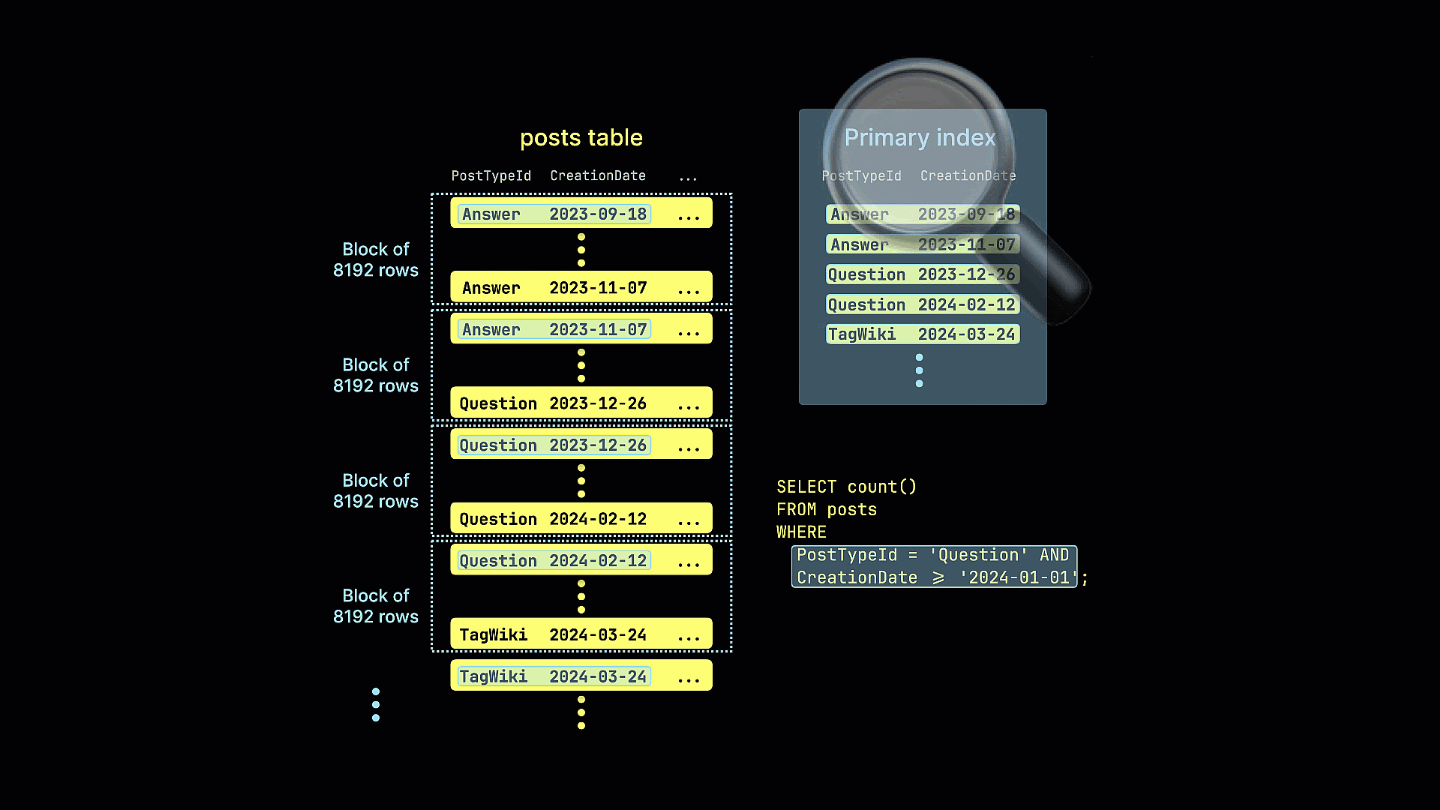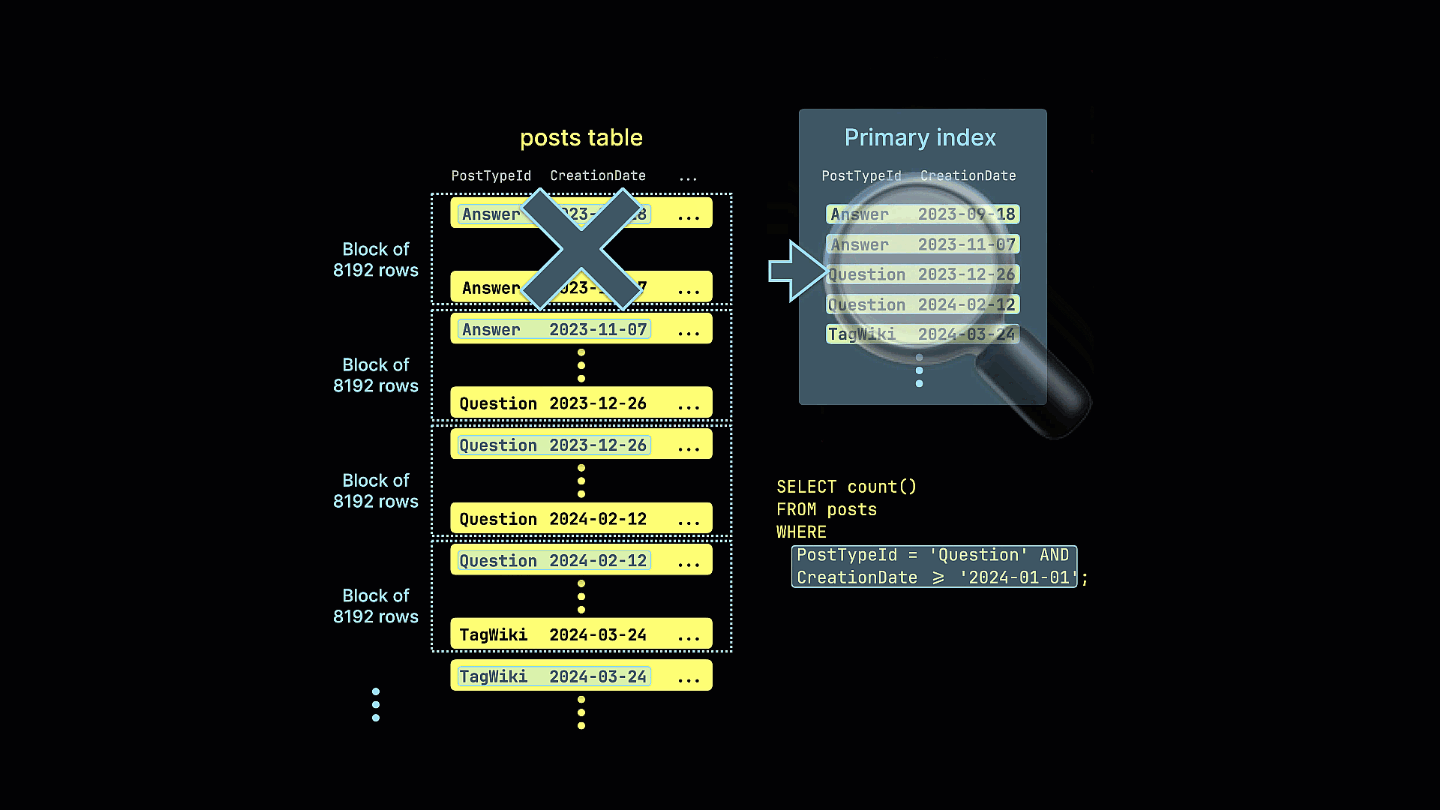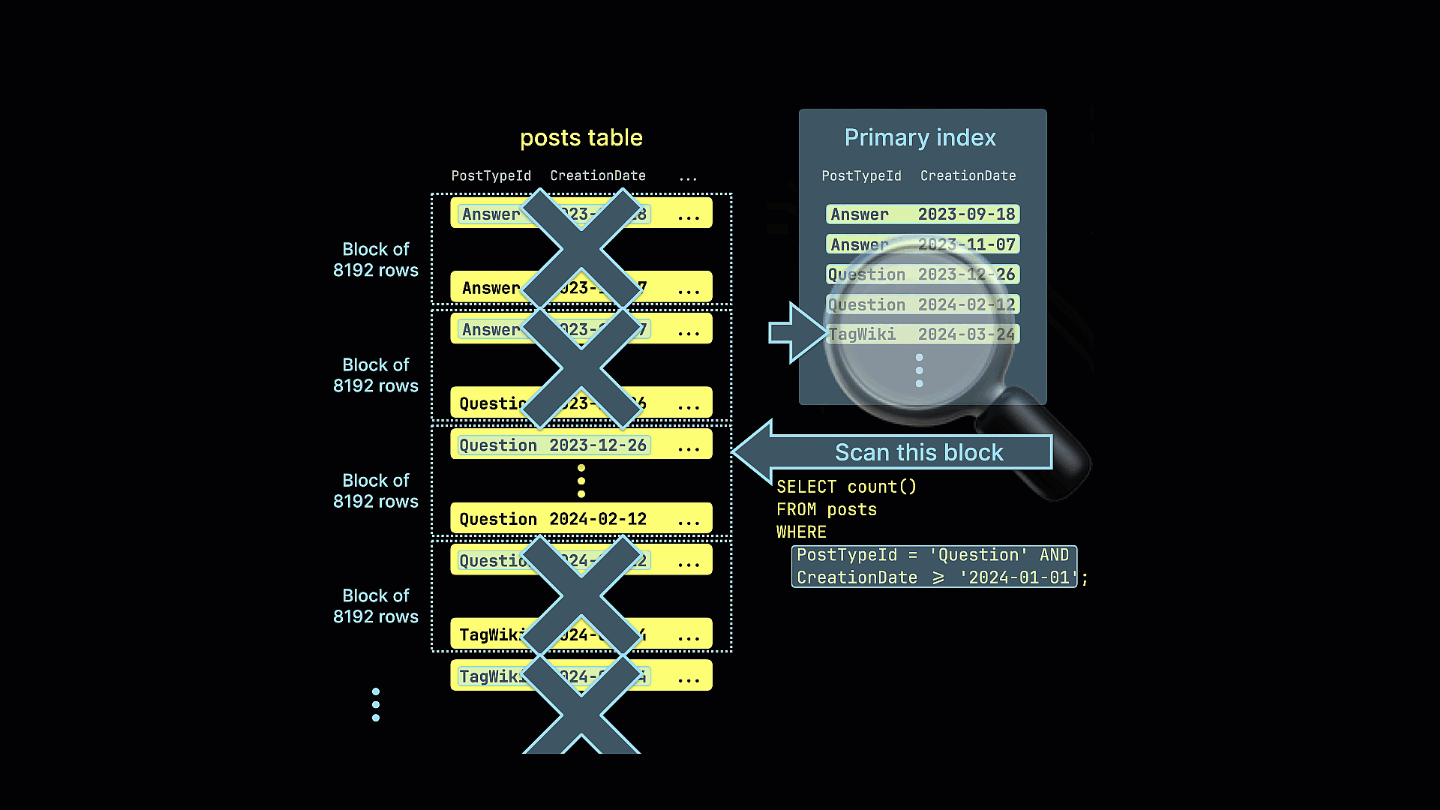
This query now leverages sparse indexing, significantly reducing the amount of data read and speeding up the execution time by 4x - note the reduction of rows and bytes read.
The use of the index can be confirmed with an EXPLAIN indexes=1.
Additionally, we visualize how the sparse index prunes all row blocks that can't possibly contain matches for our example query:
All columns in a table will be sorted based on the value of the specified ordering key, regardless of whether they're included in the key itself. For instance, if CreationDate is used as the key, the order of values in all other columns will correspond to the order of values in the CreationDate column. Multiple ordering keys can be specified - this will order with the same semantics as an ORDER BY clause in a SELECT query.
A complete advanced guide on choosing primary keys can be found here.
For deeper insights into how ordering keys improve compression and further optimize storage, explore the official guides on Compression in ClickHouse and Column Compression Codecs.
