Get started with ClickHouse Cloud today and receive $300 in credits. To learn more about our volume-based discounts, contact us or visit our pricing page.
Blog / Engineering
Announcing a New Official ClickHouse Kafka Connector
The ClickHouse Team
Jan 12, 2023

As a company rooted in open-source, we believe in giving our users the opportunity to collaborate and try new features. With this spirit, we announce the beta release of our open-source Kafka Connect Sink for ClickHouse and invite our community to start testing and providing feedback on the design and possible areas of improvement. Below we discuss the reasons for developing this connector and how we propose addressing the problem of exactly-once delivery semantics.
Apache Kafka is a ubiquitous open-source distributed event streaming platform that thousands of companies use for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
ClickHouse and Kafka are complementary, with users needing to insert Kafka-based data into ClickHouse for large-scale analytics. Existing solutions already exist for this problem, so let's dig into why we built another connector.
Why build another solution?
Before exploring the current ClickHouse-Kafka landscape, let’s remind ourselves what exactly-once delivery means, how this relates to the other options, and when each might be appropriate.
Delivery semantics
Apache Kafka supports three message delivery semantics, listed here in ascending order of implementation complexity:
- At-most-once: A message is delivered either one time only or not at all.
This scenario favors performance and throughput over data consistency by keeping the messaging overhead minimal. It can be suitable for large deployments of log and metrics collection, for example, in the IoT space. In that case, some conclusions can still be drawn from statistically significant observations, even if some events are missing. - At-least-once: A message can be delivered one or more times, with the guarantee that it will never be lost. This approach represents an interesting middle ground where the tolerance for duplicates reduces the operational complexity. The data store will then need to compensate on the query layer or by providing deduplication capabilities to ensure duplicates are not compromising business conclusions. This is by far the most common approach across many use cases like Observability.
- Exactly-once: A message will always be delivered only once. This approach is key for business-critical applications like financial analytics, where accuracy cannot be compromised and the receiving system cannot deduplicate. It comes with a significant operational overhead due to the necessity of keeping track of many moving components in order to be able to restore ingestion from partial states.
The ClickHouse - Kafka Landscape
ClickHouse has supported a number of techniques to achieve ingestion from Kafka, each with its own respective pros and cons.
The Kafka table engine provides a native ClickHouse integration and can be used to insert data into ClickHouse from Kafka and vice versa. As just another table engine, its architectural simplicity appeals to users getting started as no additional components are required. It does suffer from a few drawbacks, however. Debugging errors and introspecting current behavior can be challenging, although we plan to improve. Furthermore, it places additional load on your ClickHouse cluster and requires users to consider this in the context of regular insert and query load. Architecturally, we thus often see users wishing to separate these tasks. Most importantly, as a pull architecture, it requires your ClickHouse cluster to have bi-directional connectivity to Kafka - If there is a network separation, e.g., ClickHouse is in the Cloud and Kafka is self-managed, you may be hesitant to allow bidirectional connectivity for compliance and security reasons.
For those needing a push architecture and/or wanting to separate architectural concerns, Vector and Kafka Connect are also existing options.
Vector, using its Kafka input and ClickHouse output, is an excellent solution but is a focused Observability tool and not applicable to all use cases.
Kafka Connect is a free, open-source component of Apache Kafka that works as a centralized data hub for simple data integration between databases, key-value stores, search indexes, and file systems. This framework supports two types of connectors: sinks (from Kafka to destination) and sources (from a source to Kafka). For ClickHouse, the HTTP and JDBC connectors can be used to integrate with ClickHouse. These, again, present challenges. The JDBC connector is both a sink and source and is distributed under a community license. However, currently, there is no support for the ClickHouse dialect meaning it only works with basic ClickHouse types, e.g., Int32. Conversely, the HTTP Sink, through JSON and the ClickHouse HTTP interface, supports all types but is commercially licensed.
Most importantly, all of the above offer only at-least-once delivery at best.
Our approach
Ultimately, we want to offer our users a push-based connector with support for all ClickHouse types and exactly-once delivery semantics. Unfortunately, at-least-once delivery is typically a fundamental design decision in implementing a Kafka connector. While we could have solved some of the earlier challenges by enhancing an existing connector (e.g., adding dialect support to the JDBC sink), this would not have addressed the exactly-once requirement.
When faced with all of the above challenges, we decided to build a new connector. We needed to decide whether to create a separate component or use an existing framework. Given the prevalence of the Kafka Connect framework and its support in MSK and Confluent Cloud, both increasingly popular amongst our users, we decided to build a new connector for the Kafka Connect framework with first-class support for ClickHouse Cloud.
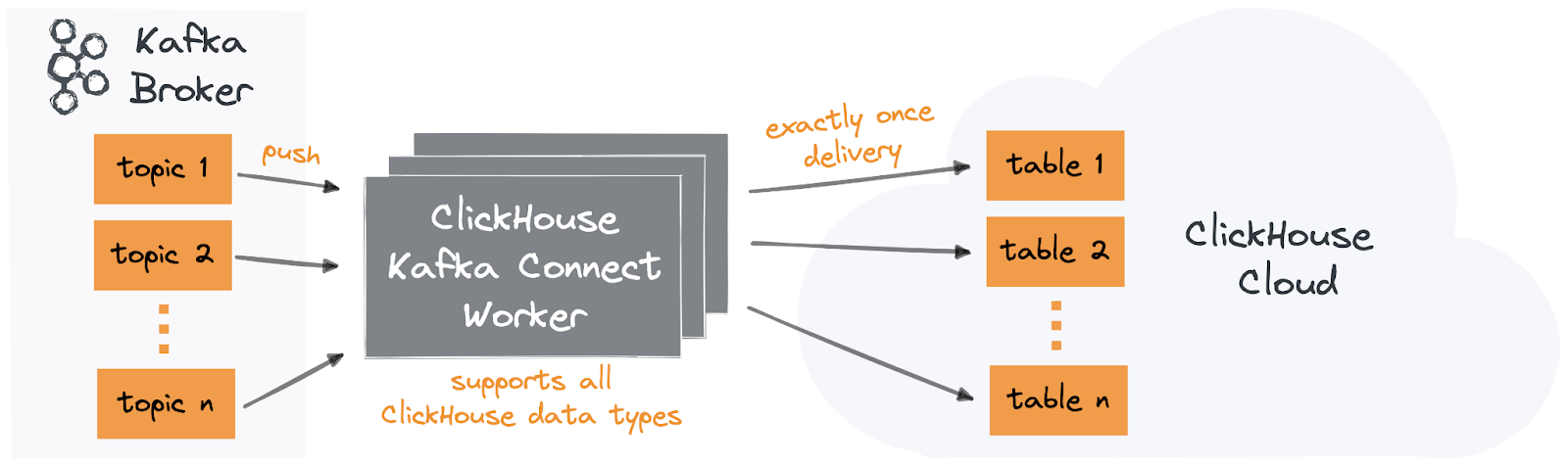
Of our requirements, implementing exactly-once delivery semantics presented the biggest challenge. Before we address how we propose achieving this, let's remind ourselves how at-least-once semantics can sometimes result in duplicates. These reasons are often connector specific but generally fall into two patterns, both related to how messages are consumed from Kafka and the means of tracking the current position (offset) on the queue of messages:
- A consumer processes a Kafka message, sending it to ClickHouse and committing the offset before crashing and losing it's in memory offset. Kafka, in this case, has been configured to auto-commit offsets (the default) but has not had a chance to perform the commit of the offset it received from the consumer (this is periodic). The consumer restarts, and as a result, it delivers messages from the last committed offset it has already consumed.
- The consumer uses the commit API (auto-commit is disabled) and takes responsibility for committing offsets in Kafka. It processes a Kafka message, sending it to ClickHouse, but crashes before committing the offset to Kafka. Once restarted, Kafka delivers messages from the last offset, causing duplicates to be sent to ClickHouse.
Note that these cases assume offsets are tracked within Kafka. The exact causes often depend on the integration, offset commit policy, and API used. Further reading here.
A common solution to the problem is to manage your offsets in your target data store. This can involve a number of approaches, often depending on the properties of the target data store. For example, the connector can commit the offsets with the messages if the datastore offers ACID transactions. A two-phased commit, using a different store for the offsets, might be viable without ACID transactions. Typically, these approaches incur an overhead and reduce throughput.
High-level design
When considering a solution, we wanted something that involved minimal dependencies, was architecturally simple, and exploited existing features of ClickHouse. Our full design can be found here. We welcome feedback as we increase testing and move to general availability.
In brief, our design for exactly-once delivery relies on exploiting the insert deduplication features of ClickHouse, ensuring we always formulate consistent batches for insert using a state machine and developing the connector using the Kafka Connect APIs such that we always receive duplicates in the event of failure. This approach enhances the at-least-once semantics of Kafka Connect by guaranteeing the deduplication of repeated records, thus achieving exactly-once delivery.
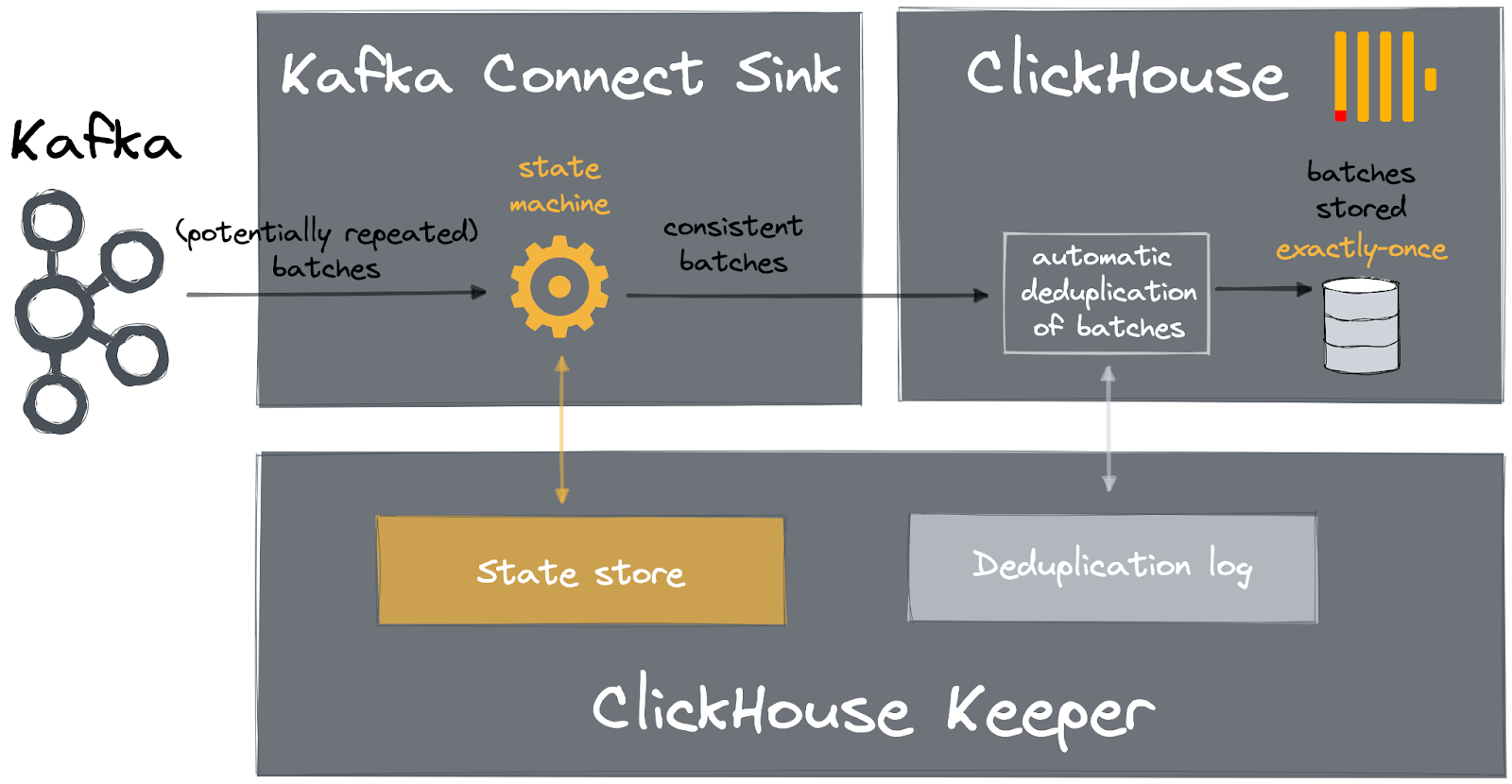
Using ClickHouse Keeper and a new table engine
ClickHouse Keeper provides strongly consistent storage for data associated with ClickHouse's cluster coordination system and is fundamental to allowing ClickHouse to function as a distributed system. This supports services such as data replication, distributed DDL query execution, leadership elections, and service discovery. ClickHouse Keeper is compatible with ZooKeeper, the legacy component used for this functionality in ClickHouse. Like Zookeeper, ClickHouse Keeper supports linearizability for writes and sequential consistency for reads. However, it has distinct advantages over Zookeeper, mainly compressed logs, lightweight installation, a smaller memory consumption (no JVM), and even optionally linearizability of reads. These properties are ideal for persisting small data quantities when highly consistent storage is required.
Our proposed connector design requires the connector to store state in a strongly consistent store with sequential consistency and linearizable writes. Initially, we considered ClickHouse but discounted this quickly for several reasons. Firstly, ClickHouse is not strongly consistent by default and offers only eventual consistent replication. With careful configuration, however, you can ensure linearizable inserts and sequential consistency for SELECTS for a replicated table. However, this ClickHouse configuration adds significant insert latency, principally because of the increased communication with ClickHouse Keeper to coordinate the write and subsequent data replication. This design effectively adds a redundant component and unnecessary overhead - the ClickHouse table storage. Given we only need to store minimal state, using ClickHouse Keeper directly seemed the perfect solution to address these requirements.
The challenge with this approach is that this component is typically not exposed in a cluster. For example, it's not exposed in ClickHouse Cloud, and its access and use should be carefully controlled not to impact cluster operations and stability. Working with the ClickHouse core team, we decided to expose ClickHouse Keeper (for cases where linearizable inserts and sequential consistency are required) in a controlled way through a table engine - the KeeperMap engine. This provides us with an integrated and lightweight means of storing our state.
Note that you can test the connector without KeeperMap using an in-memory mode. This is for testing only and makes no exactly-once guarantees in the event of failure.
What’s Next?
Over the coming months, we plan to test the connector extensively under various failure scenarios. Once we have confidence in the design and implementation and gathered feedback from you, our users, the connector will be made generally available.
Despite being beta, the connector is already feature-rich, supporting most ClickHouse types (including Arrays and Maps) and allowing data to be inserted with or without a schema. In the case of no schema, data is first converted to JSON prior to insertion. We use the RowBinary format for optimal performance for data with a schema. Both approaches use the ClickHouse HTTP interface, and we continuously test against ClickHouse Cloud.
Finally, as well as some current limitations, we plan to add support for deletes, allowing Redis to be used as a state store and the JSON type.
Conclusion
In this blog post, we have explored how and why we built a new Kafka connector for ClickHouse. We have explained our proposed approach to achieve exactly-once delivery semantics and how this overcomes the limitations of existing solutions. Try the new connector, and we welcome feedback!
Get started with ClickHouse Cloud today and receive $300 in credits. At the end of your 30-day trial, continue with a pay-as-you-go plan, or contact us to learn more about our volume-based discounts. Visit our pricing page for details.
Share this post
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!
Loading form...


Follow us
Comparisons
Stay informed on feature releases, product roadmap, support, and cloud offerings!
Loading form...
© 2024 ClickHouse, Inc. HQ in the Bay Area, CA and Amsterdam, NL.