We’d like to welcome Marijan Ralasic, Data Architect at Superology, as a guest to our blog. Read on to find out how Superology is using ClickHouse alongside Kafka to power customer quantitative data.
Superology is an experienced product tech company. Since 2012, we have been innovating in the sports betting industry. Being acquired by Superbet group in 2017, we became one of the leading forces in the industry. Today, our platforms are used by hundreds of thousands of people and process millions of transactions daily. To satisfy user needs and accomplish business goals, we use a data-informed approach at every level of work.
We value personal growth as much as we value company growth. That’s why we don’t follow the traditional corporate model but empower our people to deploy their talents and own their work end-to-end.
Collecting customer quantitative data
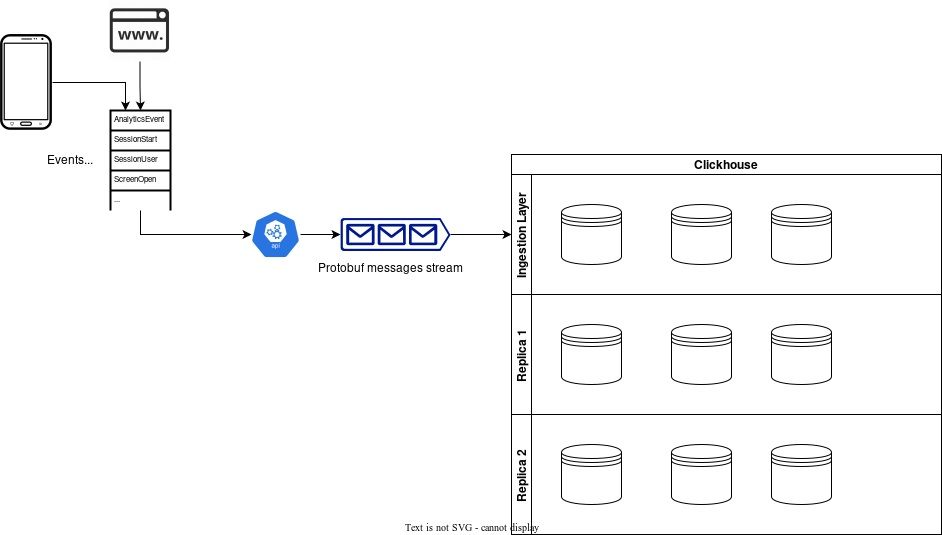
Quantitative data is something that businesses can easily count or measure, concrete and unbiased data points. Superology uses quantitative data to create reports, analyze it using statistical tools, and create randomized experimentation processes. Quantitative data from the Superology perspective includes metrics such as counting the number of app or site visits, customer clicks on specific pages, number of comments and followers in our social section, and various conversion events and bounce rates. We use this data to modify our customer experience to increase the satisfaction and usefulness of our application. We want to achieve the best experience for people wanting to find sports statistics, engage in social actions and overall enjoy the sports entertainment industry.
Google protobuf
To collect this data we are using Google protocol buffers. Protocol Buffers (Protobuf) is a free and open-source cross-platform data format used to serialize structured data. The method involves an interface description language that describes the structure of some data and a program that generates source code from that description for generating or parsing a stream of bytes that represents the structured data. Since the data we collect can vary in structure, we decided to use oneof fields to handle dynamic properties and specify that only one of a range of fields can be set in a message. Our data is serialized in batches, so a single protobuf message can contain various events and event types. Here is an example of the proto scheme we use.
syntax = "proto3";
import "google/protobuf/wrappers.proto";
// This is base event for analytics
message BaseMessage {
string id = 1;
oneof Events {
Event1 event_1 = 101;
Event2 event_2 = 201;
Event3_SubEvent1 event_subevent_1 = 301;
Event3_SubEvent2 event_subevent_2 = 302;
…
Event4 event_4 = 401;
…
};
string event_type = 3;
string session_id = 4;
bool gdpr_accepted = 5;
}
message Event1 {
}
message Event2 {
bool property1 = 1;
}
message Event3_SubEvent1 {
string property1 = 1;
string property2 = 2;
…
}
message Event3_SubEvent2 {
string property1 = 1;
string property2 = 2;
…
}
message Event4 {
google.protobuf.FloatValue property1 = 1;
}
}
ClickHouse Kafka Engine and Protocol Buffers
ClickHouse has a built-in Kafka connector, the Kafka engine, and one of the input types ClickHouse has implemented is Protobuf. This format requires an external format schema and bear in mind the schema is cached between queries. Using the given protobuf schema, ClickHouse tracks the delivered messages automatically, so each message in a group is only counted once. Fast and reliable was the solution we were looking for and ClickHouse had delivered. Our ClickHouse implementation allows us to scale it easily horizontally and vertically. Each message produced is ingested to our “big” origin table, and here the ClickHouse columnar structure offers us great extensibility. Since the data is susceptible to changes, we do allow changes on our proto scheme, however, we only allow adding new fields and extending our proto scheme. This way we are certain we will always be backward compatible. Adding columns/fields to our origin table is incredibly easy using ALTER TABLE and ADD COLUMN clauses. If we want to stop using a certain property, we deprecate the corresponding field in the protoscheme and comment the column is deprecated in our origin table. This way we keep historical data intact, and the ingestion continues as usual. The data is kept on our disks for a certain amount of time before sending it to S3 using tiered storage.
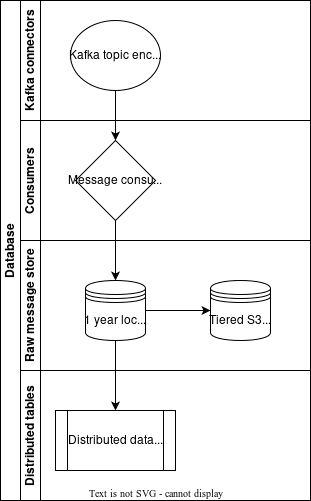
Filtering and transforming our data
The origin table is extended further using materialized view, and filtering out the data we really want to analyze. We are filtering data using events defined in our one of fields, hence enabling us the view to only a certain aspect of our customer behavior, ie page clicks. Using the filtering option we are keeping the retractability of the certain event or stream message giving us more debugging and deep-dive analysis options. Lastly, we transform our data per our requirements, enabling different points of view such as funnel analysis and categorization of our customers. The ultimate transformation is the aggregating view of specific actions that will end up as some value on our reporting dashboards.
Experiments
We do not use the data only for the reports, we run extensive research on it. ClickHouse has helped us a lot in managing AB testing and other experiments, not only with their built-in statistics functions such as welchTTest, mannWhitneyUTest, and other useful functions, not also by enabling us easier and more efficient AB testing by exploiting ClickHouse architecture. We are often using Bayesian A/B Testing approach to make our business decisions. These methods are more computationally expensive than traditional approaches, but ClickHouse with its extensive set of statistical functions has allowed us to create a workflow that enables us to make fast, explainable and accurate decisions.
Future
We plan to enrich the ClickHouse architecture by coupling it with MindsDB, which will allow us to create a Machine learning architecture on the database level. Also, we plan to push the ClickHouse transformations back to Kafka streams enabling us to use the data in the downstream applications and enriching other data streams. We are looking forward for the new features coming up such as JSON data type, and we hope to have a long-lasting and successful relationship with ClickHouse Inc.